안녕하세요. 마인즈앤컴퍼니입니다.
오늘은 MLOps에 대한 핵심 요소와 구성 컴포넌트, 아키텍처에 대해 잘 정리된 논문이 있어서 소개해 드리려고 합니다.
“Machine Learning Operations (MLOps): Overview, Definition, and Architecture” 라는 제목의 논문이며 2022년도에 arXiv에서 퍼블리싱 했습니다.
https://arxiv.org/ftp/arxiv/papers/2205/2205.02302.pdf
본 글을 통해 머릿속에 추상적으로 머물러 있던 MLOps의 개념이 어느정도 실체화 될 수 있을거라고 생각합니다.
MLOps의 핵심 요소와 컴포넌트 그리고 end-to-end 아키텍처
작성: 마인즈앤컴퍼니 함명호 상무
ML은 데이터의 기반하여 비즈니스를 더욱 혁신 시킬수 있는 중요한 기술이 되었습니다. 그러나 실제로는 많은 ML 어플리케이션들이 프로덕션 환경에서 기대에 미치지 못하는 성과를 내고 있는것이 현실입니다. 실패의 이유중 하나를 꼽자면 대부분의 포커스가 ML 모델에 집중되어 있는 반면, 프로덕션에 어떻게 배포하고, 모니터링을 어떻게 하며, 성능 변화가 있을때 ML 모델을 어떻게 재학습을 해서 재배포를 할지에 대한 고려가 부족하기 때문입니다. 예를 들어, 지금도 대다수의 기업들에서는 데이터 과학자에 의해 ML 워크플로가 수작업으로 관리되고 있고, 결과적으로 ML 어플리케이션의 운영과정에서 많은 이슈를 만들어 내고 있습니다.
위와 같은 문제점들을 해결하기 위해 MLOps가 만들어지게 되었고, 현장에서도 도입하는 사례가 늘어나게 되었습니다. 그러나 대부분의 논문들은 MLOps의 특정 부분에 대해서만 소개를 하고있고, MLOps의 전체적인 컨셉, 일반화 원칙, ML 시스템 아키텍처의 명확한 정의가 없다고 본 논문에서 주장하고 있습니다.
본 논문에서는 27개의 논문 리뷰와 산업, 국가, 인종, 성별이 다른 8명의 전문가 인터뷰, 많은 상용화 MLOps 플랫폼과 서비스를 리뷰한 결과를 토대로 MLOps의 개념을 정리해 나가기 시작합니다.
DevOps에 대하여
DevOps는 2008~2009년 사이에 생겨난 컨셉이며, 소프트웨어 개발과 운영 사이의 갭을 없애서 조직간 협업, 소통, 지식 공유를 원활히 할 수 있도록 돕습니다. 기능적으로 DevOps는 CI(Continuous Integration), CD(Continuous Deployment)를 자동화해서 보다 빠르고 빈번한 배포를 안정적으로 수행하게 돕는 역할도 합니다. 또, 지속적인 테스팅, 모니터링, 로깅, 피드백 루프를 지원하기도 합니다.
기능에 따라 DevOps 툴은 목적에 따라 크게 6개의 카테고리로 나눌수 있고, 각 카테고리에 해당 하는 툴들의 예는 아래와 같습니다.
- 협업, 지식공유: Slack, Trello, GitLab wiki 등- 빌드: Maven 등- 배포 자동화: Kubernetes, Docker 등
- 모니터링, 로깅: Prometheus, Logstash 등
- CI: Jenkins, GitLab CI 등
- 소스코드 관리: GitHub, GitLab 등
DevOps를 통해 보다 효율적이고, 품질이 좋은 소프트웨어의 개발과 운영이 가능해 졌고, 이런 자동화와 운영 방법론 등은 그대로 ML 분야에도 이식이 되기 시작했는데, 이를 MLOps라고 부릅니다.
MLOps의 핵심 요소
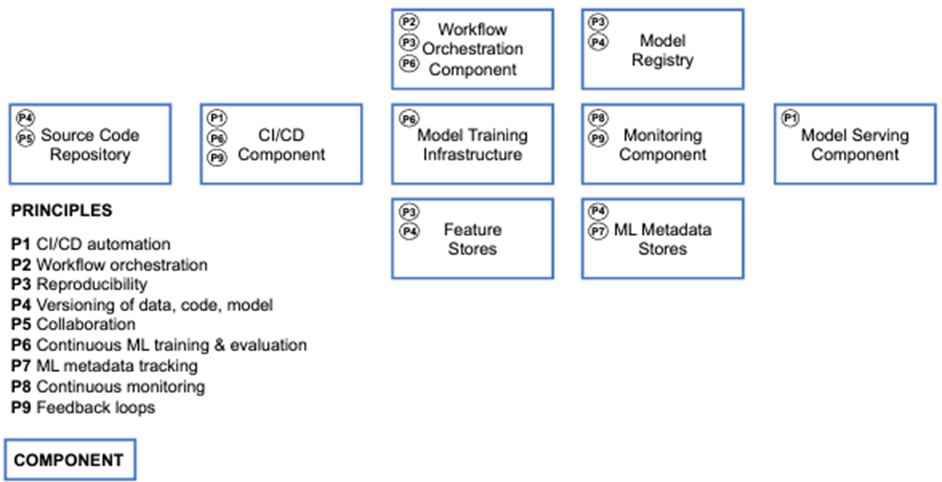
본 논문에서는 MLOps를 실현화하기 위해 반드시 필요한 9개의 핵심 요소들을 정의하고 각각에 대해 설명을 하고 있습니다.
아래 그림은 핵심 요소 9개와 핵심 요소들을 포함하는 9개의 기술적 컴포넌트를 나타내고 있습니다.
그럼 본 논문에서 제안하는 9개의 MLOps 핵심 요소에 대해 살펴보겠습니다.
P1 CI/CD automation
CI/CD를 통한 빌드, 테스트, 배포 단계의 자동화와 특정 단계의 성공, 실패 여부의 빠른 피드백으로 전체 프로세스의 생산성을 향상 시킵니다.
P2 Workflow orchestration
워크플로 오케스트레이션은 DAGs(Directed Acyclic Graphs)로 구성되는 ML 워크플로 파이프라인의 테스크들을 조율하는 역할을 합니다. DAGs는 의존적인 관계를 고려한 ML 워크플로의 테스크 실행 순서를 정의할 수 있습니다.
P3 Reproducibility
재현성은 ML 실험을 재현하고 항상 동일한 성능을 보장을 해주는 기능입니다.
P4 Versioning
버전닝은 데이터, 모델, 코드의 버전닝을 지원해서 재현성(reproducibility)과 추적성(traceability)을 보장해 주는 역할을 합니다.
P5 Collaboration
협동성은 데이터, 모델, 코드 중심으로 효과적인 협업이 가능하게 돕습니다. 기술적인 측면을 넘어서 서로 다른 도메인에 있는 조직간의 효율적인 협업과 커뮤니케이션을 돕는 문화를 포함한 개념이기도 합니다.
P6 Continuous ML training & evaluation
지속적 학습은 새로운 데이터 피처를 기반으로 주기적인 ML 모델의 재학습을 수행하는것을 의미합니다. 지속적 학습은 모니터링 컴포넌트, 피드백 루프, 자동화된 ML 워크플로 파이프라인에 의해 트리거 될수 있습니다. 또, 재학습된 모델의 품질 변화를 평가하기 위한 과정도 포함이 됩니다.
P7 ML metadata tracking/logging
메타데이터는 ML 워크플로 테스크를 수행함에 따라 트래킹, 로깅 됩니다. 특히 학습중 실험 성능 추적을 위해 학습 시간, 모델 하이퍼파라미터, 성능 메트릭스, 데이터, 코드의 버전 등이 트래킹, 로깅 됩니다.
P8 Continuous monitoring
지속적 모니터링은 잠재적인 오류나 제품 성능에 영향을 미치는 변화를 감지하기 위해 데이터, 모델, 코드, 인프라 리소스, 모델 성능 등을 주기적으로 감시하는 역할을 합니다.
P9 Feedback loops
피드백 루프는 피처 엔지니어링 단계에서 모델 실험 단계 사이에서 인사이트를 주기 위한 역할을 수행하기도 하고, 모니터링 컴포넌트와 연동을 해서 재학습을 트리거 하는 기능을 하기도 합니다.
MLOps의 기술적 컴포넌트
MLOps 시스템 디자인시 고려해야 할 컴포넌트와 각각의 컴포넌트들이 포함해야 할 핵심 요소들에 대한 설명입니다. 각 컴포넌트 이름 뒤의 괄호안에는 해당 컴포넌트가 담고 있는 MLOps 핵심 요소들을 나열했습니다.
C1 CI/CD Component(P1, P6, P9)
CI/CD 컴포넌트는 지속적 통합과 지속적 배포의 기능을 수행합니다. 빌드, 테스트, 배포 과정에 관여를 하고, 생산성을 증가시키기 위해 각 과정마다 성공, 실패 유무를 피드백 해주는 기능을 수행하기도 합니다.
이런 기능을 도와주는 툴의 예로 Jenkins, GitHub actions 등이 있습니다.
C2 Source Code Repository(P4, P5)
소스코드 리포지토리는 코드와 버전닝 정보를 저장하기 위한 용도로 사용됩니다. 많은 개발자들이 자신의 코드를 커밋하고 머지하는 기능을 제공합니다.
해당 기능의 툴인 Bitbucket, GitLab, GitHub, Gitea 등이 있습니다.
C3 Workflow Orchestration Component(P2, P3, P6)
워크플로 오케스트레이션 컴포넌트는 DAGs를 통해 만들어진 ML 워크플로의 테스크들을 조율하는 기능을 합니다. DAGs로부터 생성되는 그래프는 워크플로 내의 테스크들의 실행 순서를 표현하는 역할을 합니다.
툴의 예로는 Apache Airflow, Kubeflow Pipelines, Luigi, AWS SageMaker Pipelines, Azure Pipelines 등이 있습니다.
C4 Feature Store System(P3, P4)
피처 스토어 시스템은 공통적으로 사용되는 피처들을 관리하기 위한 저장소입니다. 보통 2개의 데이터베이스로 구성이 되는데, 하나는 오프라인 피처 스토어이고, 두번째는 온라인 피처 스토어 입니다. 오프라인 피처 스토어는 주로 실험을 위한 피처를 관리하고, 온라인 피처 스토어는 프로덕션 환경에서 예측을 위한 피처를 관리하며, 보다 낮은 지연시간(low latency)을 보장해야 합니다.
해당 시스템의 예로는 Google Feast, Amazon AWS Feature Store, Tecton.ai, Hopswork.ai 등이 있습니다.
C5 Model Training Infrastructure(P6)
모델 학습 인프라스트럭처는 CPU, RAM, GPU등과 같이 기본적인 계산 자원(computation resources)을 제공합니다. 인프라는 분산 또는 중앙 집중형의 형태가 될수 있지만, 일반적으로 확장성 있는 분산형 형태의 인프라스트럭처가 많이 쓰입니다.
예를들어 확장성이 없는 로컬 머신이 쓰일수도 있고, 클라우드 기반 인프라를 사용하기도 합니다. 인프라스트럭처 위에서 MSA(Micro Service Architecture)기반 소프트웨어 개발을 위해 Kubernetes, Red Hat OpenShift 등의 프레임워크를 사용할 수 있습니다.
C6 Model Registry(P3, P4)
모델 레지스트리는 학습 ML 모델과 메타데이터를 저장하기 위한 저장소입니다.
MLflow, AWS SageMaker Model Registry, Microsoft Azure ML Model Registry, Neptune.ai등의 고도화된 형태의 레지스트리가 있고, Microsoft Azure Storage, Google Cloud Storage, Amazon AWS S3등 단순한 형태의 저장소를 이용할 수도 있습니다.
C7 ML Metadata Stores(P4, P7)
ML 메타데이터 스토어는 ML 워크플로 파이프라인의 테스크들을 수행하면서 생성되는 다양한 종류의 메타데이터를 저장합니다. 메타데이터 스토어는 모델 레지스트리와 연동해서 구성할수도 있는데, 학습 과정에서 생성되는 메타데이터를 저장하고, 실험 관리를 위한 트레킹, 로깅 등에 활용할 수 있습니다.
Kubeflow Pipelines, AWS SageMaker Pipelines, Azure ML, IBM Watson Studio등이 메타데이터 스토어를 제공하고 있고, MLflow가 모델 레지스트리와 연동해 고도화된 기능을 제공합니다.
C8 Model Serving Component(P1)
모델 서빙 컴포넌트는 모델을 배포해서 서비스 가능한 형태로 만들어 주는 기능을 수행합니다. 목적에 따라 실시간 추론(inference) 방법을 제공하거나, 대용량 데이터를 이용한 배치(batch) 형태의 추론 방법을 제공하기도 합니다. 또, 서빙을 위해 REST API를 제공할 수도 있습니다. 인프라스트럭처는 확장 가능한 분산 형태의 모델 서빙 환경이 많이 쓰이고, Kubernetes와 Docker 기반으로 ML 모델을 컨테이너화하고, Python 웹어플리케이션 프레임워크인 Flask를 연동해서 서빙 API를 제공 하기도 합니다.
Kubernetes를 지원하는 서빙 프레임워크는 Kubeflow KServing, TensorFlow Serving, Seldion.io serving등이 있습니다. 배치 추론을 위해서 Apache Spark가 사용되기도 합니다. 모델 서빙을 지원하는 클라우드 서비스로는 Microsoft Azure ML REST API, AWS SageMaker Endpoints, IBM Watson Studio, Google Vertex AI prediction servce 등이 있습니다.
C9 Monitoring Component(P8, P9)
모니터링 컴포넌트는 지속적으로 모델의 성능을 모니터링하는 역할을 수행합니다. 추가적으로 모델의 성능 뿐만 아니라 ML 인프라스트럭처, CI/CD, pipeline등이 모니터링의 대상이 됩니다.
모니터링 툴의 예로는 Prometheus, ELK stack(Elasticsearch, Logstash and Kibana), 간단하게는 TensorBoard 등이 있습니다. 또, Kubeflow, MLflow, AWS SageMaker등은 빌트인 모니터링 기능을 내장하고 있습니다.
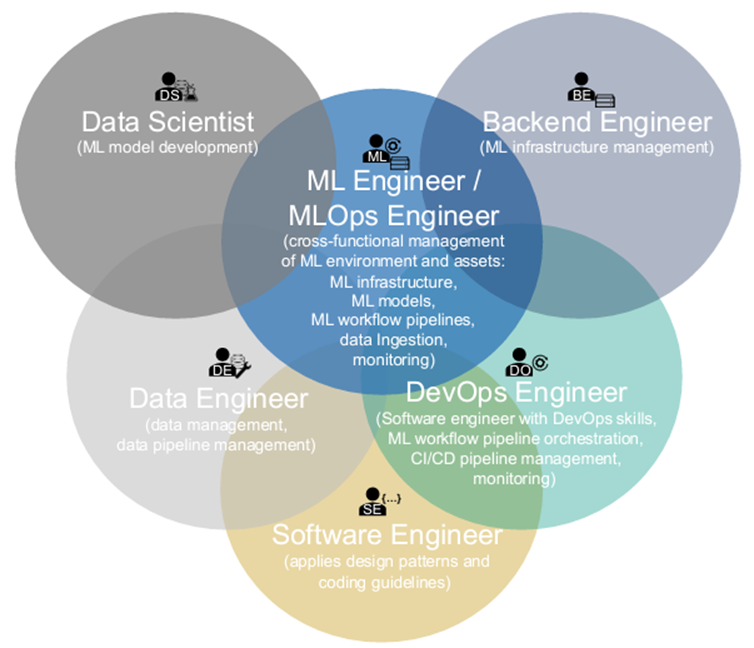
MLOps를 사용하는 구성원들
MLOps는 각기 다른 학문 분야의 그룹들과 서로 다른 역할을 가진 구성원들의 공통 목표인 ML 어플리케이션의 상품화를 위해 개발, 관리, 자동화, 운영 등을 돕는 역할을 수행합니다. 이번에는 서로 다른 역할을 하는 구성원과 테스크에 대해서 설명하겠습니다.
R1 Business Stakeholder(Product Owner, Project Manager)
비즈니스 스테이크홀더는 ML으로 성취할 수 있는 비즈니스 목표를 정의하고, 비즈니스와 관련된 대내외의 커뮤니케이션 활동을 합니다.
R2 Solution Architect(IT Architect)
솔루션 아키텍트는 사용할 기술적인 요소들에 대한 정하고, 아키텍처를 설계 합니다.
R3 Data Scientist(ML Specialist, ML Developer)
데이터 과학자는 비즈니스 문제를 ML 문제로 재정의하고, 최적의 성능을 낼수 있는 알고리즘과 하이퍼파라미터의 선택과 관련된 모델링 업무를 수행합니다.
R4 Data Engineer(DataOps Engineer)
데이터 엔지니어는 학습에 사용할 데이터를 준비하고, 피처 엔지니어링 파이프라인을 만들고 관리 합니다. 특히, 적합한 데이터가 피처 스토어 시스템의 데이터베이스에 적재될 수 있도록 해야 합니다.
R5 Software Engineer
소프트웨어 엔지니어는 ML 도메인의 문제를 잘 엔지니어링된 상품 레벨로 올리기 위한 노력을 합니다. 부가적인 알고리즘의 개발, 코딩 가이드라인을 준수하고, 재사용 가능하고 효율적인 구조의 디자인 패턴을 적용하는 등의 활동을 합니다.
R6 DevOps Engineer
DevOps 엔지니어는 개발과 운영사이에서 발생하는 갭을 메우기 위한 다리 역할을 합니다. DevOps 엔지니어는 CI/CD 자동화, ML 워크플로 오케스트레이션, 모델 배포와 모니터링이 원활히 수행되도록 해야 합니다.
R7 ML Engineer/MLOps Engineer
ML 엔지니어 혹은 MLOps 엔지니어는 여러 중첩된 영역의 역할을 수행하기 때문에 ML과 SW 엔지니어링의 도메인 지식을 동시에 갖고 있어야 합니다. 주요 역할로는 ML 인프라스트럭처의 빌드와 운영, 자동화된 ML 워크플로 파이프라인과 모델 배포 관리, 모델과 ML 인프라스트럭처의 모니터링 등이 있습니다.
아래 그림은 구성원들의 역할과 구성원들간의 중첩된 역할들을 보여주고 있습니다.
MLOps 아키텍처와 워크플로
앞서 설명드린 MLOps의 핵심요소, 컴포넌트, 구성원들을 기반으로 아래 그림과 같이 MLOps end-to-end 아키텍처를 일반화 시켰습니다. 아키텍처는 특정 기술에 의존한 형태로 작성되지 않았고, 일부 프로젝트를 진행함에 따라 수행해야 할 프로세스도 포함하고 있습니다.
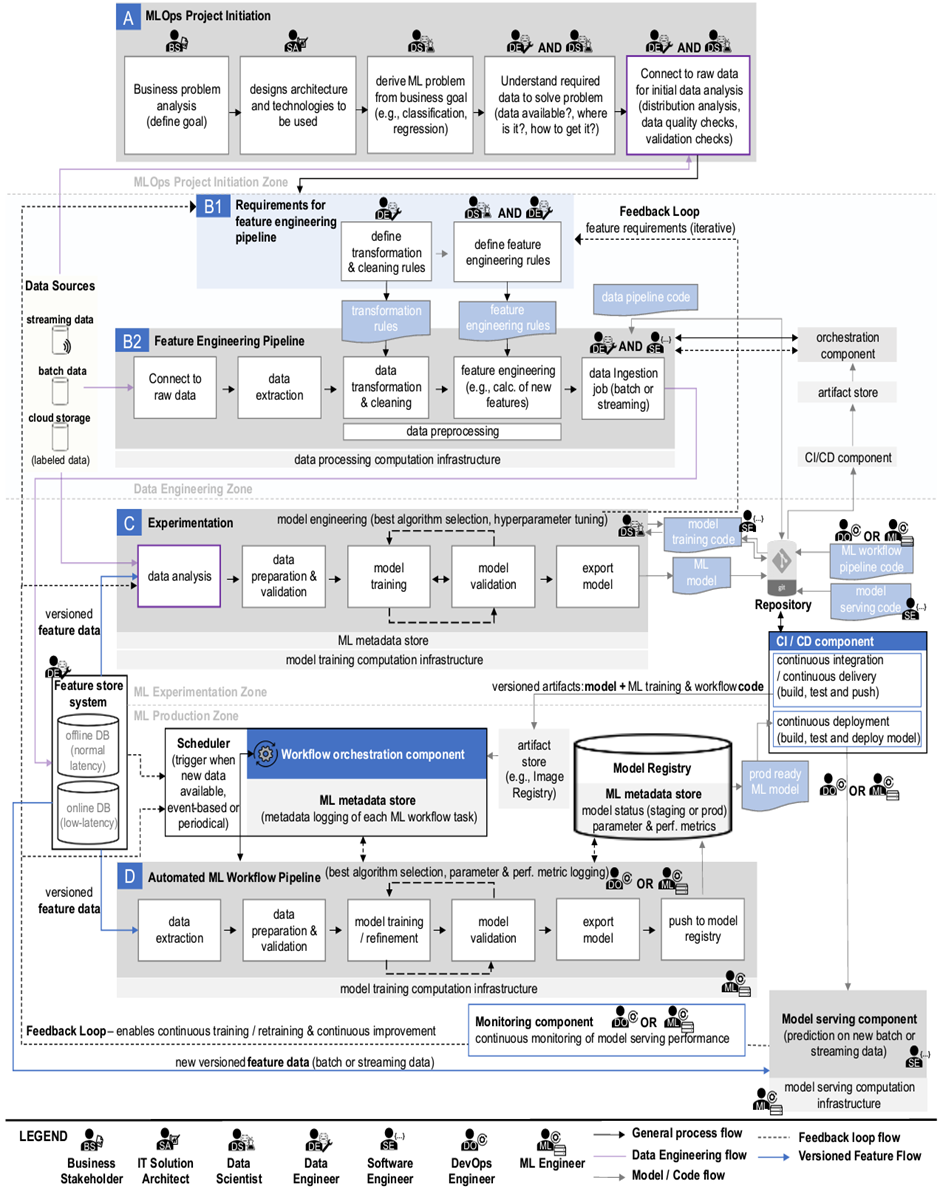
그럼 아키텍처의 상세 설명을 보도록 하겠습니다.
(A) MLOps project initiation
ML 프로젝트 초기 셋업 단계의 프로세스에 대한 설명 입니다.
1) Business problem analysis
비즈니스 스테이크홀더(R1)는 비즈니스 계획을 수립하고, ML로 풀수 있는 비즈니스 문제를 정의 합니다.
2) Architercture design
솔루션 아키텍트(R2)는 전체적인 ML 시스템의 아키텍처 디자인을 정의하고, 아키텍처 평가를 통해 적절한 기술 스택을 결정 합니다.
3) Define ML problem from business goal
데이터 과학자(R3)는 비즈니스 목표를 ML 문제로 재정의 합니다.
4) Data survey & selection
데이터 엔지니어(R4)와 데이터 과학자(R3)는 협업을 통해 어떤 데이터가 문제를 풀기 위해 적합한지 조사를 하고, 데이터를 선정 합니다.
5) Data analysis
데이터 엔지니어(R4)와 데이터 과학자(R3)는 선정된 데이터로부터 분포, 품질 등을 분석해 적합한 데이터인지 판별 합니다.
(B1) Requirements for feature engineering pipeline
피처는 모델을 학습하기 위해 필요한 데이터의 속성을 말합니다. 5)의 과정을 통한 데이터 분석으로 기본적인 피처 엔지니어링 파이프라인을 위한 요구조건들이 정의가 됩니다.
6) Define data transformation & cleaning rule
데이터 엔지니어(R4)는 데이터 변환(transformation) 규칙(예, normalization, aggregations)들을 정의하고, 데이터를 학습하기 적합한 형태로 정리(cleaning)하기 위한 룰들도 정의합니다.
7) Define feature engineering rule
데이터 과학자(R3)와 데이터 엔지니어(R4)는 피처 엔지니어링을 위한 규칙들을 정의 합니다. 이런 규칙들은 개발단계의 모델 실험 또는 배포된 모델의 성능 모니터링 결과의 분석을 통해 반복적으로 조정되어야 합니다.
(B2) Feature engineering pipeline
위의 과정으로 정의된 규칙들은 피처 엔지니어링 파이프라인을 만들기 위한 프로토타입으로 사용됩니다.
8) Connect to raw data
데이터 엔지니어(R4)는 피처 엔지니어링 테스크를 정의하고 데이터 파이프라인을 구축해서 데이터 소스에 연결합니다.
데이터 소스의 형태는 스트리밍 데이터 일수도 있고, 배치 데이터 또는 클라우드 스토리지에 있는 데이터 일수도 있습니다.
9) data extraction
데이터 소스에 연결된 데이터를 추출 하는 과정입니다.
10) Data transformation & cleaning
6)에서 정의된 데이터 변환(transformation), 정리(cleaning) 규칙을 수행합니다. 이 과정의 주 목적은 학습할수 있는 포맷의 데이터를 만드는 것입니다.
11) feature engineering
7)에서 정의된 피처 엔지니어링 규칙에 따라 피처 엔지니어링을 수행합니다. 피처 엔지니어링에서 수행하는 일의 예로는 결측값(missing value) 처리, 이상값(outlier) 처리, 비닝(binning), 레이블 인코딩(label encoding), 원-핫 인코딩(one-hot encoding) 등이 있습니다.
12) Data Ingestion
마지막으로 피처 엔지니어링 완료된 데이터를 피처 스토어 시스템(feature store system)에 적재 합니다.
(C) Experimentation
이번 실험 단계에서의 대부분의 테스크는 데이터 과학자(data scientist)에 의해 수행 되고, 소프트웨어 엔지니어(R5)가 데이터 과학자를 지원 합니다.
13) Data analysis
데이터 과학자는 피처 스토어 시스템에 연결해 데이터를 분석 합니다. 또는, 보다 초기적인 분석을 위해 원시 데이터(raw data)를 이용하기도 합니다. 어떤 경우이든 데이터에 변경이 필요한 경우 피처 엔지니어링 파이프라인의 변경이 필요하므로, 데이터 엔지니어와의 커뮤니케이션이 필요합니다.
14) Data preparation & validation
학습을 하기 위해 데이터를 최종적으로 준비하고, 검증하는 단계이며, 학습, 테스트, 검증등의 데이터셋을 분리하는 일도 이 단계에서 수행 됩니다.
15) Model training
데이터 과학자는 모델의 알고리즘을 개발하고, 하이퍼파라미터 등의 조정을 하며 모델을 학습 시킵니다. 소프트웨어 엔지니어가 모델의 학습 코드를 잘 디자인된 코드로 고도화하기 위해 도움을 주기도 합니다.
16) Model validation
이번 모델 평가 단계와 15) 모델 학습은 모델의 하이퍼파라미터 튜닝과 모델 알고리즘의 변경을 통해 최적화된 모델 성능이 나올때까지 반복 수행 됩니다.
17) Export model
데이터 과학자는 학습된 모델과 학습 코드를 리포지토리에 커밋 합니다.
(D) Automated ML workflow pipeline
자동화된 ML 워크플로 파이프라인(Automated ML workflow pipeline)은 DevOps 엔지니어와 ML 엔지니어에 의해 코딩되어 리포지토리에 커밋됩니다. 만약 데이터 과학자가 새로운 ML 모델을 커밋하거나, DevOps, ML 엔지니어가 새로운 ML 워크플로 파이프라인 코드를 리포지토리에 커밋하게 되면, CI/CD 컴포넌트가 변경사항을 감지하고, 자동으로 빌드(build), 테스트(test), 배달(delivery) 단계를 수행하게 됩니다. 빌드(build) 단계에서는 ML 모델을 포함한 ML 워크플로 파이프라인을 생성하고, 테스트(test) 단계에서는 빌드된 파이프라인의 검증, 배달(delivery) 단계에서는 검증 완료된 버전닝된 파이프라인 이미지를 아티펙트(artifact) 스토어에 푸쉬 합니다.
DevOps 엔지니어, ML 엔지니어는 자동화된 ML 워크플로 파이프라인을 관리할 뿐만 아니라, 학습 인프라스트럭처, Kubernetes와 같은 프레임워크의 관리도 수행 합니다.
워크플로 오케스트레이션 컴포넌트(Workflow Orchestration Component)는 자동화된 ML 워크플로 파이프라인상의 테스크들을 조율하는 역할을 하는데, 테스크들을 수행함에 따라 생성되는 메타데이터(logs, 완료시간 등)를 수집하기도 합니다.
자동화된 ML 워크플로 파이프라인이 트리거되면, 다음의 테스크들이 순차적으로 자동 수행됩니다.
18) Data extraction
피처 스토어 시스템(feature store system)으로부터 특정 버전의 피처를 추출하는 일을 수행 합니다.
19) Data preparation & validation
학습을 위한 데이터 준비 과정이 자동으로 수행되며, 학습, 테스트, 검증 데이터셋이 자동으로 분류됩니다.
20) Model training & refinement
새로운 데이터를 이용한 모델 학습이 수행되는데, 모델 알고리즘과 하이퍼파라미터는 이전 단계의 실험을 거치면서 미리 정의된 코드를 사용하게 됩니다.
21) Model validation
학습된 모델의 자동화된 검증이 수행되며, 필요에 따라 자동화된 하이퍼파라미터의 조정도 있을수 있으며, 모델 학습과 검증 단계는 최상의 모델 품질이 도출될때까지 반복 수행될 수 있습니다.
모델 학습과 검증의 단계를 거치면서 학습 파라미터, 성능 메트릭, 학습 시간, 지속시간등의 트레킹 정보들이 메타데이터 스토어에 저장이 됩니다. 또, 모델리지니(model lineage)라고 부르는 모델에 상세 메타데이터에는 학습한 모델의 데이터, 코드 버전 정보들과 함께 모델 버전과 상태(staging or production-ready)들도 함께 트레킹 됩니다.
22) Export model
학습이 완료된 모델 결과는 관련된 설정 및 환경변수를 포함한 코드 형태나 컨테이너화된 형태로 추출될 수 있습니다.
23) Push to model registry
추출된 모델을 모델 레지스트리(Model Registry)에 푸쉬 합니다.
24) CD(Continuous Deployment)
ML 모델이 production-ready 상태가 되면 자동 배포를 위해 CD 컴포넌트가 배포 파이프라인(deployment pipeline)을 트리거 합니다. 이어서 배포 파이프라인은 ML 모델과 모델 서빙 코드를 가져와 빌드와 테스트를 거쳐 모델을 배포하게 됩니다.
25) Model serving
모델 서빙 컴포넌트는 ML 모델을 서비스하기 위해 학습된 ML 모델과 서빙 코드를 포함하고 있습니다. 서빙을 위해 피처 스토어 시스템을 통해 입력 데이터를 받기도 하고, REST API를 제공해서 추론 요청을 받기도 합니다.
26) Monitoring
모니터링 컴포넌트는 모델의 성능과 인프라스트럭처 환경을 실시간으로 모니터링 합니다. 만약 예측 성능의 저하등이 임계치를 벗어나면 해당 정보가 피드백 루프(feedback loop)를 통해 포워딩 됩니다.
27) Feedback loop
피드백 루프(feedback loop)는 모니터링 컴포넌트의 정보를 적절한 컴포넌트에 피드백하여 모델의 성능을 일정 수준으로 유지시키는데 목적이 있습니다. 피드백은 데이터 엔지니어링 영역(data engineering zone), ML 실험 영역(ML experiment zone), 스케줄러등에 줄 수 있습니다.
28) CT(Continuous Training)
모델 서빙중 드리프트에 변화가 생겨 임계치를 넘어설 경우 피드백 루프에 의해 CT(continuous training)이 구동 될 수 있습니다. 이런 경우 스케줄러가 피드백을 받게 되고, 스케줄러는 자동화된 ML 워크플로 파이프라인(automated ML workflow pipeline)을 트리거해 재학습을 시작합니다. 스케줄러에 의한 CT는 이렇게 이벤트 기반으로 동작할수도 있고, 새로운 데이터가 가용한 상태일때나 주기적으로(periodically) 트리거링 될수도 있습니다.
남은 과제들
조직 측면
저자는 ML 프로덕트의 성공을 위해서는 모델 중심의 문화에서 프로덕트 중심의 문화로 바뀌어야 한다고 주장하고 있습니다. 또, 이를 위해서는 MLOps의 도입은 필수적입니다. MLOps는 서로 다른 도메인의 그룹들이 협업을 해야 하므로, 도메인에 따라 서로 다른 지식과 용어, 이해관계로 발생하는 커뮤니케이션 문제를 줄이기 위한 마인드셋과 문화의 변화가 필요하다고 말하고 있습니다.
ML 시스템 측면
저자는 ML 학습(training)과 관련 잠재적으로 방대하고 다양한 데이터에서 비롯되는 수요에 맞는 리소스를 추정하기 어려우므로, 인프라 확장성 측면에서의 유연성을 강조하고 있습니다.
운영 측면
MLOps를 통한 자동화를 통해 대량의 데이터, 모델, 코드등의 버전이 생성될 것이며, 각 버전들을 생산성 있게 관리하고 유지하는게 필요하다는 주장입니다. 또, MLOps는 많은 조직과 컴포넌트들이 포함되어 있어, 오류 발생시 정확한 원인을 찾는것이 어려워 질수 있다고 말하고 있습니다.
지금까지 MLOps를 구성하기 위해 필요한 핵심 요소와 컴포넌트, 그리고 아키텍처에 대해 살펴보았습니다.
한 통계에 따르면 ML 사업을 하고 있지만, MLOps를 도입하지 않은 기업은 대다수라고 합니다. 아
직도 많은 데이터 과학자들은 ML 워크플로를 수동으로 처리하고 있으며, 복잡한 실세계의 ML 프로덕트를 성공적으로 사업화하기 위해서 MLOps의 도입은 필수적이라고 생각합니다.
본 글을 통해 MLOps에 대한 개념과 인사이트를 얻으셨길 바라며, 이상 논문 리뷰를 마치도록 하겠습니다.
'AI 솔루션 > MLOps' 카테고리의 다른 글
| [MLOps] MLOps 이해와 플랫폼 소개 (0) | 2022.06.09 |
|---|