MNC는 ChatGPT 기반 검색 솔루션 딥서핑(Deep Searfing)의 자연어 처리 기술과 MLOps상의 ML 플랫폼 기술을 더한 LLMOps(Large Language Model Operations)를 개발하고 있는데요. 총 3편에 걸친 이번 시리즈 'LangChain의 모든 것'에서는 MNC는 LLM 레벨의 워크플로우 구성을 누구나 쉽게 할 수 있도록 지원하는 라이브러리인 LongChain에 대해 소개하고자 합니다.
오늘 소개해드릴 내용은 지금까지 다뤘던 Lang Chain과 컨셉과 구성 요소를 바탕으로, 실제로 LangChain을 이용해 어플리케이션을 구성해보는 실습을 다뤄보려 합니다. LangChain의 활용 사례까지 전달해드리는, 이번 시리즈의 마지막 글입니다.
🗒️ 1편 보러가기: https://blog.mnc.ai/68
[LLMOps] LangChain의 모든 것 (1) 개요와 컨셉
“5일만에 사용자 100만명 달성" ChatGPT의 성공을 가장 잘 나타내는 말이 아닐까 싶은데요. 메타의 SNS인 Thread를 제외하고는 단기간에 가장 많은 사용자 모집에 성공한 사례이며, 이 기록은 당분간
blog.mnc.ai
🗒️ 2편 보러가기:https://blog.mnc.ai/69
[LLMOps] LangChain의 모든 것 (2) 구성 요소
MNC는 ChatGPT 기반 검색 솔루션 딥서핑(Deep Searfing)의 자연어 처리 기술과 MLOps상의 ML 플랫폼 기술을 더한 LLMOps(Large Language Model Operations)를 개발하고 있는데요. 총 3편에 걸친 이번 시리즈 'LangChain의
blog.mnc.ai
작성: 마인즈앤컴퍼니 이강산 매니저 (Data Scientist)
LangChain 활용 사례는 링크를 통해 소개합니다.
- https://python.langchain.com/docs/use_cases
- https://blog.langchain.dev/
- https://github.com/kyrolabs/awesome-langchain
실습
지금까지 LangChain이 제공하는 다양한 모듈에 대해 살펴보았습니다. 이번에는 실제로 몇 가지 간단한 LangChain 어플리케이션을 구성해보겠습니다.
먼저 실습이기 때문에 전역적으로 verbose 설정을 하겠습니다. 각 모듈이나 Chain 마다 verbose 설정을 할 수도 있으며, 더 많은 정보를 볼 수 있는 debug 모드로 설정을 할 수도 있지만 출력이 너무 많아 사용하지는 않겠습니다.
import langchain
langchain.verbose = True
# langchain.debug = True
LLM
가장 기본이 되는 LLM 모델을 선언하겠습니다. OpenAI의 API Key를 담고 있는 OPENAI_API_KEY는 미리 선언해 두었으며, 동명의 환경 변수를 설정해두면 따로 전달하지 않아도 됩니다.
# OpenAI LLM
from langchain.llms import OpenAI
llm_openai = OpenAI(openai_api_key=OPENAI_API_KEY)
모델을 메모리에 로드하여 사용하는 커스텀 LLM도 미리 선언해 두겠습니다. 여기서 주의할 점은, 일반적으로 멤버 변수 사용을 위해 __init__안에서 선언 및 초기화 하는 것과 달리, LangChain의 LLM base에서는 클래스 변수를 이용하여 선언하고 root_validator 데코레이터를 이용해 초기화합니다.
from langchain.llms.base import LLM
from typing import Any
from pydantic import root_validator, Field
class LocalLLM(LLM):
model_name: str = Field('', alias='model_name')
model: Any = None
tokenizer: Any = None
last_query: str = ''
last_response: str = ''
@root_validator()
def validate_environment(cls, values: dict) -> dict:
model, tokenizer = huggingface_api.load_model(
values['model_name'],
device='cuda',
num_gpus=1,
max_gpu_memory=None,
load_8bit=False,
cpu_offloading=False,
revision='main',
debug=True,
)
values['model'] = model
values['tokenizer'] = tokenizer
return values
@property
def _llm_type(self):
return "vicuna"
def _call(self, prompt, stop=None, run_manager=None, temperature=0.7):
self.last_query = prompt
input_ids = self.tokenizer([prompt]).input_ids
output_ids = self.model.generate(
torch.as_tensor(input_ids).cuda(),
do_sample=True,
temperature=temperature,
repetition_penalty=1.0,
max_new_tokens=512,
)
# Convert output
output_ids = output_ids[0] if self.model.config.is_encoder_decoder else output_ids[0][len(input_ids[0]):]
self.last_response = self.tokenizer.decode(output_ids,
skip_special_tokens=True,
spaces_between_special_tokens=False)
return self.last_response
llm_custom = LocalLLM(model_name='lmsys/vicuna-13b-v1.3')
실제로는 메모리에 직접 모델을 로드하지 않고 다른 서빙 툴을 이용하는 경우가 많습니다. 보통 OpenAI의 API 규격을 많이 사용하기 때문에 해당 api서버를 사용하면 LangChain과 간단하게 연동이 가능합니다. 아래는 서빙 툴 중 하나인 FastChat을 이용한 모델 서빙 과정을 나타냅니다.
# FastChat Controller
python3 -m fastchat.serve.controller --host '0.0.0.0' --port 9010
# FastChat Model Worker
python3 -m fastchat.serve.vllm_worker --host '0.0.0.0' --port 9011 --controller-address='<http://localhost:9010>' --model-path=lmsys/vicuna-13b-v1.3 --worker-address=http://localhost:9011
# FastChat OpenAI Api Server
python3 -m fastchat.serve.openai_api_server --host '0.0.0.0' --port 9012 --controller-address <http://localhost:9010>
이 경우, 아래와 같이 LLM을 선언합니다. custom이기 때문에 openai_api_key는 필요없지만, 비어있으면 에러가 발생하여 아무 값이나 입력해야 합니다.
llm_custom = OpenAI(model='vicuna-13b-v1.3',
openai_api_base='<http://192.168.74.188:9012/v1>',
openai_api_key='EMPTY')
OpenAI Embeddings
LangChain에서 문자열의 벡터화를 위햐 OpenAI의 embedding api를 사용하는 방법은 아래와 같습니다.
from langchain.embeddings import OpenAIEmbeddings
embedding_openai = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
vectors = embedding_openai.embed_documents(sentences)
Custom Embeddings
LangChain에서 커스텀 embedding 모델을 사용하는 방법이 공식 문서에 자세히 나와있지는 않지만, 어느 객체의 멤버 함수로 단건을 처리하는 embed_query와 여러 건을 처리하는 embed_documents가 있으면 어느 정도 호환되는 것을 확인했습니다.
from transformers import AutoModel, AutoConfig
from transformers import DPRContextEncoderTokenizer
class DPRModel:
def __init__(self, path):
self.model = AttrDict({
'model': AutoModel.from_pretrained(
os.path.join(path, 'query_encoder/language_model.bin'),
config=AutoConfig.from_pretrained(os.path.join(path, 'query_encoder/language_model_config.json'))).cuda(),
'tokenizer': DPRContextEncoderTokenizer.from_pretrained(os.path.join(path, 'query_encoder'))
})
def embed_query(self, text: str):
return self.embed_documents([text])[0]
def embed_documents(self, texts: list[str]):
inputs = self.model.tokenizer(texts, return_tensors='pt', padding=True, max_length=512, truncation=True).to('cuda')
outputs = self.model.model(**inputs)
return outputs.pooler_output.cpu().detach().numpy()
dpr_model = DPRModel('./dpr_model')Vector Store
다음으로는 임베딩한 문자열을 저장하고 검색하기 위해 LangChain의 벡터스토어 기능을 활용하여 Weaviate와 연동해보겠습니다. 아래 코드와 같이 프레임워크의 client와 LangChain Wrapper를 이용하며, CardBenefit과 query는 임의로 설정한 클래스와 key의 이름입니다.
import weaviate
client = weaviate.Client(url="<http://192.168.74.188:8080>")
from langchain.vectorstores import Weaviate
vs = Weaviate(client, 'CardBenefit', 'query', embedding=dpr_model, by_text=False)
실제 검색은 아래와 같이 수행합니다. 가독성을 위해 생략과 들여쓰기를 적용하였습니다.
# 가장 유사한 5개 문장 검색
vs.similarity_search_with_score('신한카드', k=5)
[Output]:
[
{ "doc": "신한카드 Hey Young 체크 ...(생략)",
"score": 67.48098693151945 },
{ "doc": "\\"'신협-신한카드 The Classic+' ...(생략)",
"score": 67.59093905132033 },
{ "doc": "신한카드 Deep Dream 체크 ...(생략)",
"score": 67.75639112554286 },
{ "doc": "\\"신한카드 The CLASSIC-Y\\" ...(생략)",
"score": 68.32537725546375 },
{ "doc": "\\"신한카드 봄\\" ...(생략)",
"score": 68.81305445088812 }
]
Retrieval QA
LangChain에서는 아래와 같이 검색 QA 기능을 간단하게 구현할 수 있습니다. 5개의 연관 Document를 검색하고 stuff 방식으로 쌓아서 llm_custom 모델로 질의를 수행합니다.
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm_custom,
chain_type="stuff",
retriever=vs.as_retriever(search_type='similarity', search_kwargs={"k": 5}),
verbose=True
)
answer = qa.run("캐시백 비율이 가장 높은 카드는?")
[Output]: '"oo카드"는 디지털 구독 결제금액에 대해 월 최대 1만원의 캐시백을 제공하여 가장 높은 캐시백 비율을 가지고 있습니다. 디지털 구독 서비스에 대해 결제한 것이 필요하며, 1회성 일반 구매 결제, 인앱 결제 등에 대해서는 캐시백 발급 반드시 할 수 없습니다.'
PDF Search

같은 원리로 PDF를 이용한 검색 질의 기능도 아래와 같이 구현할 수 있습니다. 위 MNC MLOps의 설명서 중에서 “주요 기능” 부분을 질의 해 보겠습니다.
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# PDF loader 선언, 이 외에도 PyPDFLoader, MathpixPDFLoader 등 다양한 loader 사용 가능
loader = UnstructuredPDFLoader("./MNC_MLOps_매뉴얼.pdf")
# 파일 읽고 20% 정도 overlap 되게 나누어 저장
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = loader.load_and_split(text_splitter=text_splitter)
# 각 document 벡터스토어에 저장
for doc in docs:
vector = llm_custom.embed_query(doc.page_content).tolist()
client.data_object.create(
data_object={'query': doc.page_content},
class_name='MLOpsManual',
vector=vector
)
# QA Chain 선언
qa = RetrievalQA.from_chain_type(
llm=llm_openai,
chain_type="stuff",
retriever=vs.as_retriever(search_type='similarity', search_kwargs={"k": 5}),
verbose=True
)
qa.run('주요 기능은?')
[Output]: ' 모델 개발 환경 관리, 모델 배포 및 관리, 모델 및 시스템 리소스 모니터링, 시스템 관리 및 운영 기능.'다만, 임베딩 모델이 범용 모델이기 때문에 MNC MLOps의 주요 기능은? 처럼 질의를 살짝 바꾸어도 원하는 결과가 나오지 않으며, 이는 OpenAI에서 제공하는 임베딩 모델을 사용해도 마찬가지인 결과를 얻었습니다. 이는 정확한 질의를 위해서는 해당 도메인에 맞게 학습된 임베딩 모델을 사용하거나, 질의문과 저장된 문자열에 풍부한 컨텍스트를 제공할 필요가 있다는 것을 보여줍니다.
SQL Database Chain
다음으로는 SQL 질의를 수행하는 SQLDatabaseChain을 사용해 보겠습니다. 아래처럼 사용할 테이블을 전달해야 프롬프트에 해당 테이블의 DDL(Data Definition Language)을 포함하고, LLM이 해당 정보를 보고 올바른 쿼리를 작성할 수 있게 됩니다. LLM으로 SQL 쿼리 작성 시 자주 발생하는 에러를 LLM으로 한번 더 체크하는 use_query_checker 옵션도 제공합니다.
from langchain import SQLDatabase, SQLDatabaseChain
url_mariadb = 'mysql+pymysql://llmops:password@127.0.0.1:32039/llmops'
db = SQLDatabase.from_uri(url_mariadb, include_tables=[
'dataset_tb', 'dataset_version_tb', 'dataset_version_file_tb'
])
chain = SQLDatabaseChain.from_llm(llm_openai, db, verbose=True, return_intermediate_steps=True)
chain("How many files in dataset TestUIAdd - Edited UI and version v2.6? and whats the sum of file sizes and row counts?")
[Output]: > Entering new chain...
"How many files in dataset TestUIAdd - Edited UI and version v2.6? and whats the sum of file sizes and row counts?"
SQLQuery: "SELECT COUNT(*) AS 'Number of Files', SUM(file_size) AS 'Sum of File Sizes', SUM(row_count) AS 'Sum of Row Counts' FROM dataset_version_file_tb WHERE dataset_id = (SELECT id FROM dataset_tb WHERE name = 'TestUIAdd - Edited UI') AND version_id = (SELECT id FROM dataset_version_tb WHERE dataset_id = (SELECT id FROM dataset_tb WHERE name = 'TestUIAdd - Edited UI') AND version = 'v2.6');"
SQLResult: "[(2, Decimal('1355'), Decimal('205'))]"
Answer:
"There are 2 files in dataset TestUIAdd - Edited UI and version v2.6, with a sum of file sizes of 1355 and a sum of row counts of 205."
> Finished chain.위와 같은 수준의 복잡도를 가진 쿼리는 vicuna-13b-v1.3 모델로는 수행이 잘 되지 않으며, 쿼리 에러 발생 시에는 SQL의 Syntax Error를 보게 됩니다. 아래는 LangChain의 SQL Agent로 간단한 쿼리의 질의를 보여줍니다. 아래 출력 부분에서 실행 과정을 잘 보여줍니다.
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.agents.agent_types import AgentType
db = SQLDatabase.from_uri(url, include_tables=['dataset_tb', 'dataset_version_tb'])
toolkit = SQLDatabaseToolkit(db=db, llm=llm_custom)
agent_executor = create_sql_agent(
llm=llm_custom,
toolkit=toolkit,
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
agent_executor.run("How many versions are there in dataset named 'TestUIAdd - Edited UI'")
출력:
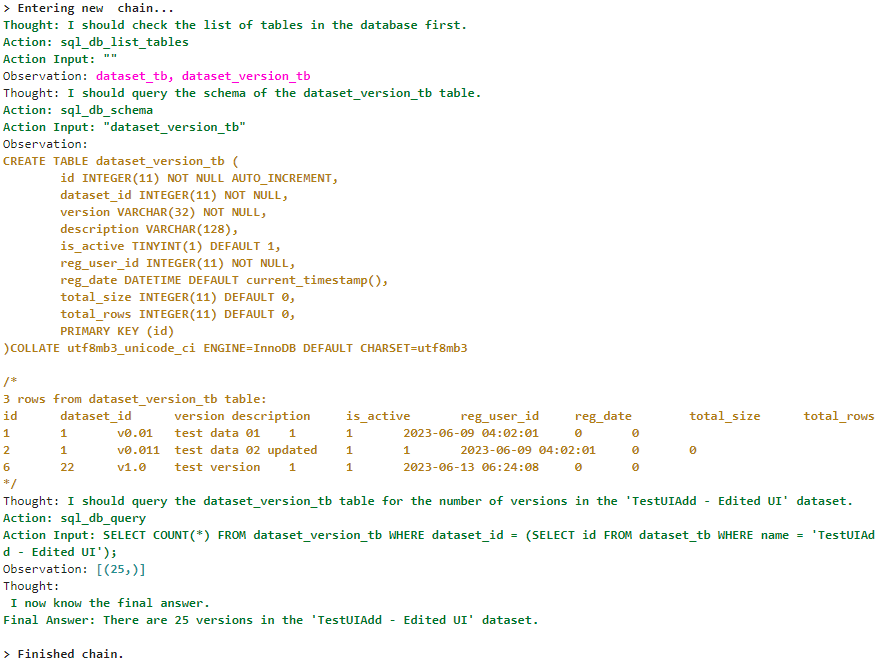
API Chain
LangChain에서는 API 설명서를 LLM으로 해석하여 자동으로 필요한 요청을 보내는 기능을 제공합니다. 공공데이터포털의 기상청 단기예보 조회서비스를 대상으로 해당 페이지의 설명을 그대로 복사하겠습니다.
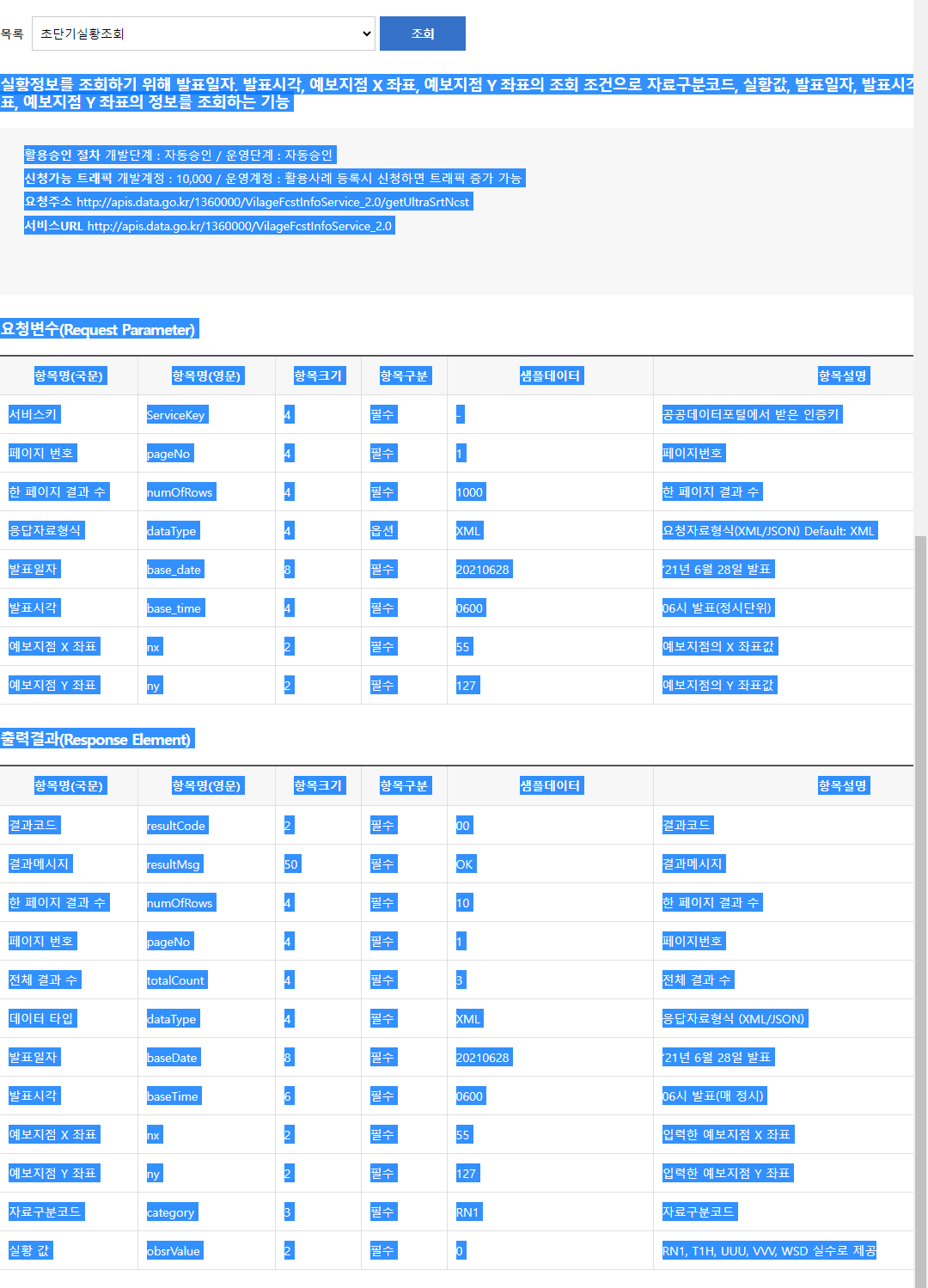
그 다음 변수 이름 설명이 나와있는 부분만 첨부 파일에서 따로 복사해 추가합니다.
api_docs = """
실황정보를 조회하기 위해 발표일자, 발표시각, 예보지점 X 좌표, 예보지점 Y 좌표의 조회 조건으로 자료구분코드, 실황값, 발표일자, 발표시각, 예보지점 X 좌표, 예보지점 Y 좌표의 정보를 조회하는 기능
초단기실황 T1H 기온 ℃ 10
RN1 1시간 강수량 mm 8
UUU 동서바람성분 m/s 12
VVV 남북바람성분 m/s 12
REH 습도 % 8
PTY 강수형태 코드값 4
VEC 풍향 deg 10
WSD 풍속 m/s 10
요청주소 http://apis.data.go.kr/1360000/VilageFcstInfoService_2.0/getUltraSrtNcst
서비스 URL http://apis.data.go.kr/1360000/VilageFcstInfoService_2.0
요청변수(Request Parameter)
항목명(국문) 항목명(영문) 항목크기 항목구분 샘플데이터 항목설명
서비스키 ServiceKey 4 필수 - 공공데이터포털에서 받은 인증키
페이지 번호 pageNo 4 필수 1 페이지번호
한 페이지 결과 수 numOfRows 4 필수 1000 한 페이지 결과 수
응답자료형식 dataType 4 옵션 XML 요청자료형식(XML/JSON) Default: XML
발표일자 base_date 8 필수 20210628 ‘21년 6월 28일 발표
발표시각 base_time 4 필수 0600 06시 발표(정시단위)
예보지점 X 좌표 nx 2 필수 55 예보지점의 X 좌표값
예보지점 Y 좌표 ny 2 필수 127 예보지점의 Y 좌표값
출력결과(Response Element)
항목명(국문) 항목명(영문) 항목크기 항목구분 샘플데이터 항목설명
결과코드 resultCode 2 필수 00 결과코드
결과메시지 resultMsg 50 필수 OK 결과메시지
한 페이지 결과 수 numOfRows 4 필수 10 한 페이지 결과 수
페이지 번호 pageNo 4 필수 1 페이지번호
전체 결과 수 totalCount 4 필수 3 전체 결과 수
데이터 타입 dataType 4 필수 XML 응답자료형식 (XML/JSON)
발표일자 baseDate 8 필수 20210628 ‘21년 6월 28일 발표
발표시각 baseTime 6 필수 0600 06시 발표(매 정시)
예보지점 X 좌표 nx 2 필수 55 입력한 예보지점 X 좌표
예보지점 Y 좌표 ny 2 필수 127 입력한 예보지점 Y 좌표
자료구분코드 category 3 필수 RN1 자료구분코드
실황 값 obsrValue 2 필수 0 RN1, T1H, UUU, VVV, WSD 실수로 제공
"""
from langchain.chains import APIChain
from datetime import datetime
today = datetime.now().strftime('%Y%m%d')
chain = APIChain.from_llm_and_api_docs(llm_openai, api_docs, verbose=True)
chain.run(f"""
(55,127) 좌표의 {today} 일자 6시 초단기 실황 온도를 JSON 타입으로 얻으면? 파라미터는 아래와 같음.
ServiceKey: 발급받은 키
""")
[Output]: > Entering new chain...
http://apis.data.go.kr/1360000/VilageFcstInfoService_2.0/getUltraSrtNcst?ServiceKey=발급키&pageNo=1&numOfRows=1&dataType=JSON&base_date=20230807&base_time=0600&nx=55&ny=127&category=T1H
{"response":{"header":{"resultCode":"00","resultMsg":"NORMAL_SERVICE"},"body":{"dataType":"JSON","items":{"item":[{"baseDate":"20230807","baseTime":"0600","category":"PTY","nx":55,"ny":127,"obsrValue":"0"}]},"pageNo":1,"numOfRows":1,"totalCount":8}}}
> Finished chain.
' (55,127) 좌표의 20230807 일자 6시 초단기 실황 온도는 0℃입니다.'API 설명서에서 제공하지 않는 ServiceKey 정보만 프롬프트에 따로 제공하였고, verbose=True로 하여 실제 주소와 응답 값을 볼 수 있습니다. 온도 값은 이상하긴 하지만 정상적으로 API 요청을 구성해서 값을 얻어왔음을 확인할 수 있습니다.
LLM Chain
마지막으로 실제 사용 예제를 통해 가장 기본적인 LLMChain과 prompt, output parser의 사용법을 알아보겠습니다.
특정 분야에서 잘 동작하는 sLLM을 학습하거나 파인튜닝 하기 위해서는 해당 분야에서의 데이터셋이 많이 있어야 합니다. 그러나 해당 분야에 특화된 데이터셋은 찾기가 힘들고, 직접 만들려고 해도 사람이 직접 해야 하고 해당 분야에 대한 지식도 있어야 하기 때문에 큰 비용이 요구됩니다.
따라서 LLM을 통한 데이터셋의 증강과 평가를 많이 사용하며, 이 과정을 LangChain으로 구성해 보겠습니다.
Prompt
해당 프로세스는 답변 생성 → 추가 질문 생성 → 생성된 질문 평가 의 작업을 수행하는 세 Chain으로 구성할 수 있습니다. 이를 위해 각 Chain의 프롬프트를 구성합니다.
prompt_answer = """
사용자 질문: {user_query}
단락:
- {ref1}
- {ref2}
- {ref3}
위 사용자 질문에 대해 주어진 단락에 있는 정보에 기반하여 답변을 생성해주세요. 답변은 4~5 문장 길이의 한국어로 구체적으로 생성해주세요.
답변:
""".strip()
prompt_question = """
system: 당신은 사용자의 질문에 대해 주어진 단락에 있는 정보에 기반하여 답변을 생성해줍니다. 단락:
- {ref1}
- {ref2}
- {ref3}
user: 사용자의 질문: {user_query}
assistant: {answer}
추가로 궁금하신 점이 있으신가요?
user: 위 대화에 이어지는 추가 질문을 생성해주세요. 질문에 대한 응답은 생성하지 마세요. 추가 질문:
""".strip()
prompt_evaluation = """
[사용자의 프롬프트]
{user_query}
[사용자의 프롬프트 끝]
[참고 문단 1의 시작]
{ref1}
[참고 문단 1의 끝]
[참고 문단 2의 시작]
{ref2}
[참고 문단 2의 끝]
[참고 문단 3의 시작]
{ref3}
[참고 문단 3의 끝]
[어시스턴트 1의 대답 시작]
{answer}
[어시스턴트 1의 대답 끝]
[시스템]
어시스턴트 1의 대답 성능을 평가해주세요.
{format_instructions}
""".strip()Output Parser
위 프롬프트를 이용하여 각각의 Chain을 구성합니다. 평가를 위한 Chain에서는 출력 형식을 지정하여 자동화 될 수 있도록 합니다.
from langchain import PromptTemplate, LLMChain
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
answer_chain = LLMChain(
llm=llm_custom,
prompt=PromptTemplate.from_template(prompt_answer),
output_key='answer',
)
gen_question_chain = LLMChain(
llm=llm_openai,
prompt=PromptTemplate.from_template(prompt_question),
output_key='question',
)
class Answer(BaseModel):
score: int = Field(description="score of the answer in range of 1 to 10")
reason: str = Field(description="detailed reason for the score")
parser = PydanticOutputParser(pydantic_object=Answer)
evaluation_chain = LLMChain(
llm=llm_openai,
prompt=PromptTemplate(
template=prompt_evaluation,
input_variables=['user_query', 'ref1', 'ref2', 'ref3', 'answer'],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
)
다음으로는 실제로 문서 검색과 Chain을 실행해보겠습니다. 이번에는 RetrieverQA Chain을 사용하지 않고 벡터스토어만으로 검색을 수행하겠습니다.
query = '해외 ㅇ여행 무료 여행자보험 혜택이 있는 카드 있을까요?'
docs = vs.similarity_search_with_score(query, k=3)
answer = answer_chain({
'user_query': query,
'ref1': docs[0].page_content,
'ref2': docs[1].page_content,
'ref3': docs[2].page_content
})
[Output]: > Entering new chain...
Prompt after formatting:
사용자 질문: 해외 여행 모두 무료 여행자보험 혜택이 있는 카드 있을까요?
단락:
- 우리카드 프리미엄 프리미엄 투어 서비스 - 카드의정석 PREMIUM SKYPASS. 1. 국내외 여행 보험 무료 제공. 2. 해외여행, 국내여행, 휴일교통상해, 골프보험 등. 3. 해외여행 시, 전액 결제 시 보상 가능. 4. 전 세계 유명 박물관-미술관 입장권 할인. 5. 50% 할인, 1회당 1만원, (연 3회, 월 1회). 6. 국내호텔/리조트/카라반/글램핑 2박 연박 시 1박 무료. 7. 제주도 렌터카 48H/24H 무료 제공. 8. KTX/SRT 왕복 승차권 10% 할인, 일반석, 연 2회. 9. 프리미엄 투어 서비스: 국내외 여행 상세 내용 우리카드 홈페이지 참조.
- 카드의정석 PREMIUM MILEAGE(AsianaClub) - 우리카드 프리미엄 투어 서비스. 국내외 여행 보험 무료 제공, 유명 박물관·미술관 입장권 적용해서 50% 청구 할인. 국내호텔, 리조트, 카라반, 글램핑 2박 연박 시 1박 무료, 제주도 렌터카 48H / 24H 무료 제공, KTX / SRT 왕복 승차권 10% 할인. 프리미엄 투어 서비스 예약 시에만 제공.
- [클럽 SK(하나카드 기타)] 면세점 서비스 - 상품 구매 시 할인, VIP 멤버십 제공(Silver 등급), 매장 최초 방문 시 멤버십 실버카드 발급, 신라면세점에서만 적용, 홈페이지 참조, [하나은행 결제 계좌 고객 우대 서비스] - 전자금융 수수료 면제 10회, 환전 수수료 50% 우대, [Smarⓣ 여행서비스] - 국내외 여행 혜택 제공, 예약전화 1599-5151.
위 사용자 질문에 대해 주어진 단락에 있는 정보에 기반하여 답변을 생성해주세요. 답변은 4~5 문장 길이의 한국어로 구체적으로 생성해주세요.
답변:
> Finished chain.
Answer: 우리카드 프리미엄 프리미엄 투어 서비스는 해외 여행 모두 무료 여행자보험 혜택을 제공합니다. 국내외 여행 보험 무료, 해외 여행, 휴일 교통 상해 등을 포함한 다양한 보험 혜택을 제공합니다. 또한, 전액 결제 시 보상 가능하며, 전 세계 유명 박물관-미술관 입장권 할인 및 국내호텔/리조트/카라반/글램핑 2박 연방 1박 무료 등의 할인 혜택을 제공합니다. 참고하시기 바랍니다.
다음으로는 검색 결과와 생성한 답변을 이용하여 새로운 질문을 생성해보겠습니다.
generated_question = gen_question_chain({
'user_query': query,
'answer': answer['answer'],
'ref1': docs[0].page_content,
'ref2': docs[1].page_content,
'ref3': docs[2].page_content
})
[Output]: > Entering new chain...
Prompt after formatting:
system: 당신은 사용자의 질문에 대해 주어진 단락에 있는 정보에 기반하여 답변을 생성해줍니다. 단락:
- 우리카드 프리미엄 ...(생략)
- 카드의정석 PREMIUM ...(생략)
- [클럽 SK(하나카드 기타)] ...(생략)
user: 사용자의 질문: 해외 여행 모두 무료 여행자보험 혜택이 있는 카드 있을까요?
assistant: 우리카드 프리미엄 프리미엄 투어 서비스는 해외 여행 모두 무료 여행자보험 혜택을 제공합니다. 국내외 여행 보험 무료, 해외 여행, 휴일 교통 상해 등을 포함한 다양한 보험 혜택을 제공합니다. 또한, 전액 결제 시 보상 가능하며, 전 세계 유명 박물관-미술관 입장권 할인 및 국내호텔/리조트/카라반/글램핑 2박 연방 1박 무료 등의 할인 혜택을 제공합니다. 참고하시기 바랍니다.
추가로 궁금하신 점이 있으신가요?
user: 위 대화에 이어지는 추가 질문을 생성해주세요. 질문에 대한 응답은 생성하지 마세요. 추가 질문:
> Finished chain.
Generated question: 해외 여행 시 어떤 보험 혜택이 있나요?
마지막으로 다시 생성된 질문에 대한 답변을 생성하고 평가 Chain을 이용해 점수를 매기겠습니다.
regen_answer = answer_chain({
'user_query': generated_question['question'],
'ref1': docs[0].page_content,
'ref2': docs[1].page_content,
'ref3': docs[2].page_content
})
evaluation_result = evaluation_chain({
'user_query': generated_question['question'],
'answer': regen_answer['answer'],
'ref1': docs[0].page_content,
'ref2': docs[1].page_content,
'ref3': docs[2].page_content
})
parsed = parser.parse(evaluation_result['text'])
# parsed.score, parsed.reason 와 같이 접근 가능
print(parsed)
[Output]: Answer(score=10, reason='제공된 정보는 완벽하게 제공되었습니다. 해당 정보는 모든 요구 사항을 충족합니다.')
Sequential Chain
위의 마지막 작업은 LangChain의 SequentialChain을 이용하여 구현할 수 있습니다.
from langchain.chains import SequentialChain
seq_chain = SequentialChain(
chains=[answer_chain, evaluation_chain],
input_variables=["user_query", "ref1", "ref2", "ref3"]
)
answer = seq_chain({
'user_query': generated_question['question'],
'ref1': docs[0].page_content,
'ref2': docs[1].page_content,
'ref3': docs[2].page_content
})
parser.parse(answer['text'])
이렇게 실습을 통해 LangChain의 각 모듈의 사용법을 간략하게 소개해 드렸습니다. 본 포스트에서는 자세히 다루지 않았지만, 실제로 LangChain을 활용하는 서비스에서 가장 중요한 요소는 Agent와 Tool입니다. 따라서 위에서 배운 내용을 바탕으로 개인의 Agent와 Tool을 개발해 보시길 권장드립니다.
LangChain을 활용하여 성공적인 LLM 기반 서비스를 구축하시는 데 조금이나마 도움이 되었기를 바라며, 여러분의 흥미로운 창작물을 기대하겠습니다!
'AI 솔루션 > LLMOps' 카테고리의 다른 글
| [LLMOps] LangChain의 모든 것 (2) 구성 요소 (0) | 2023.08.10 |
|---|---|
| [LLMOps] LangChain의 모든 것 (1) 개요와 컨셉 (0) | 2023.08.08 |