안녕하세요. 본 포스트에서는 AI 모델을 서비스에 반영할 때 겪을 수 있는 어려움과, 이를 해결하기 위한 효율적인 설계 방안을 소개합니다.
*** 마인즈앤컴퍼니는 지난 2019년부터 중고 휴대폰 거래 플랫폼 민팃의 ATM을 위한 딥러닝 파손 탐지 AI 모델을 개발하고 있습니다. 본 포스트는 민팃 시리즈의 세 번째 포스트입니다.
이전 발행글이 궁금하다면 클릭해주세요.
2022.06.02 - [AI 프로젝트 소개] - [민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기
[민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기
안녕하세요! 마인즈앤컴퍼니는 지난 2019년부터 올해로 4년째 민팃 중고폰 ATM에서 사용되는 AI 모델 개발을 담당하고 있습니다. 이번 주부터 4주 간 발행되는 민팃 포스트 시리즈를 통하여 민팃
blog.mnc.ai
2022.06.15 - [AI 프로젝트 소개] - [민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI
[민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI
안녕하세요! 마인즈앤컴퍼니 민팃 팀입니다. 마인즈앤컴퍼니는 지난 2019년부터 중고 휴대폰 거래 플랫폼 민팃의 ATM을 위한 딥러닝 파손 탐지 AI 모델을 개발하고 있습니다. 본 포스트는 민팃 시
blog.mnc.ai
일반적으로 AI 모델 학습 과정은 ‘개발’이 아닌 ‘실험’이라고 표현합니다. 개발은 구체화한 목표를 구현하는 행위를 말하지만, 실험은 그것을 찾기 위한 시도 자체를 의미합니다. 목표 성능을 위해 가설을 세우고 다양한 방법을 시도해야 하므로 AI 모델 학습 코드는 가변적일 수밖에 없습니다.
그러나 서비스 운영 코드는 ‘개발’의 대상입니다. 코드를 작성하기 전까지 최대한 요건을 구체화해야 안정적인 모듈을 만들 수 있습니다. 간단한 요건이라도 그것의 기능을 온전히 구현하기 위해 다소 복잡해질 수도 있기 때문입니다. 개발 프로젝트 후반부에 요건이 바뀌는 것만큼 개발자에게 큰 스트레스도 없을 것입니다.
데이터 ‘사이언티스트’와 ‘개발자’ 사이의 갈등은 이러한 ‘실험’과 ‘개발’의 온도 차에서 발생합니다. 당장 내일 바뀔지도 모르는 데이터 전처리 Pipeline을 수정하고, 주기적으로 AI 모델을 갱신하다 보면, 수많은 사람들이 이용하는 서비스 운영 모듈이 스파게티 코드가 돼버릴 수 있습니다.
개발자가 데이터 사이언티스트와 다투지 않으려면 AI 모델 실험 과정을 이해하고, 코드 구조를 유연하게 유지해야 합니다. 동시에 안정적인 서비스를 위해 명확한 설계도 필요합니다. 그럼, 민팃 중고폰 ATM AI 모델 서비스 운영 코드는 어떻게 문제를 해결했는지 알아보겠습니다.
AI 모델 서비스 운영 코드가 유지/보수 하기 어려운 이유
AI 모델 서비스 운영 코드의 형태는 일방향이고, 절차적입니다. AI 모델 학습 과정과 마찬가지로 전처리, 추론, 후처리 과정을 거치고, 비즈니스 요건에 따라 결과를 가공해서 사용자에게 제공합니다. 얼핏 간단해 보이지만 운영 코드가 쉽게 꼬여버리는 이유는 크게 3가지가 있습니다
1. 실험적인 AI 모델 학습 과정
도입부에서 설명했듯, AI 모델 학습 과정은 개발이 아닌 실험입니다. 때로는 현장에 한 번도 적용한 적 없고, 게재한 지 얼마 안 된 논문의 코드를 사용할 수도 있습니다. 일반적인 서비스처럼 검증된 라이브러리만 쓰는 것이 아니기 때문에, 갑자기 애써 만든 코드를 다 들어내야 할 수도 있습니다. 또한, AI 모델은 한 번 만들었다고 끝이 아닙니다. 데이터를 추가해서 AI 모델을 계속 갱신해야 하므로 수정 요청 주기도 짧습니다.
2. 학습 데이터와 실 환경 데이터의 차이
AI 모델 성능 향상 방법을 논할 때 빼놓을 수 없는 말 중의 하나는 GIGO(Garbage in, garbage out) 입니다. 데이터의 품질이 모델 성능을 크게 좌우한다는 의미입니다. 데이터 사이언티스트는 깨끗한 데이터를 만들기 위해 많은 시간을 투자합니다. 하지만 실시간 서비스에서 발생하는 데이터는 훨씬 더 다양합니다. 즉, 학습할 때 고려하지 않았던 데이터가 들어올 수 있기 때문에 많은 데이터 필터링 코드를 추가해야 합니다.
3. 모델 결과에 대한 비즈니스 요건 적용
대부분 서비스는 AI 모델 결과를 그대로 활용하지 않습니다. AI 모델 추론 산출값은 로짓(Logit)이지만, 이를 비즈니스 요건에 맞게 변환해야 합니다. 예컨대 민팃 스마트폰 외관 파손 탐지 모델은 로짓으로 구성된 마스크 이미지를 출력하지만, ATM에서는 파손 부위의 위치와 등급을 표시합니다. 이를 반영하려면 AI 모델, 비즈니스 요건에 대한 이해가 모두 필요하기에 다소 까다로운 작업일 수 있습니다.
유지 보수하기 쉬운 AI 모델 서비스 운영 코드의 요건
위 3가지 이슈에 대응하기 위한 AI 모델 서비스 운영 코드 설계 요건은 아래와 같습니다.
1. 실험적인 AI 모델 학습 과정
- 실험 과정과 최대한 같은 처리 방식으로 구현
- 데이터 처리 코드 추가/수정 용이
- 학습/운영 과정 간 모델 재현성 검증 용이
2. 학습 데이터와 실 환경 데이터의 차이
- 학습하지 않은 데이터에 대한 예외 처리 코드 필요
3. 모델 결과에 대한 비즈니스 요건 적용
- 비즈니스 요건에 해당하는 AI 모델 결과 가공 코드 필요
이제 위 요건을 민팃 AI 모델 서비스 운영 코드에 어떻게 반영했는지 살펴보겠습니다.
민팃 AI 모델 서비스 운영 코드 설계 방식
1. AI 모델 데이터 처리 과정에 맞게 모듈 분리
AI 모델 학습 과정은 데이터 분석→전처리→추론→후처리→평가 순으로 진행합니다. 운영 과정에서는 데이터 분석, 평가 과정이 빠지고 서비스 후처리(비즈니스 요건 적용), 예외 데이터 처리 과정이 추가됩니다. 이 과정을 반영한 모듈과 그에 따른 기능은 아래와 같습니다.
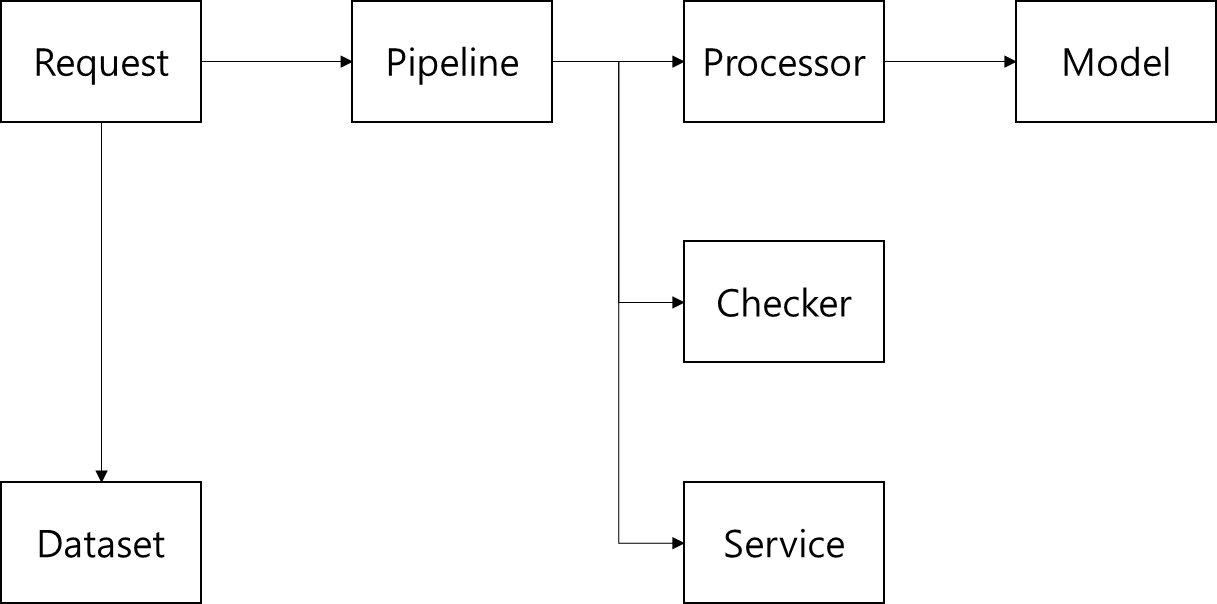
- Request: 요청 객체
- Pipeline: 각 모듈의 함수를 정의된 순서대로 수행하는 객체
- Processor: 모델 전처리/후처리 함수 모음
- Models: AI 모델 불러오기/추론 함수 모음
- Checker: 예외 데이터 처리 함수 모음
- Service: 비즈니스 요건 처리 함수 모음
- Dataset: 이미지, 마스크 등 함수 수행 산출물 형태를 정의하는 객체
위와 같이 모듈을 구성하면 기능 단위로 수정 요청이 발생할 때 다른 모듈에 영향을 줄일 수 있습니다. 예컨대 AI 모델을 갱신하려면 Models 모듈만 수정 하면 되고, 비즈니스 요건이 변경돼 AI 모델 추론 결과 이미지를 변경하려면 Service 모듈에만 코드를 추가하면 되는 것입니다. 그리고 AI 모델 학습 세부 단계에서 수정이 필요할 때(ex. 전처리만 변경)도 쉽게 수정할 수 있습니다.
2. 데이터 처리 과정이 명시적으로 드러나는 구조
적절한 기능 단위로 모듈을 분리했으니, 이제 데이터 처리 순서에 맞게 Pipeline을 조립해야 합니다. Request 객체는 이미지를 받아, Pipeline 객체를 호출하고, Pipeline 객체는 절차적으로 필요한 모듈의 함수를 실행합니다. Main 스크립트는 Pipeline의 조합으로 이루어지고, Pipeline의 단위를 잘 설정하면 Main 스크립트에서 아래와 같이 한눈에 코드의 흐름을 알 수 있습니다.

다만, Main 스크립트만 봐서는 개별 Pipeline이 세부적으로 어떤 함수를 수행하는지는 알 수 없습니다. Pipeline의 내 함수 수행 순서는 Config 파일로 관리합니다. 물론 Main 스크립트 내에서 순서대로 함수를 실행하는 방법으로 구현할 수 있지만, 코드가 길어지면 가독성이 떨어질 수 있기 때문에 함수 이름만 순서대로 작성하는 방식을 선택했습니다. 아래 그림은 Main 함수 A~E 과정을 구현한 Pipeline에서 수행하는 함수의 순서를 나타냅니다.

한 번에 모든 정보를 다 이야기하면 알아듣기 어렵습니다. 전체적인 구성을 먼저 이해시키고, 세부적인 내용은 그 이후에 말하는 것이 청자에 대한 배려입니다. 코드도 마찬가지 입니다. 하나의 스크립트에 모든 코드를 나열하면 이해하기 어렵습니다. 큰 기능 단위의 흐름은 Main 스크립트에, 세부 함수 동작 순서는 Config에, 각 함수의 동작 방식은 해당 모듈 스크립트에서 표현해야 이해하기 쉽습니다.
3. 함수 단위로 기능 추가
위와 같은 구조의 장점 중 하나는 수정이 자주 발생하는 부분과 그렇지 않은 부분을 나눌 수 있다는 점입니다. Main 스크립트의 Pipeline구성은 변할 가능성이 적습니다. Checker, Service 등 요건에 따라 추가/수정해야 하는 모듈은 함수의 모음으로 구성했습니다. 그 자체로 동작하는 것이 아닌, 함수 정의만 돼 있는 형태입니다. 기능을 추가하고 싶으면 해당 모듈에 함수를 작성하고. Pipeline config 파일에서 적절한 위치에 등록해주면 됩니다. 예컨대 A 과정 Pipeline에서 Gray scale 처리를 하고 싶다면, Processor 스크립트에 함수를 작성하고, Pipeline config 파일 func_c 밑에 Gray scale을 추가하면 됩니다.
4. Pipeline 수행 결과를 모두 Request에 저장
모든 Pipeline 수행 결과는 Request 객체에 저장합니다. 학습 코드에서 산출한 결과와 운영 코드에서 산출한 결과가 다를 수 있습니다. 어떤 Framework에서는 Batch size에 따라서도 결과가 달라지는 경우도 있습니다. 이에 수행 결과를 잘 관리하지 못하면, Debugging할 때 많은 시간을 낭비할 수 있습니다. 모든 수행 결과를 하나의 객체가 관리함으로써, 이러한 문제를 쉽게 찾을 수 있도록 구성했습니다.
AI 모델 서비스 운영 코드를 설계하려면 실험과 개발 모두를 이해해야 합니다. 숱한 실험 끝에 발견한 AI 모델을 안정적인 서비스로 구현하고자 고민하는 분들께 이 글이 작은 도움이 됐으면 합니다. 감사합니다!
마인즈앤컴퍼니는 적극 인재 채용 중입니다. 많은 관심과 지원 바랍니다.
마인즈앤컴퍼니
Make the Most of AI
mnc.ai
'AI to the Real World > 민팃' 카테고리의 다른 글
| [민팃] 쉽게 알아보는 민팃 딥러닝 모델 성능평가 - Dice score부터 Kappa까지 (0) | 2022.08.05 |
|---|---|
| [민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI (0) | 2022.06.15 |
| [민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기 (1) | 2022.06.02 |