이전 포스팅에서 Agent가 Action을 수행했을 때 Environment와의 상호작용을 통해 Agent가 학습한다고 배웠습니다. Agent와 Environment, Action 에 대해 구체적이지는 않지만 간단한 개념을 이해하고 계실텐데요. 본 포스팅에서는 강화학습을 이해하기 위해 필요한 추가적인 개념들을 간단히 살펴보고 Atari 게임에 그 개념을 도입해볼 것입니다.
이 포스팅은 각 개념들을 자세히 이해하기 위한 것이 아닙니다. 각 개념들은 이후의 포스팅에서 더 자세히 설명할 것입니다.
강화학습의 구성요소
Sutton의 책에서는 RL System을 구성하는 4가지 주요한 Subelements를 다음과 같이 소개합니다.
- Policy
- Reward Signal
- Value Function
- Model of the environment
여기에 추가로 본 포스팅에서는 State와 Observation, History 의 개념에 대해 설명합니다. 본 개념들은 서로 얽혀있어서 특정 개념을 설명하기 위해 다른 개념들이 필요하지만, 최대한 개념들이 얽히지 않는 내용만으로 정리하였습니다. 또한, 이해를 돕기위해 Atari의 Space Invaders 게임을 예시로 본 포스팅을 마무리합니다. 이전 포스팅에 서술한 강화학습의 프로세스에 대해 이해하셨다면 크게 어렵지는 않을 것입니다.
History $(H)$
강화학습은 Agent와 Environment가 Action과 Observation, Reward를 서로 교환하며 상호작용하는 과정이라 할 수 있습니다. 그리고 처음부터 현재시간 t 까지 수행한 내용들을 나열한 것을 History 라고 합니다.
$H_t = O_1, R_1, A_1, \cdots, A_{t-1}, O_t, R_t$
History는 무한히 반복되는 것은 아니며, 목표를 만족하거나 실패해서 더 이상 반복할 필요가 없는 Terminal State에 도착하면 끝나게 됩니다. 이렇게 Agent와 Environment 가 수행한 일련의 상호작용을 하나의 Episode라고 합니다. 예를 들어, 벽돌깨기 게임을 하면 Game의 시작부터 Game을 클리어하거나 Game Over가 될 때 까지를 하나의 Episode 라고 합니다.
Episode가 끝나는 조건은 Game Over나 Game Clear와 같이 Environment가 특정 State에 도달하는 직관적인 경우도 있으나, 어느정도 학습이 진행되서 장기간 History가 유지되는 경우 특정 조건에 따라 인위적으로 History를 중단하고 새로운 Episode를 시작합니다.
State $(S)$ and Observation $(O)$
State는 다음 Step의 Action, Reward, Observation을 결정하는 데 사용되는 모든 변수를 의미합니다. State는 두 가지로 나눌 수 있습니다. Environment 의 정보를 나타내며 Agent에게 어떤 Reward와 Observation을 줄 지 결정하는 데 영향을 주는 변수를 Environment의 State $(S^e_t)$ 라고 합니다. 이와 유사하게, Agent의 정보를 나타내며 다음 Step 에서 어떤 Action을 취할 지 결정하는 데 영향을 주는 변수를 Agent의 State $(S^a_t)$ 라고 합니다.
대부분의 경우 Agent 입장에서 Environment의 정보인 $S^e_t$ 를 모두 받을 수 있는 경우는 거의 없습니다. 스타크래프트 게임을 한다고 생각해보면 우리는 상대방의 시야에 대한 정보가 없고 자신의 유닛이 밝힌 시야만 관측할 수 있습니다.
강화학습에서는 Environment가 가진 State와 Agent가 Environment로부터 받는 정보를 분리하여, Agent가 Environment에게 받는 일부 (또는 전부)의 State 정보를 Observation $(O)$ 라고 합니다. 실제로 Agent가 받는 데이터는 Observation과 Reward 지만, 대부분의 논문과 블로그에서 Observation을 State와 혼용해서 사용합니다. 본 포스팅 또한 Observation 이라는 명칭 대신 State 라고 사용하겠습니다.
Policy $(\pi)$
Policy는 Observation 이 주어진 상황에서 Agent가 수행해야 할 Action을 결정해줍니다. 즉, Policy는 Environment의 State를 Action으로 변환해주는 함수라고 생각할 수 있습니다. Policy는 문제에 따라 정의하기 나름인데 Grid world에서 무작위로 움직이는 Random Policy가 될 수도 있으며, State와 Action으로 구성된 Lookup Table 일수도, 아니면 딥러닝에 의해 학습되는 매우 복잡한 비선형 함수일 수도 있습니다. Policy는 Action을 결정하는 방법이 결정적인지 확률적인지에 따라 Deterministic policy 와 Stochastic policy로 나뉘게 됩니다.
Deterministic Policy: $a = \pi(s)$
Stochastic Policy: $\pi(a \vert s) = \mathbb{P}[A_t = a \vert S_t = s]$
수식과 같이 Deterministic Policy는 State가 주어지면 그것에 맞는 Action을 반환해줍니다. 따라서, State가 같으면 Policy에 의해 나오는 Action은 항상 같습니다.
반면, Stochastic Policy는 State가 주어졌을 때 선택되는 Action이 확률적입니다. Action이 n개 있다고 하면 같은 State에서 모든 Action이 확률적으로 선택될 수 있는 것이죠.
Reward $(R_t)$
Reward$(R_t)$ 는 Agent의 Action에 대한 Feedback을 나타내는 값으로, 간단히 말하자면 시간 $t$ 순간에 Agent가 한 행동에 대해 얼마나 잘했는지 알려주는 값입니다. Agent의 목적은 전체 Step동안 받는 Total reward 를 최대화 하는 것이기 때문에, Reward 값을 어떻게 정의할 지가 Agent를 학습시키는 것에서 매우 중요합니다. 이것은 곧 Agent가 Action을 어떻게 선택할 것인가를 결정짓기 때문에 Policy를 변경하는 요소가 됩니다.
Reward: $\mathcal{R}^a_s = \mathbb{E}[R_{t+1} \vert S_t = s, A_t = a]$
Reward는 State와 Action에 따라 확률적으로 결정되며, 기본적으로 스칼라 값으로 정의됩니다.
Value Function $(v_{\pi})$
강화학습의 목적은 Action이 끝날 때까지 누적되는 Total Future Reward를 최대화하는 것입니다. 순간적인 Reward가 높더라도 장기적으로 볼 때 좋지 않은 행동이면 그 행동은 선택하지 않겠다는 의미입니다. 하지만 Reward는 순간적인 Action에 대한 보상 값이기 때문에 장기적으로 좋은 행동인지 아닌지를 판단할 수 없습니다. 그렇다면 Total Reward를 어떻게 정의할 수 있을까요 ?
강화학습에서는 Agent가 State $s$ 에 위치했을 때, 그 State로부터 이후에 받을 Reward들을 모두 누적시킨 것의 기대값을 Value 라고 정의합니다. 이 Value가 Reward를 누적시킨 Total Reward가 되는 것이죠. Value 는 이후 행동으로 발생하는 Reward들을 모두 고려하기 때문에 특정 순간에서의 Reward보다 더 원시안적(farsight) 입니다.
결론적으로 강화학습의 목적은 가장 높은 Reward를 얻기 위한 것이 아니라, 가장 높은 Value를 얻기 위한 Action을 선택하는 것입니다. Sutton의 책에서는 Value Function을 정의하는 것이 Reward를 정의하는 것보다 어려운 일이라고 합니다. Reward는 Environment로부터 직접적으로 결정되지만 Value는 전체 Episode동안 발생하는 Reward의 값으로부터 다시 추정해야 하기 때문입니다. 그리고 강화학습에서 가장 중요한 것이 효율적으로 Value 값을 추정하는 것입니다.
$v_{\pi}(s) = \mathbb{E}_\pi [R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... \vert S_t = s]$
위 식은 많이 사용되는 Value Function의 정의입니다. 이 Value Function 은 State-Value Function과 Action-Value Function 으로 나뉘는데, 이것은 추후에 살펴보도록 하겠습니다.
Model
Agent는 Action을 취했을 때 Environment가 어떻게 될 지 예측하는 기능을 가질 수 있는데 이것을 Model 이라고 합니다. 즉, 현재의 State와 Action이 주어졌을 때 다음 State와 Reward를 추론해주며, 특정 행동을 취해서 겪어보기 전에 미래를 알 수 있는 것이죠. 따라서, Model은 Reward와 State의 Transition을 예측하는 기능을 가지고 있어야 합니다.
Reward 예측
- State에서 Action을 했을 때 받는 Reward를 예측
- $\mathcal{R}^a_s = \mathbb{E}[R_{t+1} \vert S_t = s, A_t = a]$
State Transition 예측
- State에서 Action을 했을 때 다음 State를 예측
- State Transition은 특정 State에서 Action을 했을 때 다음 State가 어떤 것이 될 지 확률로 나타낸 것입니다.
- $\mathcal{P}^a_{ss'} = \mathbb{P}[S_{t+1} = s' \vert S_t = s, A_t = a]$
다음 포스팅에서 다루겠지만 Reinforcement Learning은 Model의 존재 여부에 따라 Learning 과 Planning으로 나뉘는데, Model은 Planning을 위한 것이라고 할 수 있습니다.
Example
본 포스팅에서는 추상적인 개념이 너무 많이 나와서 포스팅 초반부터 어렵다는 생각이 들 수 있을 것 같습니다. 여기서는 Atari의 Space Invaders에 강화학습을 적용한다면 위에서 배운 개념들을 어떻게 실제 문제에 적용해야할 지를 간단히 살펴보겠습니다.
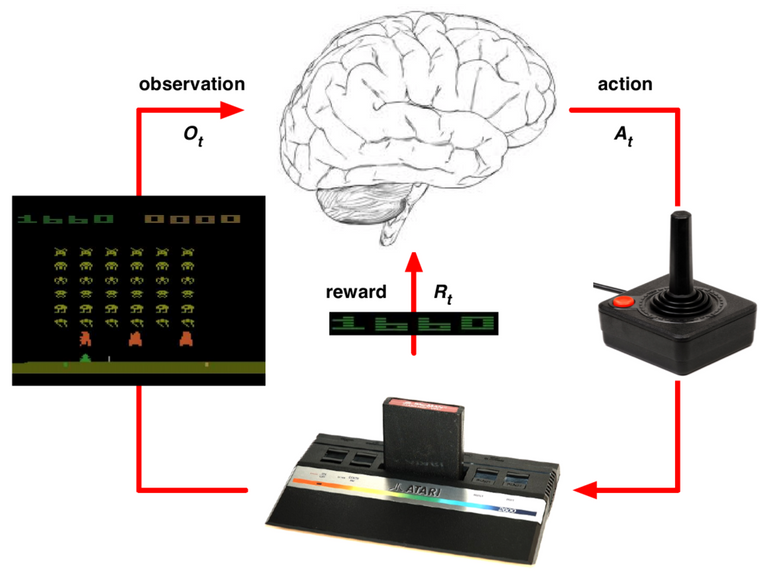
- Agent: 유저
- Environment: Atari 게임기
- Observation: 화면
- Environment State: 게임 내부에서 화면을 띄우기 위해 계산하는 미사일의 속도, 적의 위치 등
- Action: 게임 Controller
- Reward: 점수
- Episode: 게임의 시작부터 캐릭터가 죽거나, 라운드를 깰 때까지
Atari 게임에서 게임기(Environment)는 기존 미사일의 위치, 몬스터의 위치, 유저의 속도 등을 참고하여 다음 화면(O)을 모니터로 출력하고 게임 점수(R) 를 계산합니다. 유저(Agent) 는 게임기로부터 화면 정보를 받아서 다음 위치로 이동(Action)합니다. 이 과정을 반복하여 강화학습 모델은 미사일을 피하면서 적을 죽이는 방법을 학습합니다.
참고자료
- Sutton http://incompleteideas.net/book/RLbook2020.pdf
- David Silver https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ
마인즈앤컴퍼니는 적극 인재 채용 중입니다. 많은 관심과 지원 바랍니다.
마인즈앤컴퍼니
Make the Most of AI
mnc.ai
'AI Study > 강화학습' 카테고리의 다른 글
| [RL] 2-2. Exploration과 Exploitation: Greedy Method vs. Epsilon-greedy Method (0) | 2022.09.14 |
|---|---|
| [RL] 2-1. Exploration과 Exploitation: Multi-armed Bandit Problem (0) | 2022.07.15 |
| [RL] 1-1. 강화학습이란? (0) | 2022.04.26 |