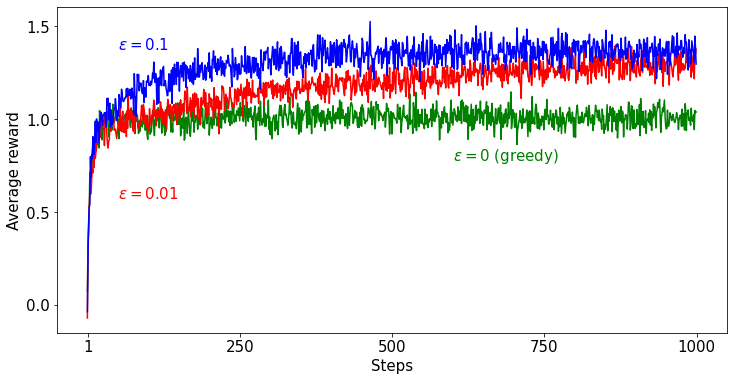
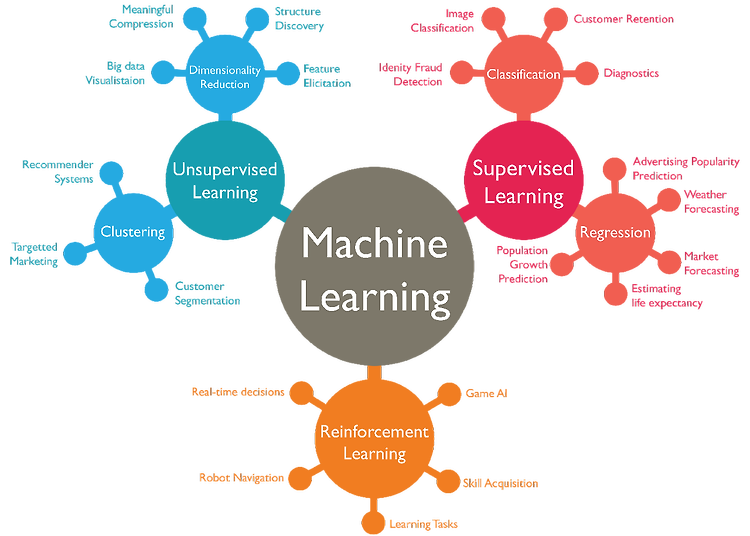
안녕하세요, 마인즈앤컴퍼니입니다. 오늘 AI 스터디에서는 Diffusion 모델이 처음 소개된 이후 초기의 복잡성을 단순화하고 속도를 높여 Diffusion 모델의 활용성을 키워준 DDPM과 DDIM이 무엇인지 알아보도록 하겠습니다. 초기 Diffusion 모델이 복잡했던 이유는 복잡한 loss function 수식 때문인데요. 이를 단순화한 방법을 설명하려면 수식에 대한 이해가 필요할 수밖에 없는 부분이 있습니다. 각 모델의 개선점에 초점을 맞추어 최대한 직관적으로 설명해 보았으니 조금은 어렵게 느껴지시더라도, 천천히 따라와주시면 충분히 DDPM과 DDIM을 이해하실 수 있을 거라 생각합니다😊 작성 - 마인즈앤컴퍼니 Data Scientist 조상우 매니저 집/검수 - 마인즈앤컴퍼니 AI Connect..