안녕하세요! 마인즈앤컴퍼니 민팃 팀입니다.
마인즈앤컴퍼니는 지난 2019년부터 중고 휴대폰 거래 플랫폼 민팃의 ATM을 위한 딥러닝 파손 탐지 AI 모델을 개발하고 있습니다. 본 포스트는 민팃 시리즈의 두 번째 포스트입니다.
오늘 포스트에서는 민팃 팀에서 데이터를 다루는 방법을 소개합니다.
요즘 Data-centric AI라는 아주 핫한 용어가 많은 관심을 받고 있는데요. 오늘은 Data-centric AI가 무엇인지, 또 민팃 팀에서는 Data-centric AI 구현을 위해 어떻게 데이터를 다루고 있는지를 알아보겠습니다.
만약 민팃 서비스와 민팃의 AI 모델에 대해 더 궁금하시다면 첫 번째 포스트를 읽어주세요.
2022.06.02 - [AI 프로젝트 소개] - [민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기
[민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기
안녕하세요! 마인즈앤컴퍼니는 지난 2019년부터 올해로 4년째 민팃 중고폰 ATM에서 사용되는 AI 모델 개발을 담당하고 있습니다. 이번 주부터 4주 간 발행되는 민팃 포스트 시리즈를 통하여 민팃
blog.mnc.ai
Data-centric AI vs. Model-centric AI
“A Chat with Andrew on MLOps: From Model-centric to Data-centric AI”
지난 2021년 3월, Andrew Ng 교수님은 DeepLearningAI가 주최한 학회에서 “A Chat with Andrew on MLOps: From Model-centric to Data-centric AI” 라는 제목으로 세미나를 진행했습니다.
Andrew Ng 교수님은 세미나에서 AI 모델을 개발하는 두 가지의 접근법을 소개합니다.
https://www.youtube.com/watch?v=06-AZXmwHjo
- Model-centric AI 는 모델을 설계하고 실험할 때 알고리즘과 코드에 집중하는 AI 모델링입니다.
- Data-centric AI 는 코드보다는 데이터의 양과 질, 일관성 등에 더 초점을 맞추는 AI 모델링입니다.

Data-centric AI와 Model-centric AI는 구체적으로 어떤 점에서 다를까요?
AI 모델링에 대한 서로 다른 두 가지의 접근법은 모델의 성능을 개선시키기 위해서 개발자가 스스로에게 어떤 질문을 던지느냐에서 차이를 보입니다.
Model-centric AI 개발자는 AI 모델의 코드 개선을 위해서 다음과 같은 질문을 합니다:
- 모델 아키텍처: 새로운 모델을 써볼까? 레이어를 더 깊거나 얕게 쌓아볼까?
- 하이퍼파라미터: Batch size나 Learning rate를 줄이거나 늘려볼까? Early stop을 좀더 길거나 짧게 걸어볼까?
- 학습 방식: Loss 함수나 Optimizer, Scheduler를 바꿔볼까? 여러 개의 모델을 학습시켜서 앙상블해볼까?
- 등등…
이때 Model-centric AI 개발자가 다루는 데이터셋은 수집 이후에 거의 변화하지 않습니다.
데이터를 최대한 많이 수집해서 전처리한 후에 별도의 수정을 거치지 않고 계속 동일한 데이터셋에 대해 코드를 변경해가면서 실험합니다.
반면에 Data-centric AI 개발자는 이것과는 조금 다른 질문을 던집니다:
- 데이터 라벨의 모호함(ambiguity)을 줄여서 노이즈를 제거하려면 어떻게 해야할까?
- 데이터 Augmentation(합성)을 통해 좀 더 다양한 도메인에서 일반화할 수 있을까?
- 데이터가 올바르게 라벨링되어 있는가?
Data-centric AI 개발자는 코드보다는 데이터셋을 개선하는 데 집중합니다.
또 데이터셋의 수량을 늘리기보다는 정확한 데이터를 확보하려고 노력하고, 이미 가지고 있는 정확한 데이터를 합성하여 모델이 아직 본 적 없는 도메인에 대해서도 학습할 수 있도록 합니다.
둘 중 어떤 것이 확실히 더 좋다고 말하기는 어렵겠지만, Andrew Ng 교수님은 세미나에서 다양한 예시들을 통해 모델의 코드를 최적화하는 것보다 데이터를 최적화하는 것이 성능 개선에 훨씬 효과적인 경우가 많음을 보여줍니다.

“Data is Food for AI” 라는 말은 너무나 당연하게 들리지만, 실제로 AI 모델링에서 데이터의 중요성은 크게 간과되곤 합니다.
의외로 대부분의 AI 모델링 프로젝트의 업무는 데이터 수집, 정제 및 가공 과정이 80% 이상 차지하는 경우가 많습니다. 모델 코딩과 학습 실험 과정은 전체 프로젝트의 20% 정도밖에 안 된다는 의미입니다.
그러나 생각보다 데이터에 관련된 연구는 활발하게 이루어지지 않고 있습니다. Andrew Ng 교수님이 확인한 임의의 최신 AI 논문 100편 가운데 무려 99편이 모델 학습 방법론에 대한 내용이었고, 데이터 증강에 관련한 논문은 단 한 편 뿐이었다고 합니다.
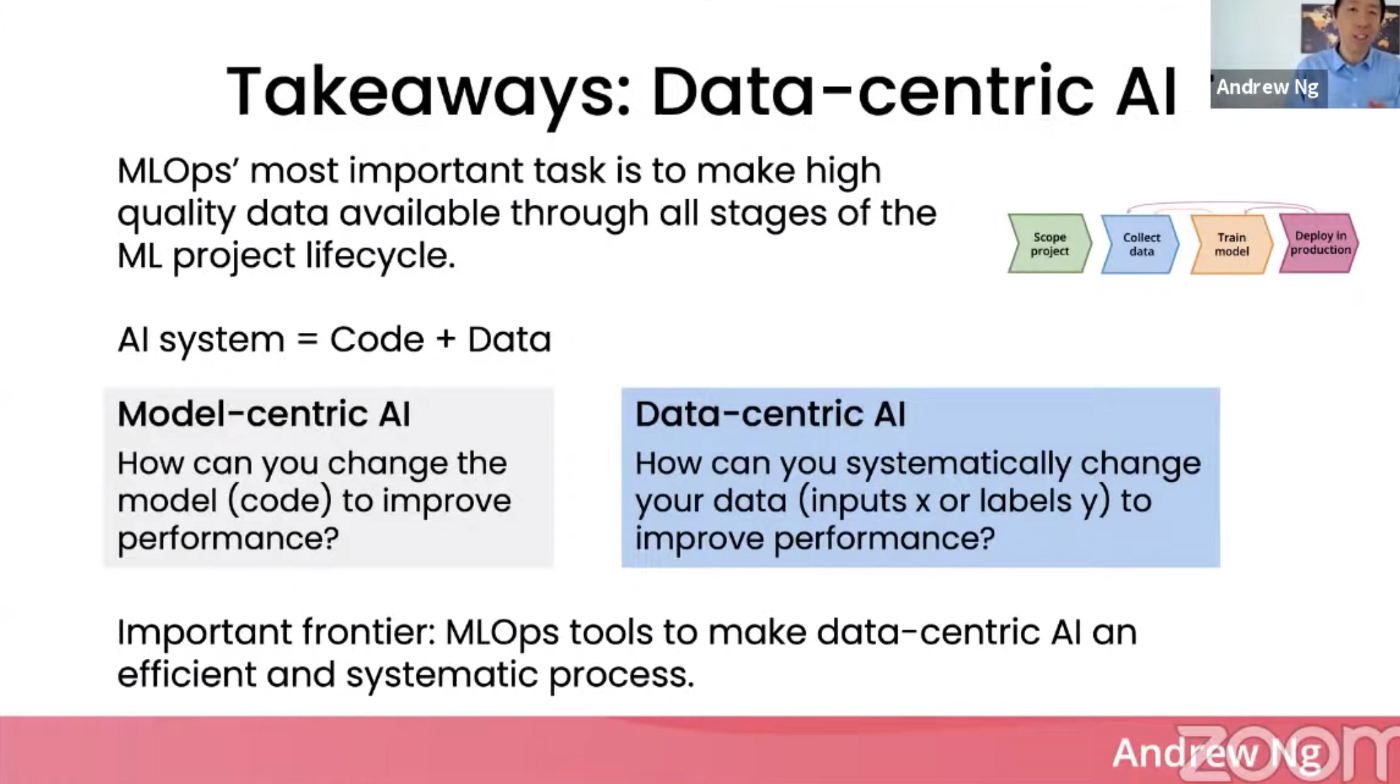
결론적으로 AI 모델의 퍼포먼스를 높이기 위해서는 AI 시스템의 구성 요소인 코드와 데이터 둘 다 개선되어야 하며, 데이터 측면에서의 개선방향이 상대적으로 더 효율적이고 뚜렷한 효과를 가져올 수 있습니다.
현업에서 딥러닝 모델을 서비스하고 있는 Data Science 팀에게 시사하는 점이 많은 유익한 세미나인데요.
그렇다면 효과적인 Data-centric AI를 구현하기 위해 민팃 팀에서는 어떤 노력을 기울이고 있을까요?
민팃 ver. Data-centric AI Model
민팃은 전국의 약 6천대 ATM을 대상으로 Real-world AI 모델을 서비스하고 있습니다.
다양한 도메인에서 서로 다른 특징을 가진 수많은 데이터가 들어오는 만큼 가능한 한 데이터를 일반화하고 노이즈를 줄여 클린한 데이터셋을 만드는 것을 지향합니다.
모델을 좋은 데이터로 학습시키기 위해서 민팃 팀에서는 대표적으로 두 가지 방법을 사용하고 있습니다:
- 모델 학습과 추론에 적합하지 않은 데이터 필터링하기
- 모델이 많이 헷갈려하는 애매한 데이터를 모아 재학습하기
부적합 데이터 필터링하기 (feat. 예외처리 모델)
민팃 시리즈 첫 번째 포스트에서 민팃의 딥러닝 파손 탐지 파이프라인을 소개했습니다.
여러 개의 서로다른 모델을 파이프라인 형태로 연결하여 다양한 문제 상황에 효과적으로 동작하는 안정적인 휴대폰 외관 탐지 자동화 서비스를 구현하였는데요.
파이프라인의 가장 처음 부분에 예외처리 Image Classification 모델이 있습니다.

예외처리란, 이미지의 특징이 파손 탐지에 적합하지 않아 모델의 학습 데이터로 활용하기 어려운 사진을 사전에 필터링하는 과정을 말합니다.
예외처리 Image Classification 모델은 ATM에서 촬영된 중고 휴대폰 사진에 대하여 발생할 수 있는 예외사항들을 사전에 처리하기 위해 별도로 개발된 모델입니다.
예외처리 모델은 다음과 같은 지점에서 민팃 딥러닝 파손탐지 파이프라인의 성능 개선에 기여하고 있는데요:
- 데이터가 예외처리 모델을 먼저 통과하게 되면, Segmentation 모델에 입력되는 데이터의 클래스별, 특징별 일관성이 증가합니다.
- 즉 데이터에 내재된 모호함(ambiguity)이 줄어들기 때문에 Segmentation 모델이 데이터의 특징을 더 쉽게 파악할 수 있습니다.
- 따라서 모델의 Feature Extraction과 Segmentation 성능이 개선됩니다.
데이터가 파손 탐지 Segmentation 모델에 도달하기 전에 예외처리 Classification 모델을 한 번 거치는 구조로 파이프라인이 설계되어 있기 때문에, 파손탐지 모델에 더욱 일관되고 깔끔한 데이터가 흘러갈 수 있게 됩니다. 따라서 Data-centric AI 측면에서의 성능 개선을 달성할 수 있습니다.
자주 틀리는 데이터를 파악하여 재학습에 반영하기
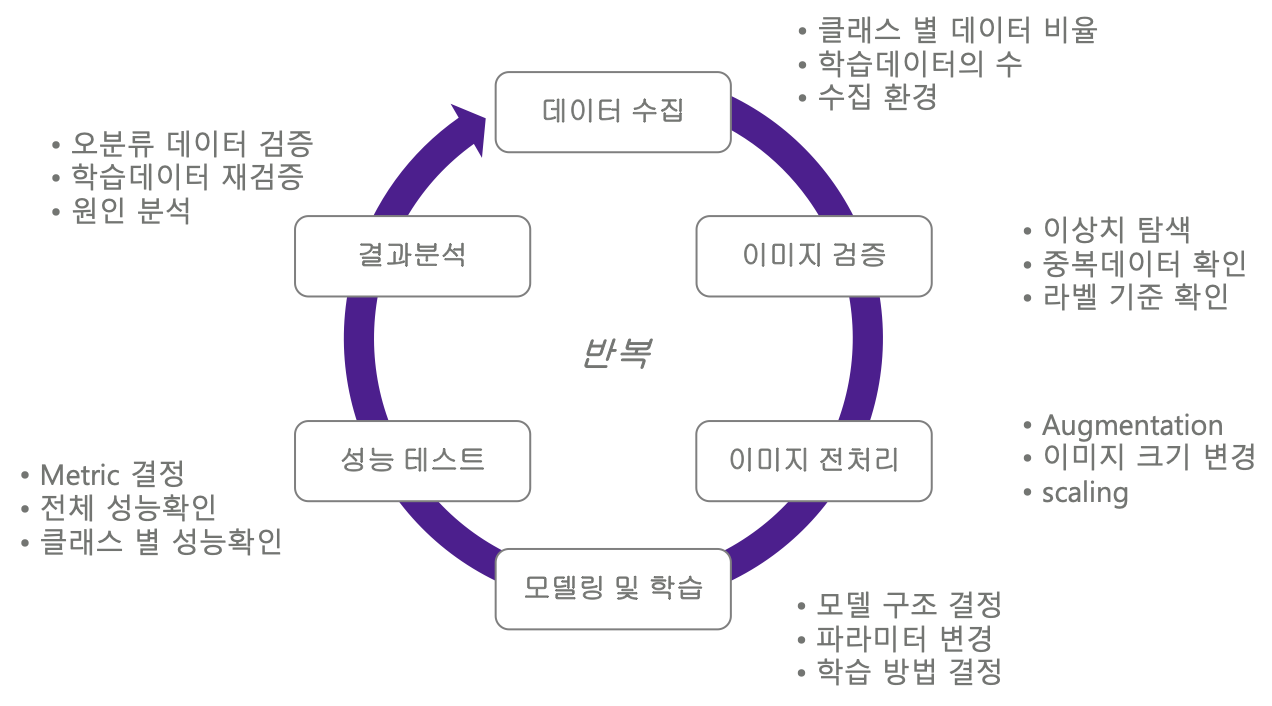
AI 모델링 프로젝트에서는 데이터 수집 → 검증 → 전처리 → 코딩 → 평가 → 분석의 사이클을 반복적으로 돌며 계속해서 모델을 업그레이드합니다.
모델 재학습이란 사이클을 한 번 돌 때마다 새로운 데이터를 수집해서 모델에게 다시 학습시키는 과정을 의미하는데요.
이때 어떤 데이터를 추가로 수집하여 재학습 하느냐에 따라 모델 성능이 개선되는 정도가 크게 달라집니다.
다음은 Mini ATM 딥러닝 파손 탐지를 위해 개발된 서로다른 모델 4종의 성능 변화 그래프입니다.
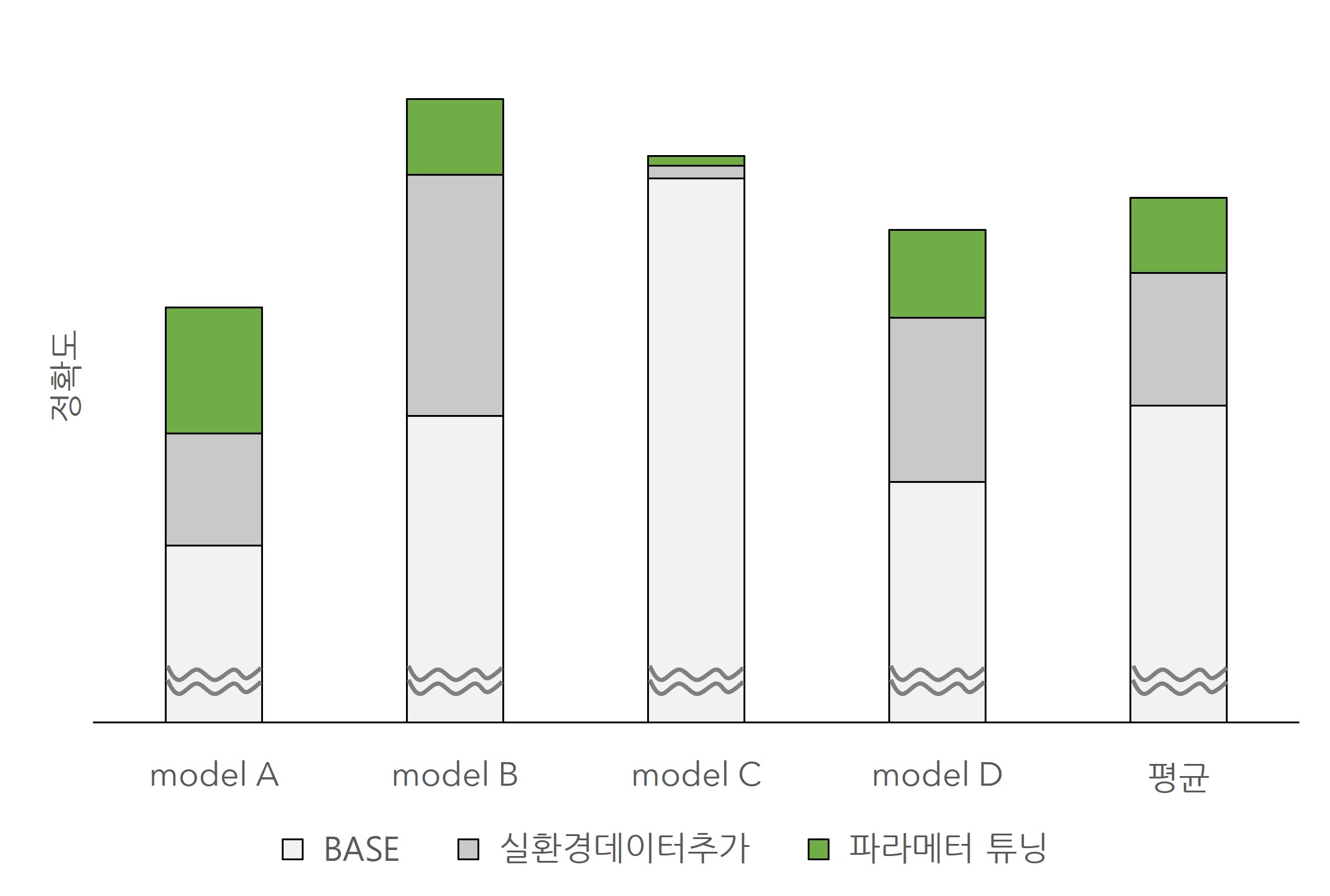
- 연한 회색 : 베이스라인 모델 성능 (default)
- 짙은 회색 : 데이터를 추가적으로 수집해서 재학습한 후 모델 성능 (Data-centric approach)
- 녹색 : 모델 파라미터 튜닝 성능 (Model-centric approach)
민팃 AI 모델의 실험 결과를 보면, 실환경 데이터를 추가적으로 수집해서 모델을 재학습하는 것이 모델의 하이퍼파라미터를 튜닝하는 것보다 성능 개선에 미치는 영향이 더 크다는 것을 확인할 수 있습니다.
평균적으로 실환경 데이터 추가는 약 10%p, 하이퍼파라미터 튜닝은 약 5%p의 정확도 개선을 이루었으며 이는 Andrew Ng 교수님이 세미나에서 언급한 내용과 크게 다르지 않은 결과입니다.
민팃 팀에서 효과적으로 모델을 재학습하기 위하여 수집하는 데이터의 종류는 다음과 같습니다:
AI 오분류 데이터
- 한 이미지를 보고 민팃의 검수팀에서 사람이 판정한 등급과 민팃 AI가 판정한 등급이 서로 다른 경우가 있습니다.
- 이런 경우가 발생하는 이유는 다양한데 주로 이미지의 파손이 애매해서, 휴대폰이 특수한 기종이어서, 사진 촬영의 퀄리티가 낮아서 등입니다.
- 이러한 이미지들의 특징을 모델이 학습할 수 있도록 하기 위하여 민팃 팀에서는 AI 모델이 잘못 판단한 데이터를 수집하여 추가학습에 반영합니다.
신규 기종 데이터
- 삼성이나 애플 등 스마트폰 제조사에서는 매년 다양한 질감과 형태를 갖는 새로운 휴대폰을 출시합니다.
- 이때 새로 출시된 휴대폰이 이전의 휴대폰과 전혀 다른 특징을 갖는다면 (ex. 폴더블 스마트폰 등), 기존의 모델로는 새로운 휴대폰에 대한 추론을 올바르게 해낼 수 없습니다.
- 따라서 모델이 새로 출시된 휴대폰의 특징도 학습할 수 있도록 하기 위하여 민팃 팀에서는 해마다 출시되는 신규 기종 데이터를 수집하여 추가학습에 반영합니다.
https://www.etnews.com/20220613000198
중고폰 거래 양성화… 세금 깎아준다
과학기술정보통신부가 중고 휴대폰에 대한 세제 혜택을 포함해 매입-유통-이용 전 단계에 대한 제도개선 종합방안을 준비하고 있는 것으로 확인됐다. 유관 부처, 국회와의 협의를 거쳐 중고폰
www.etnews.com
최근 과기정통부에서 중고 휴대폰 제도 개선을 추진하고 있다고 발표했는데요. (출처: 전자신문) 기존에 중고폰은 부가가치세 10%가 부과되었는데, 판매가에서 매입가를 뺀 금액에 대해서만 세금을 부과하는 세액 공제 혜택을 받을 수 있게 됩니다. 또한 '중고폰 사업자 인증제', '중고폰 거래사실 확인 시스템' 등의 도입으로 신뢰도를 높여, 중고폰 시장의 적극적인 성장이 기대됩니다. 그렇게 된다면 민팃 서비스 이용자도 더 확대될 것이고, 마인즈앤컴퍼니도 더 양질의 데이터를 수집하여 정교한 AI 모델을 구축할 수 있기를 기대해봅니다!
오늘은 Data-centric AI란 무엇인지, 또 민팃 팀에서 효과적인 Data-centric AI 모델 구현을 위해 어떤 시도들을 하고 있는지 알아보았습니다. 이어지는 포스팅에서는 민팃 ATM의 AI 모델을 서비스하는 운영코드에 대해 소개하고, 좋은 운영코드를 설계하는 방법에는 어떤 것이 있는지 공유하겠습니다.
감사합니다.
'AI to the Real World > 민팃' 카테고리의 다른 글
| [민팃] 쉽게 알아보는 민팃 딥러닝 모델 성능평가 - Dice score부터 Kappa까지 (0) | 2022.08.05 |
|---|---|
| [민팃] 야 너두 할 수 있어! 유지보수가 쉬운 AI 모델 서비스 운영 코드 설계하기 (0) | 2022.06.30 |
| [민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기 (1) | 2022.06.02 |