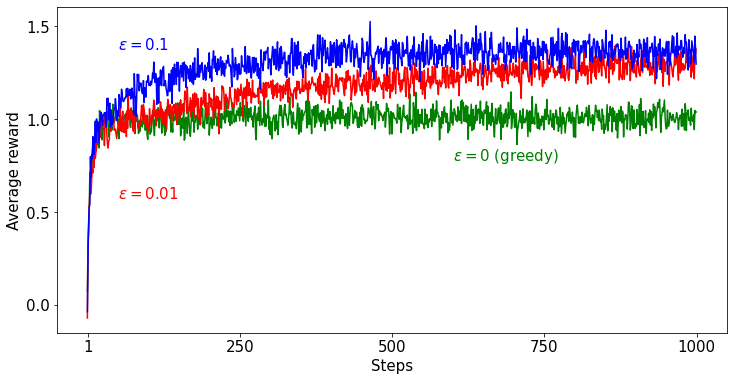
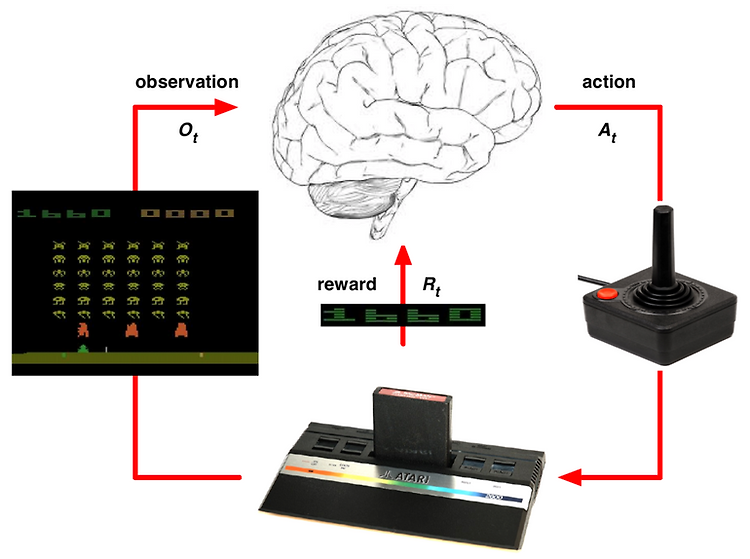
앞의 포스팅에서는 강화학습의 개념을 이해하고, 강화학습을 구성하는 필수 요소들에 대해 알아봤습니다. 이번 포스팅에서는 강화학습 분야에서 오랜 기간동안 연구되어 온 Multi-armed Bandit 문제를 기반으로 Exploration과 Exploitation에 대해 살펴보려고 합니다. Multi-armed Bandit 문제에 대해 설명하고 이 문제를 구현하여 Exploration과 Exploitation 에 대해 설명드리겠습니다. 본 포스팅에서 다루는 설명은 Sutton의 강화학습 책을 많이 참고하였습니다. 관련 코드는 Github 에서 확인할 수 있습니다. Greedy Method Exploitation을 하기 위해서 우리는 행동에 대한 평가가 필요합니다. 이 평가는 이전 포스팅에서 배운 Value라는..