안녕하세요, AI CONNECT 입니다.
AI CONNECT에서는 종료된 경진대회더라도, 누구나 종료된 대회의 과제의 풀고 결과를 제출할 수 있는 연습 제출 기능을 오픈했습니다.
연습 제출이기 때문에 기존의 리더보드 순위가 변하지는 않지만, 내 수준이 어느 정도인지 점수를 통해 확인해볼 수 있는데요.
연습제출로 풀어볼 수 있는 과제인 '노트북으로 GPT 맛보기 - 한국어 문서 생성 요약'에 도전하시는 분들을 위해, 대회 당시 업로드된 사전 스터디 자료를 공유합니다.
AI CONNECT | AI competition Platform
No.1 인공지능 경진대회 플랫폼
aiconnect.kr
안녕하세요, 참가자 여러분! 경진대회 운영사무국입니다.
노트북으로 GPT 맛보기 과제를 한층 더 의미 있게 진행하실 수 있길 바라는 마음으로, 관련된 사전 지식 몇 가지를 소개해드리려고 합니다.
이번 글의 Part 1에서는 다양한 거대 언어 모델 (large language model) 중 하나인 GPT의 기본 원리를, Part 2에서는 이러한 거대 언어 모델을 코랩 환경에서 돌릴 수 있게 해줄 경량화 기술 Low-Rank Adaptation과 Prompt Tuning에 대해서 살펴보도록 하겠습니다.
*이 자료는 마인즈앤컴퍼니-AI Connect의 소중한 지적 자산으로, 사전에 허가 받지 않은 형태의 외부 유출과 재배포를 금지합니다.
Part 1. GPT 모델 소개
최근 공개된 OpenAI의 ChatGPT는 전 세계적으로 많은 관심을 받으며 다양한 분야에서 파급효과를 내고 있습니다. 그러나 ChatGPT는 어느 날 갑자기 새로이 생겨난 모델이 아닙니다. GPT는 버전 1부터 3에 이어지는 끊임없는 개선을 이뤄왔고, 현재 GPT 3.5 버전을 기반으로 한 ChatGPT는 강력한 성능을 얻어낼 수 있었습니다. 그렇다면 GPT란 무엇인지 간단히 살펴보도록 하겠습니다.
딥러닝 분야에서 가장 많이 활용되는 지도 학습 방식은 많은 양의 라벨링 된 데이터가 필요합니다. 그러나 요약, 질의응답 등 다양한 자연어 처리 태스크를 위한 라벨링 작업에는 큰 비용이 발생합니다. 이러한 비용을 줄이기 위해 라벨링 된 데이터 없이도 인터넷상에서 수집할 수 있는 수많은 corpus에 존재하는 언어적 정보(linguistic information)를 이용해 언어 모델을 학습해 성능을 끌어올리는 것이 GPT의 목적입니다. 즉, 다량의 라벨링 되지 않은 corpus를 기반으로 모델이 언어의 universal representation을 이해하도록 만듭니다.
하지만 결국에는 특정한 태스크를 수행할 수 있는 모델이 필요한데, 이 방식은 GPT 버전에 따라 조금 차이가 있습니다. GPT-1은 1단계로 언어의 universal representation을 사전 학습 시킨 후, 2단계로 각 태스크에 맞게 준비한 소량의 라벨링 데이터를 기반으로 fine-tuning을 수행하였습니다. 반면, GPT-2부터는 훨씬 큰 학습 데이터로 인해 언어 모델을 사전 학습시키는 단계부터 애초에 여러 태스크가 가능한 task conditioning이 될 수 있도록 하였습니다.
그럼, 각 단계를 좀 더 세부적으로 설명드리겠습니다.
Unsupervised Pre-training
앞서 다량의 라벨링 되지 않은 corpus를 기반으로 언어 모델을 학습한다고 했습니다. 이렇게 라벨링 된 데이터가 존재하지 않을 때 적용할 수 있는 학습 방법론이 비지도 학습(Unsupervised Learning)입니다. 예를 들어, 아래 그림과 같이 “Second Law of Robotics: A robot must obey the orders given it by human beings”라는 문장이 주어졌을 때 어떻게 학습되는지 살펴보겠습니다.
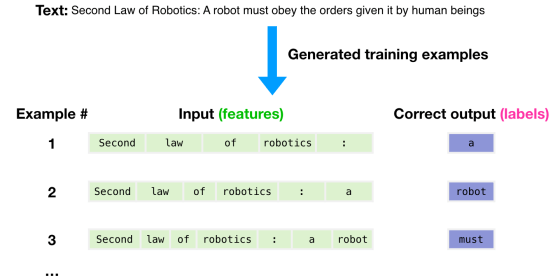
이미지1: Unsupervised Pre-training 설명 출처
GPT는 특정 문장의 주어졌을 때 다음 단어를 맞추는 방식으로 학습합니다. 예를 들어, “Second law of robotics:” 이라는 문장을 GPT 모델의 입력으로 넣으면 다음 단어인 “a”를 맞춰야 하는 것입니다. 자연어 처리 분야에서는 다음 단어를 맞춘다는 표현보다 다음 토큰을 맞춘다는 표현을 사용합니다. 문장을 토큰화하는 방식에는 Word tokenization, WordPiece tokenization 등이 있습니다. 토큰화에 대해 정리된 다른 자료가 많으니 본 포스팅에서는 더 자세히 다루지 않겠습니다.
수식으로 다시 설명하자면, 어떠한 corpus의 token들을 $\mathcal{U}={u_1, ..., u_n}$ 라고 할 때 아래와 같이 정의된 log-likelihood를 최대화하는 방식으로 학습합니다.
$$L_1(\mathcal{U})=\sum_i\log P(u_i|u_{i-k},...,u_{i-1};\Theta)$$
여기서 k는 context window로 다음 단어를 예측할 때 참조할 이전 토큰의 개수입니다. ΘΘ는 모델의 파라미터를 나타내며, GPT의 경우 Transformer의 decoder 모듈을 사용했습니다(Transformer에 대한 설명은 본 포스팅의 범위를 벗어나 자세히 다루지 않겠습니다). 다시 말해, 목적 함수 $ L_1(\mathcal{U}) $를 학습한다는 것은, 앞선 토큰 k개를 참조하여 정답 토큰 $ u_i $에 대한 예측 확률을 최대화 하는 것입니다.
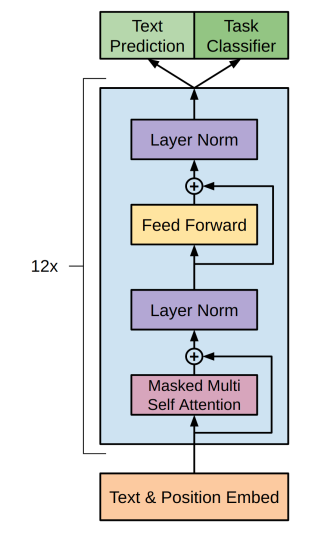
이미지2: GPT에서 사용한 Transformer 구조
이러한 학습 방식은 일면 정답 데이터를 학습하는 지도 학습과 유사하지만, 별도의 라벨링 작업 없이도 다음 토큰을 예측하는 것을 방대한 corpus에 대하여 반복적으로 학습함으로써 universal representation을 학습할 수 있다는 장점이 있습니다.
Supervised Fine-tuning
GPT-1 모델의 경우, 앞서 학습한 pre-trained 모델을 활용해 적용하고자 하는 자연어 처리 태스크를 위해 미세조정(Fine-tuning) 하는 단계를 진행했습니다.
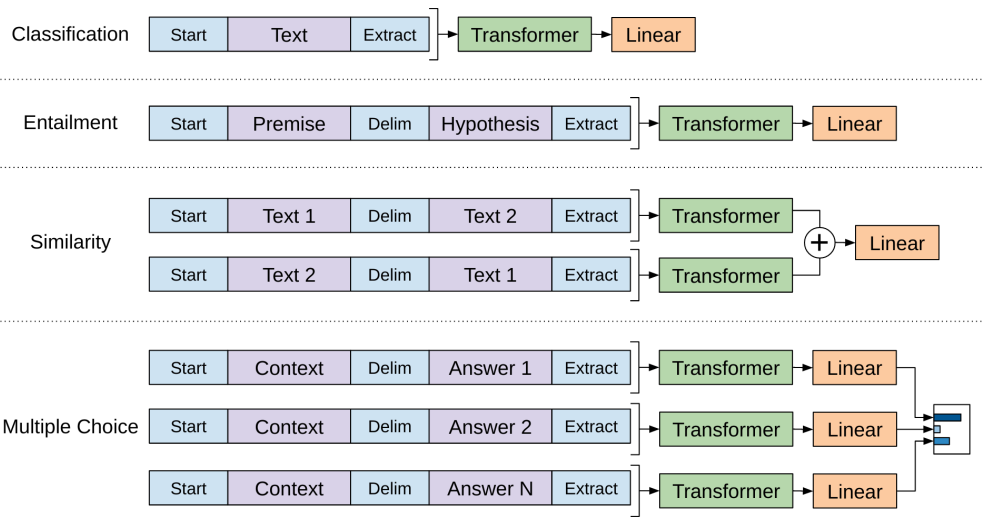
이미지3: 다양한 태스크에 Fine-tuning하는 예시
라벨링된 데이터셋 $ C $가 주어졌다고 가정해보겠습니다. 데이터셋 $ C $는 정답 $ y $와 토큰 $ x^1,\dots,x^m $으로 표현되는 여러 샘플로 구성되어 있습니다. 모델의 예측은 아래와 같이 표현됩니다.
$$ P(y|x^1,...,x^m)=\text{softmax}(h_{l}^{m}W_y) $$
여기서 $ h_{l}^{m} $ 은 pre-trained 모델의 마지막 transformer 레이어의 출력이며, $ W_y $는 출력 직전의 linear 레이어입니다. 위 그림의 classification 태스크를 위해 fine-tuning 하는 것을 예시로 다시 한번 설명하겠습니다. 토큰화된 입력 문장 (예를 들어, [’노트북으로’, ’GPT’, ‘맛보기’, ‘경진대회’, ‘재밌어’])을 pre-trained GPT 모델에 입력하게 되면 linear 레이어를 통해 부정인지 긍정인지 확률을 추론하게 되는 것입니다.
이러한 모델을 학습하기 위해서는 마찬가지로 아래와 같은 log-likelihood를 최대화하게 됩니다.
$$ L_2(\mathcal{C})=\sum_{(x,y)}logP(y|x^1,...,x^m) $$
Multi-task Learning
GPT-1에서는 사전 학습된 언어 모델을 fine-tuning 해 모델이 특정 태스크를 수행할 수 있게 하였습니다. 하지만 GPT-2부터는 이 fine-tuning 단계가 사라지고 사전 학습 모델 자체를 여러 태스크를 수행할 수 있는 multi-task 모델로 만들었습니다. 이것이 가능한 이유는 사전 학습 단계의 학습 데이터를 훨씬 키우면서 수행하고자 하는 태스크에 대한 정보가 입력으로 함께 들어가는 ‘prompt’와 비슷한 형태의 데이터가 자연스럽게 존재하게 되었기 때문입니다.
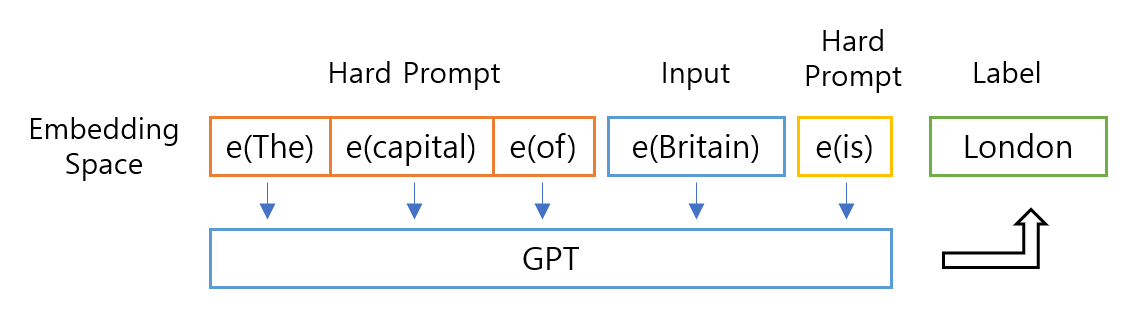
이미지4: prompt 사용 예시
Prompt란 수행하고자 하는 태스크에 대한 정보를 입력에 추가하는 것입니다. 예를 들어, 나라를 입력해 수도를 찾고 싶을 때, “~의 수도는 (The capital of ~ is)” 이라는 원하는 출력에 대한 정보가 prompt가 될 수 있습니다. (이미지의 Hard prompt가 무엇인지는 Part 2.에서 설명해 드리겠습니다!)
prompt가 추가된 것과 유사한 형태의 태스크 정보를 포함한 데이터들이 학습 데이터에 존재할 경우, 모델에 입력 데이터만이 아닌 태스크 정보를 함께 주는 task conditioning을 진행한 것과 유사한 효과가 있을 것입니다. task conditioning은 하나의 모델이 여러 태스크를 할 수 있게 만드는 multi-task learning이나 특정 태스크를 위한 모델을 적은 데이터로 다른 태스크에도 적합하게 만드는 meta learning 등을 위해 사용됩니다. 이러한 방법으로 인해 추가적인 fine-tuning 없이도 GPT의 사전 학습 모델은 여러 태스크를 수행할 수 있게 되었습니다.
이 외에도, 위와 같은 방법으로 학습된 multi-task 모델에 추론 시 prompt를 입력과 함께 넣는 zero-shot, 이에 더해 입출력 예시까지 함께 넣는 one/few-shot 등의 방법을 사용하기도 했습니다. 관심이 식을 줄 모르는 ChatGPT는 GPT-3.5모델을 사용하고, 불과 며칠 전에는 GPT-4의 소식 또한 전해졌는데, 이 버전들은 또 어떤 차이가 있는지 공유해보시는 건 어떨까요?
그럼, 이제 이 GPT를 엄청난 컴퓨팅 리소스 없이도 이번 대회의 과제인 ‘생성 요약’과 같은 특정 태스크를 주어진 데이터에 대해 좀 더 잘 수행할 수 있게 만들 수 있는 방법을 소개해드리겠습니다.
Part 2. 거대 언어 모델 경량화 기법
GPT는 버전 3에 이르면서 기존 언어 모델보다 훨씬 많은 1,750억 개의 파라미터를 사용했습니다. 이러한 거대 언어 모델은 코랩과 같은 일반적인 환경에서 fine-tuning 하는 것조차 감당하기 어렵습니다. 따라서, 본 파트에서는 거대 언어 모델을 경량화할 수 있는 기법을 소개하도록 하겠습니다.
Low-Rank Adaptation (LoRA)
LoRA는 특정 태스크에 맞게 모델을 수정하는 과정에서 실제 변화하는 가중치는 기존 모델보다 훨씬 낮은 rank($ r $)를 갖는다는 가설에서 시작합니다. 이 작은 가중치 변화만으로 특정 태스크를 위해 변화가 필요한 정보를 잘 표현할 수 있다면, 이를 분리해 별도의 matrix를 구성한 후 이를 fine-tuning 하는 것은 기존 모델 전체를 fine-tuning 하는 것과 비슷한 효과가 있을 것입니다.
위 가설을 전제로, 특정 레이어에서 거대한 사전학습 가중치는 freeze 시킨 상태에서 훨씬 크기가 작은 rank decomposition matrix를 삽입하고 이것만 학습시키는 것이 LoRA입니다. LoRA를 처음 제안한 2021년 논문 (링크)에서는 Transformer 계열 모델의 경우 attention weight에만 해당 방법을 적용하였고, out weight 등에 적용하기도 합니다.
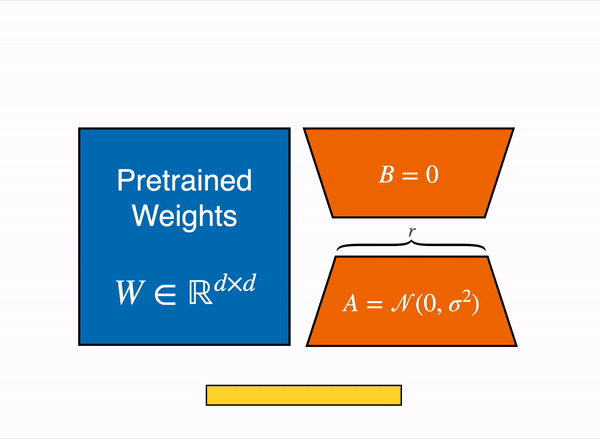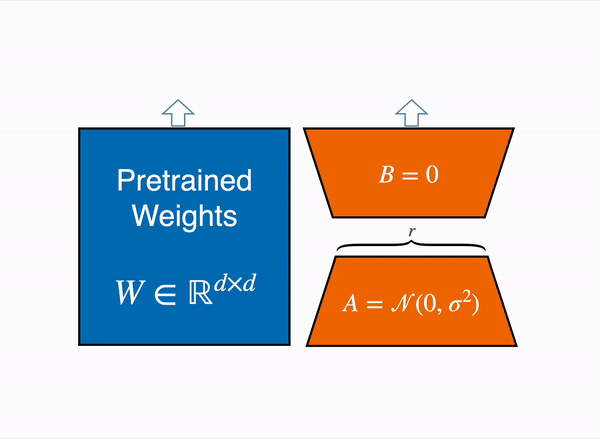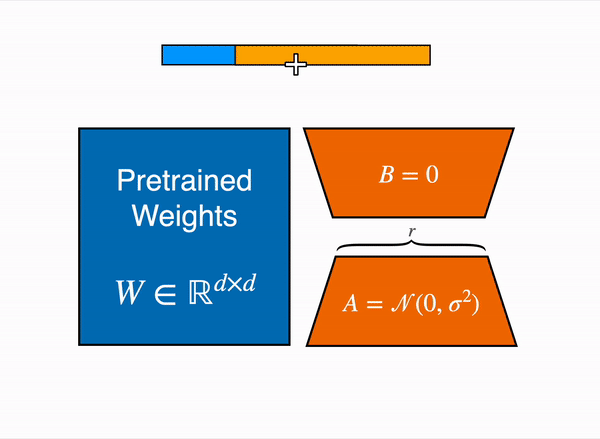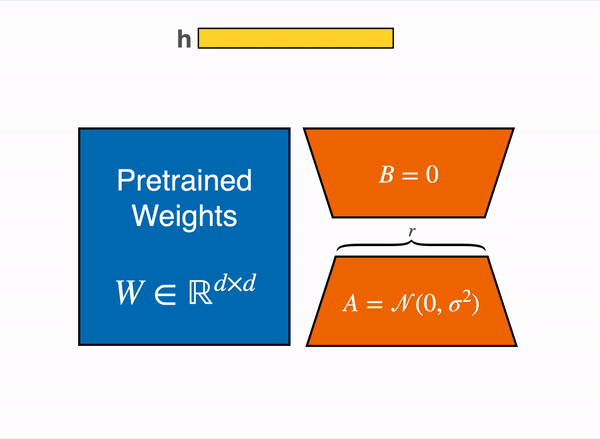
이미지5: A와 B만 학습함 출처
사전학습 가중치($ W_0 $)와 adaptation 과정에서 업데이트 시키는 누적 gradient인 $ \Delta W=BA $은 동일한 input $ x $를 받아 나온 출력 벡터를 더해 해당 레이어의 최종 output $ h $가 계산됩니다.
$$ h=W_0x+\Delta Wx=W_0x+BAx $$
이렇게 LoRA는 $ W_0 $은 가만히 둔 채로 훨씬 작은 $ \Delta W_0 $를 학습해 특정 레이어의 출력을 바꾸는 방식으로 fine-tuning 속도와 필요 자원을 많이 축소할 수 있습니다. 또한, 위 수식에서 확인할 수 있듯 $ \Delta Wx $가 단순히 더해지는 것이기 때문에 해당 부분만 갈아 끼우는 방식으로 편리하게 다른 작업으로 전환이 가능합니다.
Prompt Tuning
Part 1의 Task Conditioning에서 prompt가 무엇인지 먼저 소개한 바 있습니다. 사전 학습된 GPT를 사용해 특정 태스크를 수행하는 잠깐 언급한 zero-shot과 같은 과정에서는 prompt로 태스크에 대한 정보를 입력해주어야 하는데, 좋은 prompt를 만드는 것은 생각보다 쉽지 않습니다.

이미지6 출처: GPT Understands, Too
위의 예시는 주어진 전제조건[PRE]에 가설[HYP]이 맞는지(출력[MASK]) 물어보는 동일한 의미의 다양한 prompt입니다. 정확도가 보여주는 것처럼 같은 의미임에도 불구하고 prompt가 조금만 바뀌어도 결과는 크게 바뀝니다. 하지만 사람이 직접 어떤 prompt가 가장 좋은지 판단하거나 좋은 prompt를 작성하긴 어려운데, 이를 해결하려는 시도가 prompt tuning입니다.
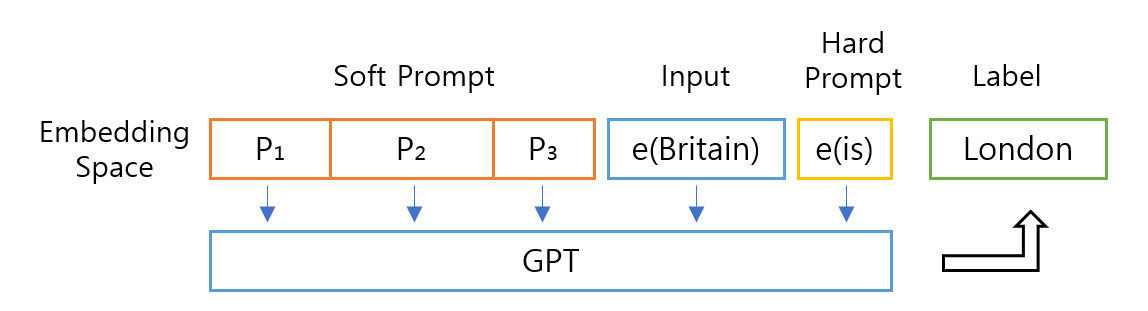
이미지 7: Prompt Tuning 예시
Prompt의 각 토큰은 Transformer로 입력되기 전 embedding 과정을 거쳐 embedding space의 벡터가 됩니다. 이 벡터(위 예시의 $ P_1, P_2, P_3 $)를 일종의 파라미터로 보면, 언어 모델의 loss를 기준으로 역전파해서 학습시킬 수 있습니다. 이 경우, $ P_1, P_2, P_3 $는 실제 존재하는 토큰에 1:1 대응될 필요 없이 자유로운 값을 가지게 되고 이를 soft prompt라고 합니다.
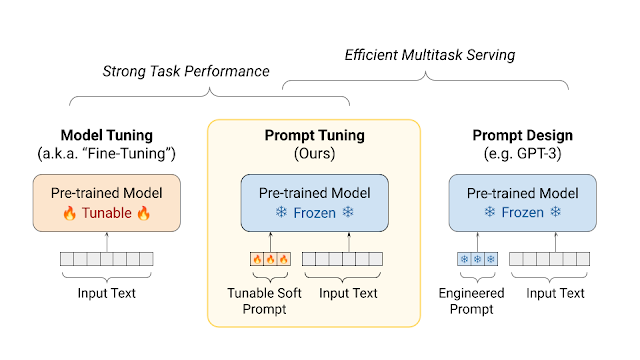
이미지8 출처: Guiding Frozen Language Models with Learned Soft Prompts
Prompt tuning은 언어 모델의 파라미터는 고정한 채로 soft prompt만 학습하는 방식입니다. 즉, 위 문단의 예시에서 “The capital of”라는 사람이 직접 입력해 특정 토큰들로 구성된 hard prompt 대신 soft prompt를 학습하여 동일한 수도 찾기를 수행하는 것입니다. 이 prompt tuning의 경우, 모델 전체 파라미터를 변경하지 않아 태스크별 추가 공간이 많이 필요하지 않고, hard prompt를 사용하는 것에 비해 준수한 성능을 얻을 수 있습니다.
✍️ 이전 스터디 자료 보기
2023.04.13 - [AI CONNECT] - GPT Inference 전략: '노트북으로 GPT 맛보기' AI 경진대회 연습제출 스터디 자료
GPT Inference 전략: '노트북으로 GPT 맛보기' AI 경진대회 연습제출 스터디 자료
안녕하세요, AI CONNECT 입니다. AI CONNECT에서는 종료된 경진대회더라도, 누구나 종료된 대회의 과제의 풀고 결과를 제출할 수 있는 연습 제출 기능을 오픈했습니다. 연습 제출이기 때문에 기존의
blog.mnc.ai
'MNC Inside > AI CONNECT' 카테고리의 다른 글
| Fake or Real: AI 생성 이미지 판별 경진대회🤔 접수 시작! (0) | 2023.05.24 |
|---|---|
| [EVENT] 중요한 건 꺾이지 않는 연습! (0) | 2023.04.28 |
| GPT Inference 전략: '노트북으로 GPT 맛보기' 연습제출 스터디 자료 (0) | 2023.04.13 |
| 지난 대회 문제로 실력 점검! AI CONNECT 연습제출 과제 오픈📢 (0) | 2023.03.31 |
| 노트북으로 GPT 맛보기💻 경진대회 오픈 (0) | 2023.03.07 |