안녕하세요! 마인즈앤컴퍼니 민팃 팀입니다.
*** 마인즈앤컴퍼니는 지난 2019년부터 중고 휴대폰 거래 플랫폼 민팃의 ATM을 위한 딥러닝 파손 탐지 AI 모델을 개발하고 있습니다. 본 포스트는 민팃 시리즈의 네 번째 포스트입니다.
오늘의 포스트에서는 민팃 팀의 AI 모델을 평가하는 방법에 대해 소개할 예정인데요.
- 먼저 민팃 모델에 사용되는 Segmentation과 Classification 태스크에서 사용되는 평가지표에는 어떤 것이 있는지
- 민팃의 Real-world 서비스에서 이러한 평가지표들을 활용할 때 중요하게 고민한 부분이 무엇인지 등
민팃에서 활용하고 있는 모델의 평가지표와 그 적용 방향성에 대해 공유하고자 합니다.
(1) 만약 민팃 서비스와 민팃의 AI 모델이 궁금하시다면:
2022.06.02 - [AI 프로젝트 소개] - [민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기
[민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기
안녕하세요! 마인즈앤컴퍼니는 지난 2019년부터 올해로 4년째 민팃 중고폰 ATM에서 사용되는 AI 모델 개발을 담당하고 있습니다. 이번 주부터 4주 간 발행되는 민팃 포스트 시리즈를 통하여 민팃
blog.mnc.ai
(2) 민팃 팀에서 데이터를 다루는 방법이 궁금하시다면:
2022.06.15 - [AI 프로젝트 소개] - [민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI
[민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI
안녕하세요! 마인즈앤컴퍼니 민팃 팀입니다. 마인즈앤컴퍼니는 지난 2019년부터 중고 휴대폰 거래 플랫폼 민팃의 ATM을 위한 딥러닝 파손 탐지 AI 모델을 개발하고 있습니다. 본 포스트는 민팃 시
blog.mnc.ai
(3) 민팃 Real-world 서비스의 운영 코드에 대해 궁금하시다면:
2022.06.30 - [AI 프로젝트 소개] - [민팃] 야 너두 할 수 있어! 유지보수가 쉬운 AI 모델 서비스 운영 코드 설계하기
[민팃] 야 너두 할 수 있어! 유지보수가 쉬운 AI 모델 서비스 운영 코드 설계하기
안녕하세요. 본 포스트에서는 AI 모델을 서비스에 반영할 때 겪을 수 있는 어려움과, 이를 해결하기 위한 효율적인 설계 방안을 소개합니다. *** 마인즈앤컴퍼니는 지난 2019년부터 중고 휴대폰 거
blog.mnc.ai
1. Segmentation 태스크를 위한 평가 Metric
민팃의 휴대폰 외관파손 탐지 AI 모델은 다음과 같이 동작합니다:
- 휴대폰 사진을 보고
- 사진에 존재하는 다양한 종류의 파손을 픽셀 단위로 탐지하여
- 파손의 종류를 기반으로 휴대폰 외관의 등급을 판정합니다.
이때 2. 사진에 존재하는 다양한 종류의 파손을 픽셀 단위로 탐지한다 라는 문제를 풀기 위하여 민팃 팀에서는 이를 Semantic Segmentation 태스크로 정의했습니다.
Semantic Segmentation이 무엇인지 궁금하시다면 첫 번째 포스트를 참조해주세요.
https://paperswithcode.com/task/semantic-segmentation
Papers with Code - Semantic Segmentation
Semantic segmentation, or image segmentation, is the task of clustering parts of an image together which belong to the same object class. It is a form of pixel-level prediction because each pixel in an image is classified according to a category. Some exam
paperswithcode.com

Semantic Segmentation 태스크는 이미지에서 특정 클래스(ex. Person)가 차지하는 영역을 찾아내고자 합니다. 따라서 Segmentation 모델의 성능을 평가할 때는
- Ground Truth : 실제로 Person이 차지하는 영역
- Predicted : 모델이 Person이라고 판단한 영역
이 두 가지 서로 다른 영역의 크기를 가지고 모델의 성능을 평가합니다.
이 차이가 적을수록 정확한 모델, 좋은 성능의 모델이라고 판단할 수 있는 것이죠.
민팃 팀에서 사용하고 있는 Segmentation 모델의 성능 평가지표는 두 가지입니다:
- IoU (Intersection over Union)
- Dice Coefficient
1.1. IoU (Intersection over Union)
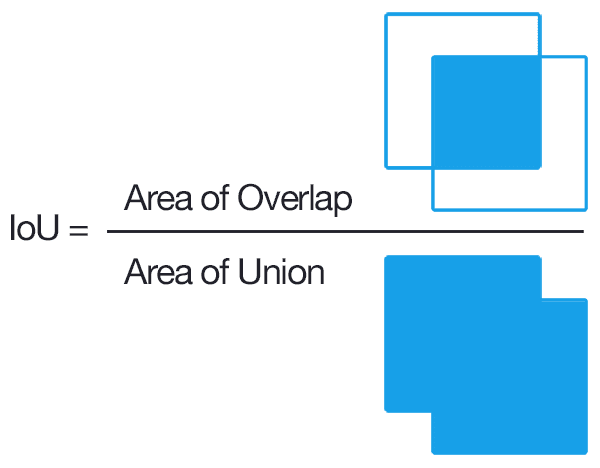
IoU(Intersection over Union)는 Segmentation 뿐만 아니라 Object Detection에서도 흔하게 사용되는 평가지표 입니다.
이 평가지표는 다음과 같은 특징을 가집니다:
- 두 영역 A, B가 주어졌을 때 (A, B의 교집합) / (A, B의 합집합)
- 두 영역의 교집합과 합집합의 크기의 차이가 작을수록 1에 가까워지고, 클수록 0에 가까워집니다.
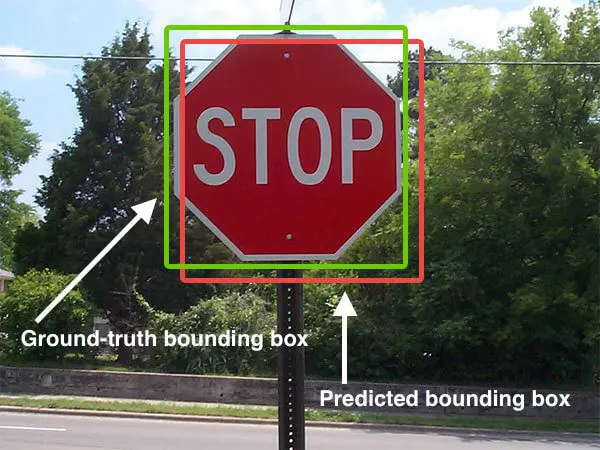

예시 그림을 보면
- 초록색 네모로 표시된 영역이 실제로 해당 클래스가 차지하고 있는 정답 영역(Ground Truth)이고
- 빨간색 네모로 표시된 영역이 모델이 해당 클래스라고 판단한 영역(Predicted bounding box)일 때
두 영역의 교집합이 크고 합집합이 작을수록 IoU는 1에 가까워지고, 교집합이 작고 합집합이 클수록 IoU는 0에 가까워집니다.
따라서 IoU가 높을수록 (1에 가까울수록) 해당 클래스 영역을 정확히 탐지하는 좋은 성능의 모델이라고 판단할 수 있게 됩니다.
1.2. Dice Score
Dice Score 또한 IoU와 유사한 컨셉을 가진 평가지표입니다. 정답 영역(Ground Truth)과 모델이 해당 클래스라고 판단한 영역(Predicted Area)을 비교하여 모델의 성능을 평가하는 것이죠.
다만 IoU는 단순히 두 영역의 교집합과 합집합의 크기를 비교하는 평가지표였다면, Dice 스코어는 두 영역의 조화평균을 구하게 됩니다.
1.2.1. 조화평균
조화평균이란 평균을 구하는 각 요소의 역수의 산술평균을 구하고, 그 값을 다시 역수로 변환하는 것인데요,
해당 요소가 전체 데이터에서 차지하는 비율을 반영한 평균을 취하고 싶을 때 사용합니다.
조화평균을 구할 때 어떤 값이 유난히 작거나 크더라도 전체적인 평균값에는 비교적 적은 영향을 미칩니다.
$HarmonicMean = {1 \over {{1 \over a} + {1 \over b} \over 2}} = {2ab \over a + b}$
평균의 종류(산술평균, 기하평균, 조화평균)
궁금증이 생기게 된 계기 모델의 성능을 평가하는 F1-score는 Precision과 Recall의 조화 평균을 사용하는 것을 보고 어떤 상황에 어떤 평균을 써야하는지에 대한 궁금증이 생기게되어 이 글을 포스팅
velog.io
1.2.2. F1 score
아마 많은 분들이 익숙하게 느끼실 F1 score가 이 조화평균을 사용하여 분류 모델을 평가하는 평가지표입니다.
F1 score는 Precision(정밀도)과 Recall(재현율) 두 가지 지표의 조화평균을 나타냅니다.
- Precision - 모델이 True라고 판단한 샘플들 중 실제로 True인 샘플의 비율
- Recall - 실제로 True인 샘플들 중 모델이 True라고 판단한 샘플의 비율
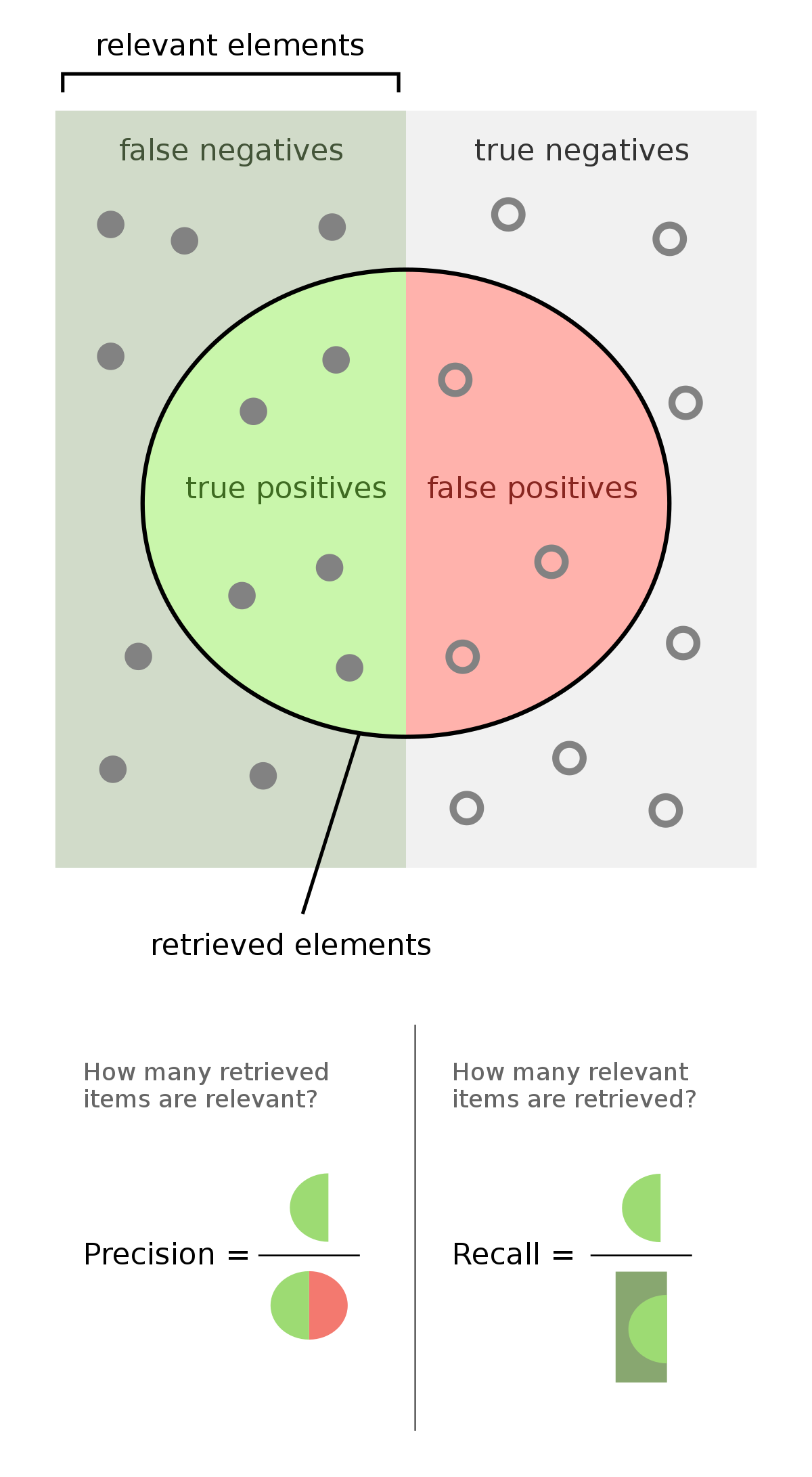
- 모델이 정답이라고 한 샘플들 중 실제로 정답인 샘플의 비율이 얼마인가? (precision)
- 실제로 정답인 샘플들 중 모델이 정답이라고 한 샘플의 비율이 얼마인가? (recall)
Precision과 Recall이 둘 다 높을수록 두 요소의 조화평균인 F1 score가 높아지고, 좋은 모델이라고 판단할 수 있게 됩니다
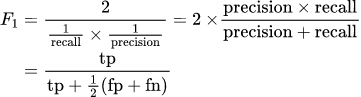
1.2.3. Dice Score
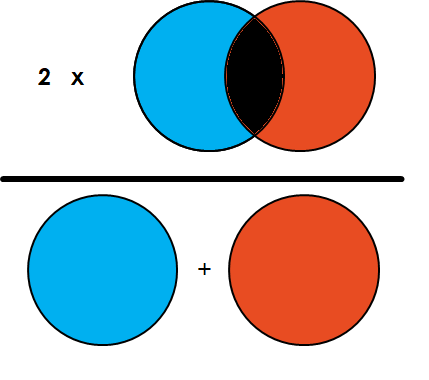
Dice Score 또한 F1 score와 같이 조화평균을 사용합니다.
위 이미지에서 파란색이 Ground Truth, 빨간색이 Predicted 영역이라고 생각하고 두 영역의 조화평균을 구합니다.
$DiceScore = {1 \over {{1 \over GT} + {1 \over Pred} \over 2}} = {2 * GT * Pred \over GT + Pred}$
다시 말해서 2 * (두 영역의 교집합 면적) / (두 영역의 면적의 합) 계산한 값이 Dice 스코어입니다. IoU, F1 score와 마찬가지로 0에서 1 사이의 값을 가지며, 0에 가까울수록 낮은 성능, 1에 가까울수록 높은 성능을 나타냅니다.
2. Classification 태스크를 위한 평가 메트릭
민팃의 휴대폰 외관파손 탐지 AI 모델의 동작 절차를 다시 한 번 보면:
- 휴대폰 사진을 보고
- 사진에 존재하는 다양한 종류의 파손을 픽셀 단위로 탐지하여
- 파손의 종류를 기반으로 휴대폰 외관의 등급을 판정합니다.
앞서 “2) 다양한 종류의 파손을 픽셀 단위로 탐지하기” 의 Segmentation 모델을 평가하는 평가지표에 관해 알아보았는데요.
이번에는 “3) 파손 종류를 기반으로 휴대폰 외관 등급을 판정하기” 에서 활용되는 Classification 평가지표를 알아보겠습니다. 사실 평가지표는 F1 스코어와 Kappa 두 가지를 사용하고 있는데요, 앞에서 F1 스코어를 이미 다루었으므로 Kappa에 대해서 보겠습니다.
2.1. Kappa
2.1.1. Kappa score
Cohen’s Kappa라고도 불리는 Kappa score는 두 관찰자가 한 샘플에 대해서 동일한 판정을 내릴 확률을 활용하여 분류 모델의 성능을 평가합니다.
두 관찰자라고 하니까 좀 헷갈리지만 우리의 경우에는 정답과 모델의 판정 결과 간 동일한 판정을 내릴 확률을 계산하면 됩니다.
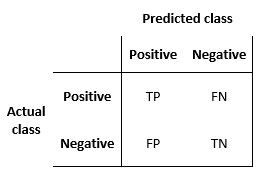
$\kappa = (p_o - p_e) / (1 - p_e)$
Po : 두 관찰자가 동일한 판정을 내린 실제 비율
두 관찰자의 판정을 관측했더니 결과적으로 Po의 비율로 동일한 판정을 내렸더라 하는 수치를 의미합니다. 우리의 경우, Accuracy와 같은 값입니다.
$p_o = {TP + TN \over TP+FP+FN+TN}$
Pe : 두 관찰자가 동일한 판정을 내릴 확률
$p_e = P(label_p) * P(pred_p) + P(label_f) * P(pred_f)$
두 관찰자(label과 pred)가 모두 Positive를 출력할 확률과 모두 Negative를 출력할 확률의 합입니다.
Po와 다른 점은 두 관찰자의 판정 결과를 비교하지 않고 따로따로 고려한다는 것입니다.
즉, 각각의 관찰자가 Positive, Negative를 출력하는 사건을 독립시행으로 보고, 두 관찰자가 동일한 결과를 출력할 확률(결합확률)을 계산합니다.
Cohen’s Kappa score은 단순한 정확도(accuracy, Po)와 달리 사건의 확률적인 측면(Pe)까지 고려하기 때문에 비교적 강인한(robust) 평가지표라고 할 수 있습니다. 보통 Kappa score가 1에 가까울수록 두 관찰자 간 판정 결과가 거의 정확히 일치한다(우리의 경우 정답과 모델의 추론이 거의 정확히 일치한다)고 봅니다.
2.1.2. Weighted Kappa score
그런데 Cohen’s Kappa score를 Class에 대한 가중치와 함께 사용하면 클래스의 순서를 고려하여 모델을 평가할 수 있게 됩니다.
순서가 있는 분류 문제(ordinal classification)에서 실제 클래스와 예측된 클래스의 순서 상 거리가 멀면 멀수록 더 큰 페널티를 부여하는 것인데요. 순서가 있는 분류 문제의 예시로는 다음과 같은 것들이 있습니다:
- 등급 분류 문제 (ex. 민팃)
- 랭킹 예측 문제 (ex. 영화 별점)

다음 논문에서는 다음과 같이 Weighted Kappa score를 설명하고 있습니다:
κ takes into account the ordering of the classes and penalizes the erroneous predictions in function of the distance between the real and the predicted class.
카파 스코어 κ는 클래스의 순서를 고려합니다. 실제 클래스와 예측된 클래스 간의 거리(distance)를 점수 계산 함수에 반영하여 해당 에러율에 대한 페널티를 부여합니다.
Weighted kappa loss function for multi-class classification of ordinal data in deep learning
Weighted Kappa is an index of reference used in many diagnosis systems to compare the agreement between different raters. This index can be also used …
www.sciencedirect.com
쉽게 말해서, A등급을 B등급으로 틀리는 것이 A등급을 D등급으로 틀리는 것보다 잘 한 것이라고 평가하여 비교적 좋은 스코어를 준다는 의미입니다.
따라서 Weighted Kappa를 모델의 평가지표로 활용하면 등급 또는 랭킹과 같이 순서가 있는 클래스를 분류하는 모델에 대한 더욱 정교한 스코어를 기대할 수 있습니다.
3. 민팃 AI 모델 Real-world 서비스를 위한 Risk Taking 전략
지금까지 민팃 팀이 Segmentation, Classification 모델을 평가하기 위해 사용하는 다양한 평가지표에 대해 알아보았습니다.
그런데 이러한 평가지표가 모델의 성능을 수치화하여 평가하는 것 뿐만 아니라 비즈니스적인 의사결정에도 활용될 수 있다는 점을 아셨나요?
Real-world에 AI 모델을 효과적으로 도입하여 서비스를 만들어내기 위해서는 테크니컬한 성능도 중요하지만, AI 모델이 이 서비스의 비즈니스 측면에서 어떤 영향을 미치고 있는지 파악하는 것 또한 중요합니다.
즉 AI 모델의 비즈니스적인 임팩트를 확인할 수 있는 지표가 필요한 것이죠.
두번째 포스트에서 우리는 AI 모델링 프로젝트의 모델 업그레이드 사이클에 대해 이야기했습니다.
2022.06.15 - [AI 프로젝트 소개] - [민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI
[민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI
안녕하세요! 마인즈앤컴퍼니 민팃 팀입니다. 마인즈앤컴퍼니는 지난 2019년부터 중고 휴대폰 거래 플랫폼 민팃의 ATM을 위한 딥러닝 파손 탐지 AI 모델을 개발하고 있습니다. 본 포스트는 민팃 시
blog.mnc.ai
이렇게 모델 업그레이드 사이클이 돌아가는 이유는 세상에 완벽한 모델이 존재하지 않기 때문입니다.
세상은 꾸준히 변화하고 이전에 본 적 없는 데이터는 끊임없이 발생합니다. 또 이미 학습했던 형태의 데이터라도 새로운 데이터에 밀려 잊혀지기도 하고, 이전에 중요했던 요소가 새로 나타난 더 중요해 보이는 요소에 밀려 영향력이 줄어들기도 합니다.
Google과 Meta가 엄청난 빅데이터 AI를 사용한 거의 완벽에 가까운 초거대 딥러닝 모델을 서비스에 올리더라도, 모델은 실수할 수 밖에 없고 현실과 가상 세계의 괴리로 인한 오류를 발생시킬 수 밖에 없습니다.
이런 실수와 오류의 영향을 줄이고 모델에 최대한 현실과 가까운 세계를 잘 반영하기 위해 모델 업데이트 사이클이 끊임없이 돌아가게 됩니다.
모델이 저지르는 실수는 주로 무척 애매하고 경계에 걸친 데이터에 대해 일어납니다. 대부분의 경우 사람이 봐도 파손이 맞는지 아닌지 분간하기 어려운 애매한 이미지가 입력되었을 때, 모델도 똑같이 헷갈리게 됩니다.
어떤 이미지를 보고 이 부분이 파손이 맞나, 아닌가…? 잘 안보이는데? 싶은 경우,
(즉 해당 픽셀에 파손에 대한 probability 값이 중간값인 0.5에 가깝게 출력된 경우)
- 조금 예민한 모델은 “파손입니다" 라고 출력하고
- 조금 둔감한 모델은 “파손이 아닙니다” 라고 출력하게 되는 것입니다.
이와 같이 둘 중 하나를 선택하기 애매한 기로에 선 상황에서 모델이 가진 특성을 잘 파악하여 비즈니스 측면에서 효과적으로 활용하는 방안을 고민하는 것이 민팃 팀의 데이터 사이언티스트의 역할입니다.
이를테면 애매한 데이터에 대해서 아주 예민하게 판정하는 모델과 좀 둔감하게 판정하는 모델 중 어떤 것을 활용하는 것이 민팃의 고객 관점에서 최선의 Value를 가져다줄 수 있을까 고민하는 것이죠.
좀 더 구체적으로는 이런 질문을 하게 됩니다:
모델이 C등급 파손을 잘 찾아내는 것이 중요하다고 할 때, 좀 가혹하게 판정하더라도 C등급을 많이 찾아내는 것이 중요할까, 아니면 좀 놓치더라도 신중하게 C등급을 찾아내는 것이 중요할까?
나올 수 있는 대답은 이런 것들이 있겠습니다:
A안 (Segment 1)
- 실제로 C등급인 휴대폰이 들어오면 무조건 찾아내는 것이 중요하다.
- 왜냐하면 실제로 C등급인 휴대폰을 B등급으로 판정하면 휴대폰을 더 비싼 가격에 매입하게 되고,
- 회사 차원에서 손해를 보기 때문.
B안 (Segment 2)
- 회사가 조금 손해를 보더라도, 확실하게 C등급인 휴대폰에 대해서만 C등급 판정을 하는 것이 중요하다.
- 왜냐하면 실제로 B등급인 휴대폰을 C등급으로 판정하면 고객 입장에서는 휴대폰이 저평가 받은 것이므로 금전적으로 손해이고,
- 따라서 서비스에 대한 만족도가 하락하기 때문.
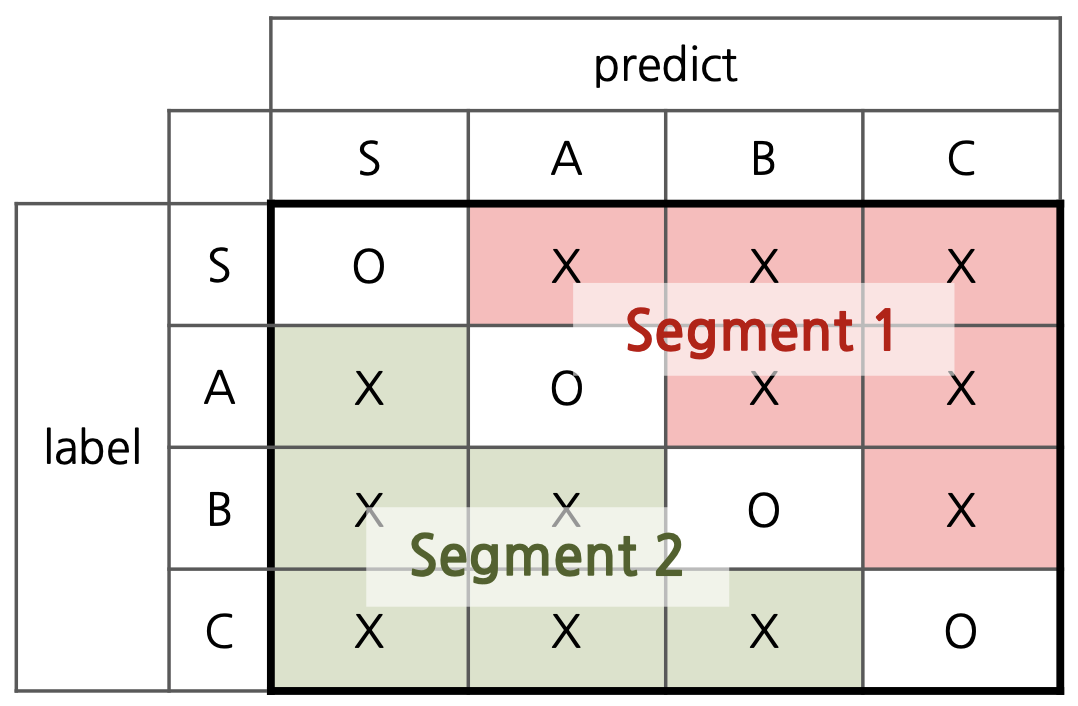
앞서 Classification에 사용되는 평가지표들에 대해서 배웠죠. 이제 우리는 A안은 Precision을 높이는 방향으로 학습한 모델을 적용하는 안이고, B안은 Recall을 높이는 방향으로 학습한 모델을 적용하는 안이라는 것을 알 수 있습니다.
Segment 1의 모델을 적용할 경우, 단말에 대해 엄격한 등급 기준이 적용되어 매입가가 낮아지고 따라서 회사의 이익은 증대됩니다. 그러나 고객의 이익은 감소하고 서비스 불만도 늘어납니다.
반면에 Segment 2의 모델을 적용할 경우, 단말에 대해 온건한 등급 기준이 적용되어 매입가가 높아지고 회사의 이익은 줄어듭니다. 그러나 단말에 대해 고평가를 받은 고객의 불만 요소가 줄어들어 서비스 만족도가 높아집니다.
결론적으로 민팃 팀에서는 모델을 평가 및 분석하고 재학습하는 과정에서 고객 관점의 Risk를 우선순위로 반영하였습니다. 사업 측면의 Risk보다는 서비스에 대한 고객 만족도와 비즈니스의 확장성을 더욱 중요한 요소로 고려합니다.
민팃 팀에서는 다양한 평가방식을 도입함으로써 민팃 파손탐지 AI 서비스의 기술적인 성능과 비즈니스 임팩트를 높이기 위해 노력하고 있습니다.
'AI to the Real World > 민팃' 카테고리의 다른 글
| [민팃] 야 너두 할 수 있어! 유지보수가 쉬운 AI 모델 서비스 운영 코드 설계하기 (0) | 2022.06.30 |
|---|---|
| [민팃] 딥러닝 파손탐지 모델 서비스 with Data-centric AI (0) | 2022.06.15 |
| [민팃] 중고 휴대폰 외관파손 탐지 AI 모델 개발기 (1) | 2022.06.02 |