안녕하세요, AI CONNECT 입니다.
AI CONNECT에서는 종료된 경진대회더라도, 누구나 종료된 대회의 과제의 풀고 결과를 제출할 수 있는 연습 제출 기능을 오픈했습니다.
연습 제출이기 때문에 기존의 리더보드 순위가 변하지는 않지만, 내 수준이 어느 정도인지 점수를 통해 확인해볼 수 있는데요.
연습제출로 풀어볼 수 있는 과제인 '노트북으로 GPT 맛보기 - 한국어 문서 생성 요약'에 도전하시는 분들을 위해, 대회 당시 업로드된 사전 스터디 자료를 공유합니다.
AI CONNECT | AI competition Platform
No.1 인공지능 경진대회 플랫폼
aiconnect.kr
*이 자료는 마인즈앤컴퍼니-AI Connect의 소중한 지적 자산으로, 사전에 허가 받지 않은 형태의 외부 유출과 재배포를 금지합니다.
오늘은 여러분과 별도의 학습 없이도 몇 가지 Parameter만 수정하는 방식을 통하여
- 내가 원하는 방향으로 GPT의 문장 생성 방향을 유도하는 방법을 알아보고,
- 내가 설정한 GPT 추론(Inference) Parameter가 어떠한 방식으로 작동하는지 알아보며
여러분들이 더 친숙하게 GPT 모델을 대할 수 있도록 도움을 드리고자 합니다.
이 과정에서 여러분들이 궁금한 점이 있거나, 중간중간 의견을 더해주실 것이 있다면 커뮤니티 게시판에 남겨주세요!
실습 환경으로서는 Colab을 활용하며, Colab 예제 코드를 함께 업로드 하였으니 한 걸음 한 걸음, 차근차근 함께하시면 좋을 것 같습니다.
(단, GPT3 모델의 경우 워낙 그 크기가 방대하여 안정적인 실습 진행을 위하여 기본 Colab이 아닌 Colab-Pro (월 $9.99) 활용을 권장드립니다.)
이번 시간 베이스라인 코드에서 저희가 활용할 모델은 2021년 Kakao Brain에서 공개한 KoGPT-3 모델입니다. GPT-3 모델을 기반으로 한국어에 적합한 형태로 재 학습시킨 모델로, 우리는 원본 KoGPT-3가 아닌 float-16 버전 모델을 활용하여 Colab 환경에서도 구동할 수 있을 정도로 GPU 메모리 사용량을 최소화할 것입니다. 그럼, 본격적으로 베이스라인 코드를 함께 살펴보겠습니다.
[참고] float-16이란? - 자료 형태와 정밀도
Python은 숫자를 표현하는 다양한 형태의 자료 형태가 있으며, Python의 딥러닝 라이브러리인 Tensorflow, Pytorch 역시 숫자로 이루어진 모델의 가중치(Weight) 다양한 형태로 저장할 수 있습니다. 특히 각 수를 할당하는 자료 형태를 어떻게 지정하느냐에 따라 메모리 사용량과 계산의 정밀도가 달라집니다.
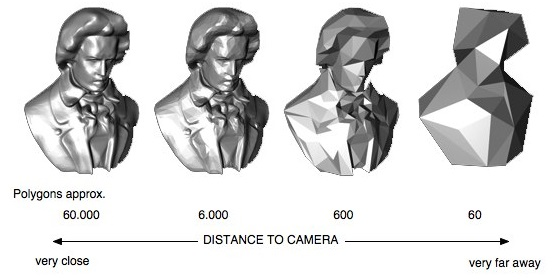
이러한 자료 형태의 정밀도가 쉽게 와 닿지 않은 분들을 위하여 다음의 그림을 준비하였습니다. 아래의 그림에서처럼 같은 대상을 얼마나 정밀하게 표현하느냐에 따라 그 형태가 달라짐을 알 수 있습니다. float-16 모델과 float-32 모델도 이와 같은 차이가 있다고 이해해 주시면 좋을 것 같습니다.
모델 불러오기
이번 실습에서 활용할 KoGPT-3 모델은 Hugging Face 라이브러리를 활용하여 Tokenizer와 언어 모델을 손쉽게 불러올 수 있습니다.
[Code]
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('kakaobrain/kogpt',revision='KoGPT6B-ryan1.5b-float16',...)
model = AutoModelForCausalLM.from_pretrained('kakaobrain/kogpt',
revision='KoGPT6B-ryan1.5b-float16',...)
Hugging Face에는 GPT 외에도 손쉽게 활용할 수 있는 많은 모델이 업로드되어 있으니 궁금하신 분들은 공식 페이지를 참고하시기 바랍니다. 또한, Hugging Face 모델을 활용하는 본인만의 노하우가 있으신 분은 커뮤니티 게시판에 함께 공유해주세요. (’커뮤니티 활동 점수’ 잊지 않으셨죠?)
결과 출력하기
GPT의 생성 모델을 활용해 Input에 대한 Output을 얻는 코드는 기본적으로 다음과 같습니다. 기본적으로 input_tokens를 입력받는 것은 여타 언어 모델들과 동일하지만, 그 외 기타 설정값들을 어떻게 조절하느냐에 따라서 GPT 모델은 다양한 결과를 출력하게 됩니다.
[Code]
gen_tokens = model.generate(input_tokens,나의 설정값들)
그럼, 설정값을 요리조리 조절해보기 위해 GPT 모델이 기본적으로 무엇을 하는지, 또 우리가 변화를 줄 수 있는 부분은 무엇인지 알아보겠습니다.
GPT 모델이 하는 일: 다음 단어 맞추기
GPT 모델이 기본적으로 수행하는 일은 주어진 문장(Input)에 이어지는 바로 다음 단어를 맞추는 일입니다. 다음 단어 맞추기를 얼마나 연속적으로 수행하는지에 따라 짧은 문장, 긴 문장 등의 문장 단위에서 문단, 더 나아가는 소설 정도 길이의 글을 생성해낼 수도 있습니다.
Ex) 여행을(Input) 가고(Input) / 추론 시작!
Ex) 여행을(Input) 가고(Input) / 싶다(Inference)
Ex) 여행을(Input) 가고(Input) / 싶다(Inference) 너와(Inference)
Ex) 여행을(Input) 가고(Input) / 싶다(Inference) 너와(Inference) 함께(Inference) [EOS](Inference)
GPT 모델은 주어진 Input에 해당하는 문장 뒤에 이어질 다음 단어를 확률적으로 예측합니다. 현재 t번째까지의 단어들이 주어졌을 때, 그다음인 t+1번째에 올 수 있는 단어들의 확률(조건부 확률)을 예측하는 것이죠. 결국 총 T개의 단어로 이루어진 문장을 예측하는 경우라면, 1~T번째 단어 모두의 조건부 확률의 곱을 확률로 가지게 됩니다.
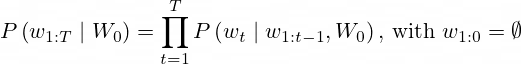
위에서 확인한 것처럼, 확률적 예측은 앞선 예측(1~t번째 단어)이 무엇인지에 따라 다음 예측(t+1번째 단어)의 확률도 연쇄적으로 영향을 받습니다. 그래서 최종 문장이 어떤 단어의 조합으로 구성되는지에 따라 그 확률은 굉장히 달라질 수 있고, 가장 높은 확률을 갖는 최적의 문장을 찾아내는 과정도 간단하지 않습니다. 이 과정에서 시도할 수 있는 다양한 방법들은 추론 시간, 문장 완성도 등에서 차이를 발생시키기도 하는데요. GPT 모델은 어떤 방법들을 사용하는지 살펴보겠습니다.
GPT가 다음 단어를 선택하는 방법: search vs sampling
GPT의 추론 방법은 크게 search와 sampling 두 가지로 구분되고, 각 방법은 또 몇 가지 다른 방법들로 구분됩니다. 가장 기본적인 greedy search와 그 문제점을 보완한 beam search, search 방식이 여전히 해결할 수 없는 문제를 다른 방법으로 해결하려 하는 top-k와 top-p sampling을 소개합니다.
Greedy Search
Greedy Search는 GPT 모델의 기본 옵션이며, 단순하게 다음 단어로 가장 높은 확률을 가지는 단어를 선택합니다. 그 순간 최선(확률값이 가장 높은 단어)을 선택한다는 점에서 매우 직관적이며 효과적입니다.
Time step 1 혹은 첫 번째 가지치기의 분기가 발생하는 곳에서 가장 가능성이 높은 가설은 (The, nice)로 확률이 0.5, 그다음으로 높은 확률을 보이는 가설은 (The, dog)로 확률이 0.4입니다. 이 외에도 여러 가지 다른 확률의 가설들이 존재 하겠으나 하단의 식처럼 greedy search 방법은 오로지 확률이 가장 높은 최댓값만을 다음에 이어질 단어로 고려합니다.

(The, nice) 이후에 이어질 단어로 woman이 선택되는 이유 역시 모델이 해당 분기에서 예측한 가장 큰 확률의 단어가 0.4의 확률값을 지닌 woman이기 때문입니다. 앞서 말한 바와 같이 이와 같은 방법은 매우 직관적이며 많은 상황에서 매우 효과적입니다.
그러나 문장의 전체 맥락을 고려하지 않고 순간순간의 최선의 선택만 따라가는 추론 방법은 언어 생성을 하는 데 있어 몇 가지 문제점을 야기하였습니다.
Greedy search의 주된 단점은 낮은 확률 사이에 숨겨진 높은 확률의 단어를 놓치는 것입니다. 위의 예시에서는 (The dog has)를 놓친 것을 볼 수 있습니다. 이 문장은 사실 0.4×0.9=0.36으로 위의 문장(The nice woman)보다 조금 더 가능성이 있는 문장입니다.
Greedy 전략에서는 매 시점 가장 높은 확률값을 가지는 nice(p=0.5) → woman(p=0.4)을 선택하게 되고, 이 문장의 최종 확률은 0.5*0.4 = 0.2가 됩니다. 하지만, nice(p=0.5) 토큰에 가려져 선택하지 못했던 dog(p=0.4)에 잇따르는 토큰은
has(p=0.9)로, 이 트랙을 따랐다면 더 좋은 토큰을 선택할 수 있었을 것인데 말입니다.
Beam Search

Beam search는 beam 크기만큼의 선택지를 계산 범위에 넣습니다. 각 타임 스텝에서 가장 가능성 있는 num_beams 개의 시퀀스를 유지하고, 최종적으로 가장 확률이 높은 가설을 선택하는 방법으로서 앞서 설명한 greedy search 방법의 한계를 극복하는 데 도움을 줍니다.
가지치기의 첫 번째 단계(time step 1)에서 가장 가능성이 높은 가설은 (The, nice)로 확률이 0.5, 그다음으로 높은 확률을 보이는 가설은 (The, dog)로 확률이 0.4입니다. greedy search에서는 가장 높은 경우의 확률을 보이는 단어만을 선택했기 때문에 다른 가능성이 고려되지 않았으나, beam search에서는 num_beams만큼 후보 답안들을 유지하기 때문에 두 번째로 높은 확률을 가지는 후보 (The, dog)를 기각하지 않고 유지합니다.
가지치기의 두 번째 단계(time step 2)에서 (The, dog, has)는 0.36의 확률을 가지는 후보이고 greedy search의 결과였던 (The, nice, woman)은 0.2의 확률을 가지는 후보입니다. 두번째 단계까지의 단어 후보들을 동시에 고려한 결과 확률이 뒤집혔음을 알 수 있습니다.
이처럼 beam search는 언제나 greedy search보다 높은 확률의 답안을 찾게 되지만, 반드시 최선의 정답을 보장하지는 않습니다. num_beams의 범위를 넘어가는 곳에 최적의 답이 존재하는 경우가 이러한 상황입니다.
Search(최대화)의 문제, 반복된 단어 예측
Greedy와 beam search 모두 확률이 높은 단어를 반복해서 선택해 계속하여 같은 단어만을 예측하는 상황이 자주 발생합니다. 특정 단어 혹은 단어의 묶음인 n-gram이 설정한 횟수 이상으로 반복될 경우 이에 대한 단어의 확률값을 강제로 0으로 할당하거나 페널티를 주어 일정 수준 이하로 확률값을 낮출 수 있습니다.
해당 예시에서는 no_repeat_ngram_size=3으로 3-gram 이상의 단어가 반복될 경우 해당 확률을 0으로 강제로 할당하였습니다.
[Code]
gen_tokens = model.generate(tokens, num_beams=3, max_length=len(tokens[0])+100, no_repeat_ngram_size=3)
Sampling (확률에 따른 랜덤 뽑기)
특정 단어가 선택될 확률이 greedy search 혹은 beam search의 기준에 미치지 못한다고 해서 해당 단어를 고려에서 완전히 제외하는 것이 과연 옳은 선택일까요? ‘생성’이라는 측면에서 보면 이는 적합하지 않은 행동입니다. ‘생성’이라는 측면에서 고려해 보면 소수의 선택지 만을 두는 것보다 여러 후보군을 설정한 후 그 후보군 내에서 다시 확률적으로 선택하는 방법이 더 적합할 것입니다.
이와 같은 sampling 방법에는 대표적으로 top-k sampling, top-p sampling 방법론 등이 있습니다. greedy, beam과 같은 최대화 기법들이 가장 높은 확률을 가지는 후보들만을 택했다면, sampling을 사용한 언어 생성은 더 이상 결정적이지 않습니다. (non-deterministic 함)
단어 car는 beam의 크기를 3만큼 늘리지 않으면 이전 최대화 방법론에서는 어떠한 경우에도 절대로 채택되지 않습니다. 하지만 sampling 된 후보군에서는 정말 낮은 확률로 조건부 확률 분포에서 단어 car가 추출될 수 있으며 다음 단어인 drives, is, turns가 이어지는 조건부 확률 분포에서 추출될 것입니다.
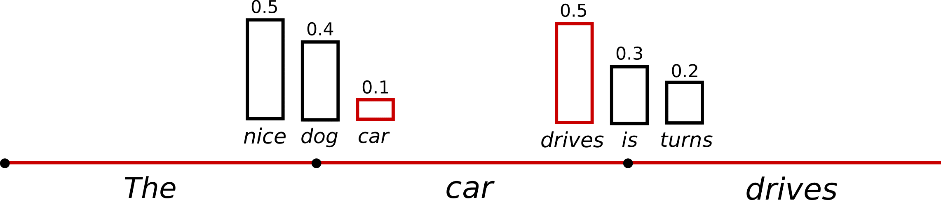
[Code]
# do_sample을 False로 설정한다면 최대화(greedy, beam) 기법으로 추론 진행
gen_tokens = model.generate(tokens, do_sample=False)
# do_sample=True로 설정하면 sampling 기법으로 추론 진행
# default는 top_k=1로 최대화 기법과 동일
gen_tokens = model.generate(tokens, do_sample=True)
Sampling에는 temperature라는 추가적인 파라미터가 적용될 수 있습니다. Temperature에 따라 기존의 확률 분포에 더 민감하게 반응하게 할 수도, 더 둔감하게 반응하게 할 수도 있습니다. Temperature가 낮을수록 확률 분포의 차이를 극대화하여 sampling의 효과가 낮아지고, 처음 설명한 greedy search와 유사(deterministic)한 방식으로 작동합니다.

Top-K Sampling
사전에 설정한 K개의 단어 만큼을 후보로 sampling을 진행한 후 다음 추론으로 과정을 이어갑니다.
[Code]
# top_k 옵션으로 후보군 개수 설정
gen_tokens = model.generate(tokens, do_sample=True,top_k=10)

Top-P Sampling
사전에 설정한 누적 확률 이내의 모든 단어를 후보로 sampling을 진행 후 다음 추론으로 과정을 이어갑니다.
# top_p 옵션으로 누적 분포 옵션 설정 (0~1)
gen_tokens = model.generate(tokens, do_sample=True, top_p=0.8)
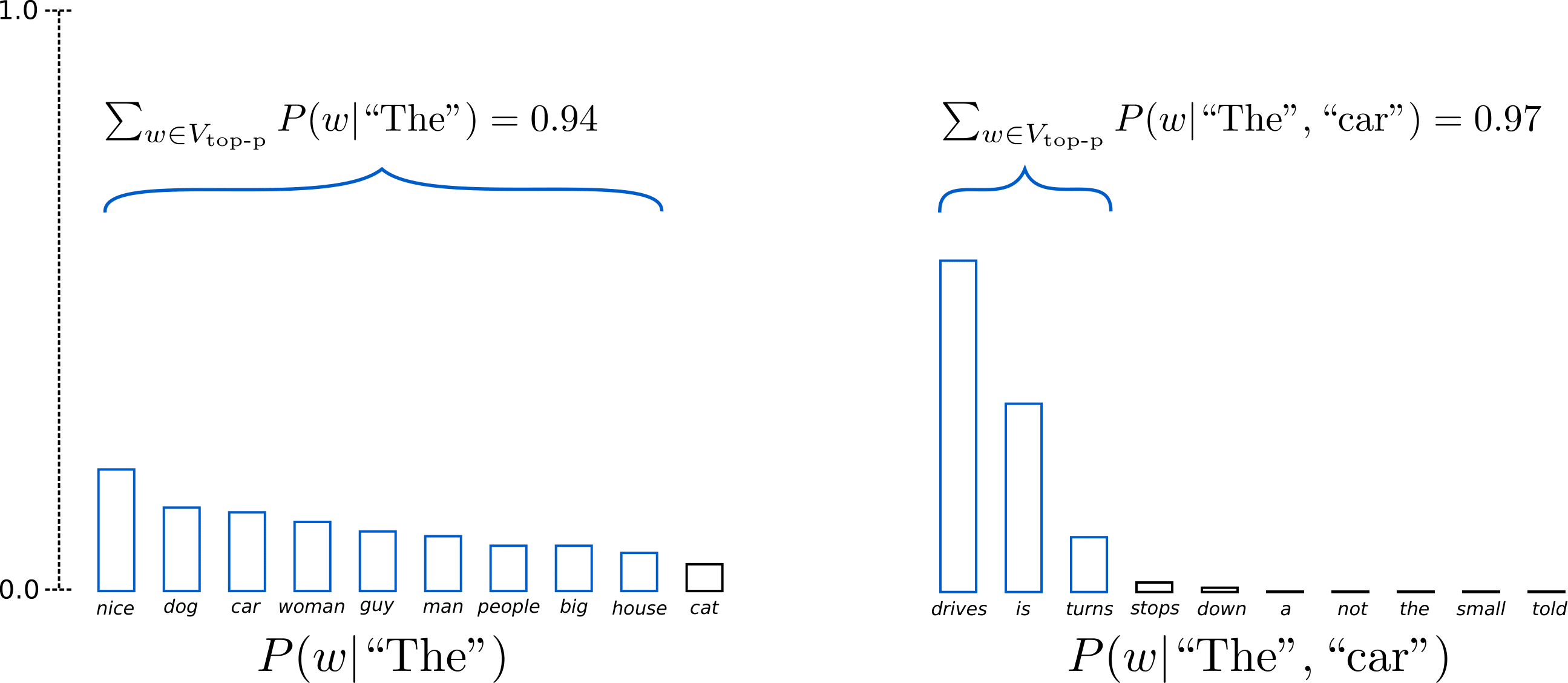
하나의 GPT 모델만으로도 이처럼 다양한 추론 방법이 존재합니다.
여러분이 생각하는 이번 생성 요약을 위한 최고의 추론 방법은 무엇인가요? 혹은, GPT 모델 말고 사용할 수 있는 모델들은 어떤 것들이 있을까요?
과연 GPT가 이번에도 놀라운 성능을 기록할 것인지, GPT를 이기는 모델이 등장할 것인지, 대회를 준비하는 지금 여러분들이 느끼는 의견이 무엇인지 나눠보시는 건 어떨까요?
참고자료 출처
https://jinmang2.github.io/🤗 huggingface/nlp/2022/03/01/how-to-generate.html
https://littlefoxdiary.tistory.com/46
https://ratsgo.github.io/nlpbook/docs/generation/inference1/
'MNC Inside > AI CONNECT' 카테고리의 다른 글
| [EVENT] 중요한 건 꺾이지 않는 연습! (0) | 2023.04.28 |
|---|---|
| GPT 모델과 모델 경량화 기법 소개: '노트북으로 GPT 맛보기' 연습제출 스터디 자료 (0) | 2023.04.13 |
| 지난 대회 문제로 실력 점검! AI CONNECT 연습제출 과제 오픈📢 (0) | 2023.03.31 |
| 노트북으로 GPT 맛보기💻 경진대회 오픈 (0) | 2023.03.07 |
| 2022 암 예후예측 데이터 구축 AI 경진대회 수상자 인터뷰 (0) | 2023.01.06 |