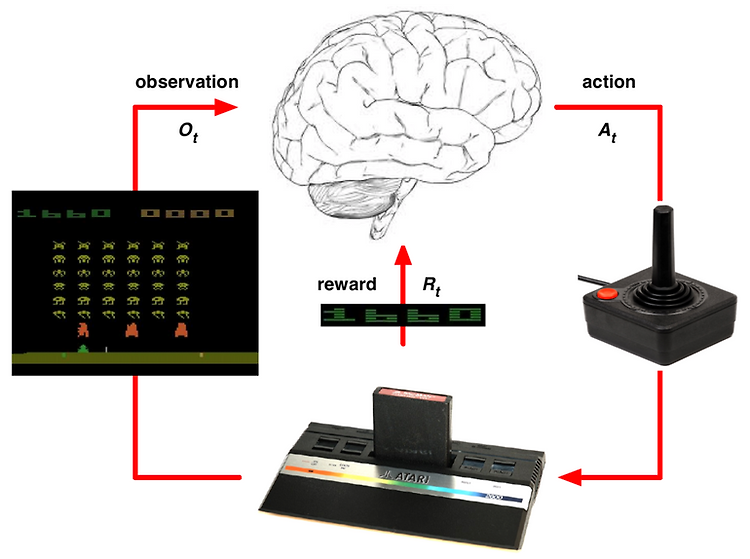
2022.04.26 - [[스터디] 강화학습] - [RL] 1-1. 강화학습이란? [RL] 1-1. 강화학습이란? 안녕하세요. 마인즈앤컴퍼니 (이하 MNC) 입니다. :-) MNC의 새로운 'RL' 시리즈를 소개드립니다. 테크리더 명대우 파트너님의 지도 아래, MNC 의 Data scientist 인 최창윤 매니저가 뜻을 모아 강화학습에 blog.mnc.ai 2022.04.28 - [[스터디] 강화학습] - [RL] 1-2. 강화학습의 구성 요소 [RL] 1-2. 강화학습의 구성 요소 이전 포스팅에서 Agent가 Action을 수행했을 때 Environment와의 상호작용을 통해 Agent가 학습한다고 배웠습니다. Agent와 Environment, Action 에 대해 구체적이지는 않지만 간단한 개념을..