MNC는 ChatGPT 기반 검색 솔루션 딥서핑(Deep Searfing)의 자연어 처리 기술과 MLOps상의 ML 플랫폼 기술을 더한 LLMOps(Large Language Model Operations)를 개발하고 있는데요. 총 3편에 걸친 이번 시리즈 'LangChain의 모든 것'에서는 MNC는 LLM 레벨의 워크플로우 구성을 누구나 쉽게 할 수 있도록 지원하는 라이브러리인 LongChain에 대해 소개하고자 합니다. 오늘 소개해드릴 내용은 LangChain의 구성 요소에 대해 자세하게 살펴볼 수 있는 포스트로, 시리즈의 두 번째 글입니다.
🗒️ 1편 보러가기:
[LLMOps] LangChain의 모든 것 (1) 개요와 컨셉
“5일만에 사용자 100만명 달성" ChatGPT의 성공을 가장 잘 나타내는 말이 아닐까 싶은데요. 메타의 SNS인 Thread를 제외하고는 단기간에 가장 많은 사용자 모집에 성공한 사례이며, 이 기록은 당분간
blog.mnc.ai
작성: 마인즈앤컴퍼니 이강산 매니저 (Data Sceintist)
LangChain에서는 앞 장에서 설명한 기능을 구현하기 위해 아래 7 종류의 모듈을 제공하고 있습니다. 각각의 모듈은 독립적으로 사용할 수 있게 설계되었습니다.
- Model I/O: LM을 위한 인터페이스
- Data connection: 특정 어플리케이션 데이터를 위한 인터페이스
- Chains: 서비스 시퀀스 구성
- Agents: 고수준의 목적에서 Chain이 어떤 tool들을 사용하게 함
- Memory: 어플리케이션의 여러 Chain 실행건에서 상태 유지
- Callbacks: 모든 Chain의 중간 단계에서 로깅 등
Model I/O
LLM은 아주 다양한 일을 처리할 수 있는 것처럼 보이기 때문에 모델 예측에 사용하는 입력 파라미터도 복잡할 것이라 생각할 수 있습니다. 하지만 사실 최근의 Generative Pretrained Transformer (GPT) 모델은 텍스트를 입력으로 텍스트를 생성하는 아주 단순한 기저를 갖고 있습니다. 즉, 일반적으로 생각하는 GPT 모델의 복잡한 산출물은 결국 입력 텍스트를 어떻게 구성하느냐에 달려 있으며 이 작업을 프롬프팅(prompting)이라고 합니다. 이렇게 프롬프트에 지시문을 담아 특정 task를 수행하도록 학습한 모델을 Instruction GPT 라고 하며 ChatGPT도 이 중 하나입니다. LangChain에서는 이러한 일련의 작업을 위해 모델과 그 입출력 구성을 Model I/O 모듈에서 제공합니다.
- Prompts: 모델에 입력되는 텍스트를 어떻게 구성할지 설정
- Language models: (대규모) 언어 모델 인터페이스
- Output parsers: 의도한 형식의 출력이 나오도록 검증
Prompts
ChatGPT에 역할을 부여하면 성능이 좋다던지, 예시를 보여주면 더 정확한 결과를 낸다던지 하는 얘기를 들어보신 적이 있을 것입니다. 모델이 무엇을 할지는 모두 프롬프트에 의해 결정되며 같은 목적을 갖고 있어도 어떻게 프롬프트를 구성하느냐에 따라 결과는 천차만별입니다. 최근 프롬프트 엔지니어라는 직군이 생겨난 이유이기도 합니다.
LangChain에서는 기본적인 프롬프팅을 위한 기능들을 제공합니다. 대표적인 기능들만 아래 예시를 통해 살펴보겠습니다.
# 작업 지시
주어진 단어에 대해 반의어를 만드세요.
# 출력 형식 지시
출력은 아래 스키마를 갖는 JSON 형식 이어야 합니다.
{
"properties": {
"input": {
"title": "Input",
"description": "given word",
"type": "string"
},
"antonym": {...}
},
"required": ["input", "antonym"]
}
# 예시문
예시는 아래와 같습니다.
{"input": "happy", "antonym": "sad"}
{"input": "tall", "antonym": "short"}
{
"input": "cool",
"antonym": <- 모델이 hot 을 채움
LangChain에서 제공하는 일반적인 prompting 과정을 거치면 왼쪽과 같은 프롬프트가 만들어지게 됩니다. (실제보다 간소화된 버전이며 주석은 설명을 위해 임의로 추가하였습니다)
- 작업 지시: 프롬프트를 사용하지 않을 경우 사용자가 주로 직접 입력하는 내용이며, PromptTemplate으로 제공합니다.
- 출력 형식 지시: OutputParser를 프롬프트에 지시문으로 포함할 수 있으며, 아래와 같이 Pydantic의 BaseModel 클래스로 JSON 스키마를 지정하기도 합니다.
class Antonym(BaseModel):
adjective: str = Field(description="given word")
antonym: str = Fi- 예시문: 좀 더 의도와 형식에 맞는 출력을 생성하기 위해 ExampleSelector를 제공하여 예시를 리스트 형태로 제공하거나 길이 기반으로 몇 개의 예시를 쓸지 정하는 등의 기능을 제공합니다.
이외에도 채팅 형식으로 Human, AI, System의 역할을 나누어 프롬프팅 하거나, 입력과의 유사도를 통해 적절한 예시를 선택하는 등의 기능도 제공합니다.
Language Models
LangChain에서는 모델 인터페이스를 LLM과 Chat model 두 형태로 제공합니다. 이 둘은 비슷하지만 API 제공 형식에서 가장 큰 차이가 있으며, 특히 최근 sLLM 모델에서는 text completion을 잘하는 모델과 채팅 형식의 어조를 쓰는 모델을 따로 학습하기도 합니다.
- LLMs: 문자열을 입력으로 받아 문자열을 출력하는 모델. LangChain에서는 LLM의 서빙을 따로 지원하지는 않으며, 다양한 LLM과 호환되는 표준 인터페이스를 제공합니다.
- Chat models: Chat Messages를 받아 채팅 메시지를 출력하는 형태의 모델.
모델 예측을 위해 __call__ 외에도 run, apply, generate, predict 등 입출력 형태가 조금씩 다른 다양한 메서드를 지원합니다.
코드에서 메모리로 직접 모델을 로드하여 쓸 수 있도록 custom 모델 wrapper를 지원하며, 비동기 예측, 출력 스트리밍, 캐싱, 비용 산정을 위한 토큰 사용 추적 등의 기능을 지원합니다.
Output Parser
LM의 출력을 단순 텍스트가 아닌 임의의 형식을 갖춘 데이터로 만들기 위해 사용하며, prompt에 지정한 대로 출력을 유도하는 지시문을 삽입하는 get_format_instruction과 텍스트 형식의 출력을 미리 지정한 형식으로 변환하는 parse 함수를 제공합니다.
List, Datetime, Enum, Pydantic처럼 다양한 방식으로 형식을 지정할 수 있으며, 의도하지 않은 출력에 대해 재시도를 하거나 LM을 이용하여 수정을 하는 기능도 제공합니다.
Data connection
LLM의 입력과 출력은 모두 단순 문자열이지만, 대부분의 실제 어플리케이션 데이터는 다양한 형태를 갖습니다. LangChain은 이러한 데이터를 로드, 변환, 저장 및 질의 하는 기능을 제공합니다.
LangChain에서는 문서에서 읽은 텍스트를 Document라는 객체로 관리를 하며, Document는 문자열과 메타데이터를 갖습니다.
- Document loaders: 다양한 소스로부터 데이터 로드
- Document transformers: Document를 분할, Q&A 포맷으로 변환, 중복 제거 등
- Text embedding models: 문자열 임베딩 (실수 벡터로 변환)
- Vector stores: 임베딩 데이터의 저장 및 검색
- Retrievers: 데이터 질의
Document Loaders
파일 경로를 지정하여 데이터를 읽습니다. csv, html, json, markdown, pdf 등 파일 형식별 loader를 제공하는 것 외에도 경로를 지정하여 읽을 수도 있습니다.
Document Transformers
큰 Document를 의미 있는 작은 단위(주로 문장)로 나누거나 토큰 크기에 맞추어 병합을 수행합니다. 문맥 유지를 위해 overlap을 만들기도 하며 일반적인 줄글에는 RecursiveCharacterTextSplitter의 사용이 권장됩니다. 특정 문자(\\n 등) 기준으로 나누거나 소스코드의 경우 언어별 나누는 기준이 있기도 하며, markdown 문서를 위한 splitter도 제공합니다. 또한 검색 결과로 나온 문장들을 유사도 기반으로 재정렬하는 기능도 제공합니다.
Text embedding models
문자열이나 Document 객체를 임베딩하기 위한 외부 API와 연동하는 기능을 제공합니다.
Vector stores
임베딩 벡터와 벡터스토어는 자연어 분야에서 문자열을 저장하고 검색하는데 가장 많이 쓰이는 방식 중 하나입니다. LangChain에서는 벡터스토어 객체를 제공하여 문자열이나 Document 객체, 또는 실수 벡터를 이용해 저장 및 검색을 할 수 있습니다.
Retrievers
문자열을 벡터화하고 벡터 유사도 기반으로 유사 문장을 추출하는 방법이 가장 많이 쓰이곤 있지만, 특히 범용 목적을 가진 모델을 특정 분야에서 사용할 경우 아래 그림과 같이 정밀도가 떨어지는 경우가 많으며, 이는 입력 문장이 약간만 바뀌어도 검색 결과가 크게 바뀌는 결과로 이어집니다.
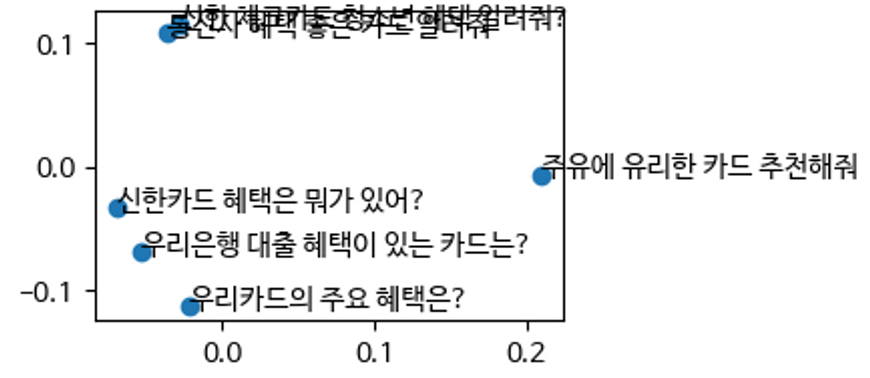 범용 목적의 Vicuna-13B 모델의 임베딩 결과 |
 금융 데이터에 특화된 DPR 모델의 임베딩 결과 |
LangChain에서는 이러한 문제를 해결하고 검색 성능을 높이기 위해 검색기 객체를 제공합니다. 검색기는 문자열을 이용한 검색에 특화되어 있으며 벡터스토어 외의 backbone을 사용할 수도 있습니다.
LM을 이용하여 사용자가 입력한 질의문과 유사한 질의문을 생성하거나, 검색기를 여러개 사용하여 앙상블 기법을 적용하기도 합니다. 또한 벡터스토어의 메타를 이용한 필터링이나, 최신 결과에 가중치를 부여할 수도 있으며, LM을 이용하여 한번 더 필터링/압축을 하거나, 중복 Document를 제거하거나, 웹 검색 결과를 보여주는 등 다양한 기능을 제공합니다.
Chains
LangChain에서는 LLM으로 간단한 출력만 얻는 기능 외에 프롬프팅이나 채팅 이력 관리, 서비스 플로우 분기 등 더 복잡한 어플리케이션의 구성을 위해서 Chain을 제공합니다. Chain은 하위 컴포넌트들을 순차적으로 호출하며 Chain 자체가 다른 Chain의 하위 컴포넌트가 될 수도 있습니다.
언어 모델을 사용하는 가장 간단한 LLMChain은 LLM과 프롬프트를 이용하며, ConversationChain은 LLM과 메모리를 이용합니다. 그 외에도 API 호출을 위한 APIChain, QA 관련 Chain들, SQL이나 VectorDB와 연동을 위한 Chain, 요약이나 편향성 이슈 대처를 위한 Chain 등 다양하게 지원하며, 필요한 Chain은 직접 만들 수도 있습니다.
Chain은 비동기 호출을 지원하고 다양한 출력 형태를 설정할 수 있으며, JSON으로 저장이 가능하기 때문에 LangChainHub에서 불러와서 사용도 가능하지만 아직까지 그리 활성화 되어 있지는 않은 것으로 보입니다.
서비스 로직 구현을 위한 플로우 제어 체인으로는 Chain을 순차적으로 연결하는 SequentialChain과 동적으로 다음 체인을 어떤 것을 사용할지 결정하는 RouterChain이 있습니다. RouterChain에서는 연결된 Chain 중 어느 경로를 선택할지를 LM 또는 임베딩 모델과 다음 체인의 description을 이용해 결정하며, 이것이 LangChain의 워크플로우 구성의 가장 큰 특징일 것으로 보입니다.
추가적으로 파이썬 함수 기반의 데이터 변환을 위한 TransformChain도 지원하며, Document 기반의 LM 질의를 위한 context 구성을 위해 아래의 Chain을 제공합니다.
- Stuff: 여러 Document를 단순히 쌓아서 context를 구성합니다.
- Refine: 각 Document를 하나씩 context로 주고, 이전 스텝의 출력을 같이 보여줘서 출력이 점점 정제되도록 구성합니다. 여러 Document에 정보가 분산되어있을 경우 부적합합니다.
- Map reduce: 각 Document에 대해 LM 질의를 수행 후 LM으로 결과를 요약합니다.
- Map re-rank: 각 Document에 질의를 수행하며 score를 같이 산출하게 하고 가장 높은 점수를 반환합니다.
Memory
채팅 이력을 관리하는 경우
Human: 사과는 무슨 색이야?
AI: 빨간색입니다.
Human: 그럼 바나나는?
AI: 노란색입니다.
채팅 이력을 관리하지 않는 경우
Human: 사과는 무슨 색이야?
AI: 빨간색입니다.
Human: 그럼 바나나는?
AI: 바나나는 열대 과일의 하나로...
LLM은 기본적으로 상태를 관리하지 않으며, 대화형 서비스를 위해서는 별도의 채팅 이력 관리와 채팅 이력의 프롬프팅 기능이 필요합니다. LangChain에서는 다양한 memory 타입을 제공하여 자동으로 LLM의 출력을 저장하고 이후 입력에 채팅 이력을 추가합니다.
메모리는 Chain이나 Agent에 연결해 사용하며, 여러 메모리를 동시에 사용하거나 채팅 이력의 사용자 이름을 변경하는 등의 기능을 지원하고, 커스텀 클래스로 세션을 관리하는 등의 기능도 직접 구현할 수 있습니다. 또한 다양한 외부 DB와 연동을 지원합니다.
LangChain에서는 아래와 같은 다양한 메모리 타입을 제공합니다.
- ConversationBufferMemory: 채팅 이력을 쌓아서 저장합니다.
- ConversationBufferWindowMemory: 최근 K개만 저장합니다.
- ConversationSummaryMemory: 채팅 이력이 쌓일 때 LLM으로 요약하여 저장합니다.
- ConversationTokenBufferMemory: 최근 K가 아니고 토큰 개수 기준으로 저장합니다.
- ConversationSummaryBufferMemory: 요약과 최근 이력(토큰 기준)을 같이 제공합니다.
- EntityMemory: LLM을 이용하여 entity와 관련 정보를 인식하여 저장합니다.
- ConversationKnowledgeGraphMemory: 위와 유사하지만 Knowledge Triplet형태로 저장합니다.
- VectorstoreBackendMemory: 채팅 시 임베딩, 벡터스토어에 저장하고 유사 문장을 불러옵니다.
Agents
Chain이 기능 단위로 서비스를 구성한다면, 특정 도메인에 특화하거나 더 고수준의 어플리케이션을 구성하기 위해 LangChain은 Agent를 제공합니다. Chain에서는 작업 순서가 고정이지만 Agent는 매 단계마다 다음 작업(Agent의 호출이나 툴의 사용)을 LM과 프롬프트를 이용하여 결정합니다.
LangChain의 Agent에서는 다음 작업의 더 나은 결정을 위해 ReAct 기법을 사용하거나, 툴의 입력 스키마를 보고 알맞은 데이터를 출력하거나, 미리 모든 작업 순서를 결정하거나, 검색을 강제하는 등의 기능을 제공합니다. 또한 대화형 Agent 나 Python 코드를 실행하는 Agent 등을 미리 구성하여 제공하기도 합니다.
Tool & Toolkit
LangChain에서는 Agent가 호출할 수 있는 유용한 함수들을 툴의 형태로 제공합니다. Agent는 LLM을 이용하여 툴의 이름과 설명, 입력 스키마를 보고 사용여부와 순서, 입력 데이터 형태를 결정합니다. 보통 3~5개의 툴을 묶어서 툴킷으로 제공하는데 예로 Gmail 툴킷에는 내부적으로 createDraft, sendMessage, search, getMessage, getThread툴이 존재합니다.
다양한 외부 API, DB, 파일 형식을 지원하는 연동 툴과 사용자 인터렉션을 받는 Human-in-the-loop 툴도 제공하며 커스텀 툴도 추가 가능합니다.
Agent와 Tool 관련하여 아주 많은 내용이 있지만, 이는 기본 기능 이라기 보다는 특정 어플리케이션을 구성하는 방법으로 상세한 내용은 본 글에서 다루지 않으니 공식 문서를 참조하시길 바랍니다.
LLM을 이용하여 어플리케이션을 제공하는 수준의 레벨에서는 커스텀 Agent와 커스텀 툴킷을 활용합니다.
Callbacks
LangChain은 LLM 어플리케이션의 다양한 실행 단계에서 동작하는 콜백 함수를 제공합니다. LLM, Chain, Tool, Agent 등의 시작, 종료 및 에러 발생 시 실행되며 이를 이용하여 로깅 · 모니터링, 토큰 count 등을 수행할 수 있습니다. 선언 시 콜백을 지정하지 않았어도 호출 시에 콜백을 전달하여 이후 단계에서 사용할 수 있으며, 비동기 기능이나 런타임에서 콜백 중 일부만 선택할 수 있는 tag 기능, 외부 프레임워크와 연동할수 있는 콜백도 제공합니다.
Other Features
Evaluation
LLM에서 평가는 수치적으로 나타내기가 힘들고 모호한 요소입니다. LangChain은 최근 LLM의 성능 평가 뿐만 아니라 Agent로 구성한 어플리케이션의 성능 평가를 위한 기능을 추가하고 있고 현재는 아래의 세 기능을 제공합니다.
- String Evaluator: 입력 문자열에 대한 출력을 기준 문자열과 비교하여 평가합니다.
- Trajectory Evaluator: Agent의 실행 경로를 평가합니다.
- Comparison Evaluator: 입력 문자열에 대해 여러 출력을 얻어 비교하여 평가합니다.
Ethical
LM 서비스를 운영할 때 부적절한 콘텐츠를 생성하는 것은 꼭 해결해야 할 문제이며 LangChain에서는 이를 위해 편향되거나 폭력적인 답변을 내지 않게 프롬프팅을 하거나 LLM으로 한번 더 검사를 하는 기능을 제공합니다.
여기까지 LangChain의 기본 모듈 및 기타 기능을 살펴보았습니다. 여기에 포함되지 않은 내용도 있고 LangChain의 업데이트 빈도는 매우 빠르기 때문에 새롭게 추가될 내용이 많겠지만, 주요한 기능에 대한 설명은 마친 듯 합니다.
다음 장에서는 실습을 통해 LangChain의 기본 사용법을 익혀보겠습니다.
'AI 솔루션 > LLMOps' 카테고리의 다른 글
| [LLMOps]LangChain 소개 (3) - 활용 사례 및 실습 (0) | 2023.08.16 |
|---|---|
| [LLMOps] LangChain의 모든 것 (1) 개요와 컨셉 (0) | 2023.08.08 |