E-Commerce 회사에서 데이터 직무에 재직 중인 김대리.
최근 김대리는 데이터 파이프라인의 스케줄링 관련 업무를 맡게 되었다.
해당 업무에 익숙하지 않았던 김대리는 데이터 스케줄링 프레임워크인 Apache Airflow 관련 내용을 더듬더듬 구글링을 하며 작업을 진행 중이었다.
내용이 쉽지 않아 관련 강의를 하나정도 보면 좋겠다고 생각하던 참이었는데,
마침 평소에 사용중이던 소셜 미디어에 Airflow 강의가 추천 광고로 뜨게 되었고 해당 강의를 신청하게 되었다.

나는 어쩌다 이 글을 읽게 되었을까?
아침에 눈을 뜨고 밤에 눈을 감는 순간까지 우리는 수많은 추천과 마주치게 됩니다. 음식, 옷 등 온라인 플랫폼을 통한 구매에서 연관 상품을 추천받기도 하고, 평소 즐겨 쓰는 소셜미디어에서는 새로운 친구를 추천받거나 광고를 추천받기도 합니다. 퇴근 후 맥주 한잔하며 시청하는 OTT 서비스에서도 여러 콘텐츠를 추천받습니다.
이번 글에서는 플랫폼 서비스와 불가분의 관계에 있는 추천 시스템에 관해 이야기하고자 합니다.
최근 마인즈앤컴퍼니에서 수행했던 프로젝트인 국내 제조사 추천 시스템과 함께 추천 알고리즘의 전반적인 내용을 소개하겠습니다.
본 프로젝트는 국내 제조사의 상품 판매 플랫폼에 배포할 추천 시스템을 개발하는 것이 목표였습니다. 먼저, 문제상황을 이해하고 문제를 정의하는 것으로 프로젝트를 시작하였습니다.
문제 상황
- 상품 판매 플랫폼은 개발 중이므로 기존에 보유하고 있는 데이터로 모델링을 진행해야 합니다.
- 기존 데이터는 상품에 대한 Explicit Data(평점, 선호도와 같이 고객의 직접적인 표현을 기록한 데이터)가 존재하지 않습니다.
- 기존 데이터에는 Implicit Data(고객의 선호를 간접적으로 표현한 데이터)가 존재하나 충분하지 않습니다. 하지만 플랫폼 런칭 후에는 충분한 Implicit Data의 확보가 가능합니다.
문제정의
기존에 보유한 데이터로 개발이 가능하며, 추후 데이터가 정교화되고 확장되었을 때에도 최소한의 노력으로 유지보수가 가능한 추천 시스템을 모델링하기
추천 시스템은 Explicit Data를 사용하는지 Implicit Data를 사용하는지에 따라서 활용 가능한 알고리즘이 달라집니다.
그래서 문제 해결전략을 데이터 유형에 따라 크게 2가지로 생각해 볼 수 있습니다.
전략1. Explicit Data가 없기 때문에 특정 Rule를 정의하여 산출한 값을 Explicit Data 대신 사용하여 모델링을 진행한다.
전략2. Implicit Data를 사용하여 모델링하고 추후 수집될 Implicit Data에도 대응 가능한 모델링을 진행한다.
어떤 전략이 본 프로젝트에 더 적합한지 분석하기 위해 Explicit Data와 Implicit Data 차이, 추천 시스템 알고리즘 유형별 특성을 파악합니다.
Explicit Data vs Implicit Data

Explicit Data
- 고객이 상품에 대한 선호도를 직접적으로 표현한 데이터 (평점, 좋아요/싫어요, 리뷰 등)
- 고객의 선호를 명확히 알 수 있는 정보지만 고객이 적극적으로 자신의 선호를 표현하는 경우는 적기 때문에 데이터를 얻기 어렵습니다.

Implicit Data
- 고객의 상품에 대한 선호도를 간접적으로 파악할 수 있도록 도움을 주는 데이터 (검색기록, 구매내역, 장바구니 내역 등)
- 고객이 개인정보제공에 동의만 하면 수집이 가능하므로 데이터를 얻기 쉬우며 많은 양의 데이터를 얻을 수 있습니다.
- Explicit Data에는 고객의 호/불호 정보가 모두 포함되어 있지만, Implicit Data는 불호 정보가 없습니다. 그래서 모델링 시 불호 정보를 따로 준비해야 합니다. 수집되지 않은 상품 데이터가 고객이 싫어서 제외됐는지 인식하지 못해서 제외됐는지는 알 수 없지만 불호 정보가 포함되어 있을 가능성이 크므로 Unobserved Data도 포함하여 모델링을 해야 합니다.
- Implicit Data에는 Noisy가 많습니다. 상품을 좋아하지 않아도 실수로 상품을 클릭할 수도 있고, 단순 호기심에 클릭하는 경우도 있을 것입니다. 미디어 콘텐츠의 경우는 교육과제 때문에 소비하는 경우도 있습니다. 이 외에도 고객의 선호와는 상관없는 데이터가 수집되는 경우는 많기 때문에 Implicit Data에는 기본적으로 Noisy가 있다는 것을 인지하고 있어야 합니다.
- Implicit Data에서 동일 상품/페이지에 대한 클릭 횟수, 노출시간 등의 수치는 선호도를 간접적으로 유추할 수 있는 정보가 됩니다. Implicit Data에는 기본적으로 Noisy가 있기 때문에 높은 수치가 꼭 강한 선호도를 의미한다고 말할 수는 없습니다. 하지만 빈도, 시간 등의 수치는 고객의 선호도를 간접적으로 표현했을 가능성이 높습니다.
추천 시스템 알고리즘 유형별 특성
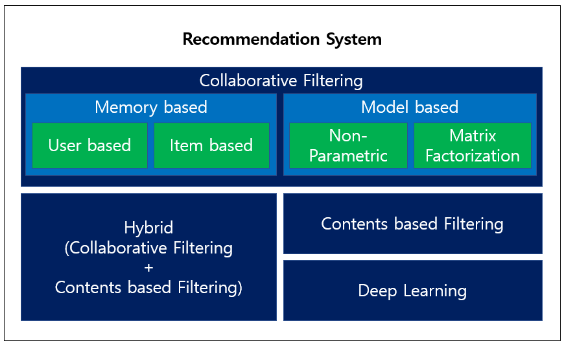
추천 시스템 알고리즘을 유형화하면 위 그림과 같이 분류할 수 있습니다.
Collaborative Filtering(CF)을 비교적 많이 사용하며 CF의 단점을 보완해 줄 수 있는 Contents based Filtering를 함께 사용하는 Hybrid 모델도 존재합니다. 최근에는 Deep Neural Net을 활용하여 추천 성능을 높인 모델도 발표되고 있습니다.
Collaborative Filtering(CF)
CF는 사용자와 아이템 간의 선호도 데이터를 기반으로 진행하며 Memory based, Model based 2가지 접근법이 존재합니다.
Memory based
추천 대상자와 유사한 사용자를 찾아 유사한 사용자가 선호했던 상품을 추천하는 User based 방식과, 추천 대상자가 선호했던 상품과 유사한 상품을 찾아 유사한 상품을 선호한 사용자들이 공통적으로 좋아했던 상품을 추천하는 Item based 방식이 존재합니다.
매개변수를 학습하지 않는 단순 산술 연산만으로도 계산이 가능합니다. 하지만 데이터가 커질수록 계산량도 같이 증가하기 때문에 데이터 확장에 문제가 발생할 수 있습니다.
쉽게 만들 수 있고 결과의 설명력이 좋은 장점이 있지만, 사용자가 소비한 상품들이 전체 상품 종류 개수에 비해 적어서 Sparse 한 데이터가 만들어지는 경우에는 모델 성능이 저하되는 단점이 있습니다.
Model based
PCA(Principal Component Analysis), SVD(Singular Value Decomposition), Matrix Factorization 등 머신러닝 기법을 활용하여 사용자가 평가하지 않은 상품의 선호도를 예측하는 방식입니다.
결측치가 있거나 Sparse 한 데이터도 처리가 가능한 장점이 있지만, latent factor 때문에 결과의 설명력이 낮다는 단점을 갖습니다.
Contents based Filtering
Contents based Filtering은 추천 대상자가 소비한 상품의 특성과 유사한 특성을 갖는 다른 상품을 추천하는 방식입니다. 상품의 특성으로는 기본적인 제품 스펙, Tag, 제품 관련 이미지 및 텍스트 등이 있습니다.
CF의 Item based 방식과의 차이를 보면, Item based 방식은 User-Item Matrix(소비이력)을 활용하는 반면, Contents based Filtering은 Item의 특성정보를 활용합니다.
사용자의 상품 소비이력 정보를 주로 사용하지 않기 때문에 Cold Start 문제(신규 고객/상품인 경우 과거 이력이 없어 추천이 어렵다는 문제)를 어느 정도 해소할 수 있다는 장점이 있지만, 사용자의 성향을 파악하기 어려우며 상품의 특성을 온전히 함축하는 것에 한계가 존재한다는 단점이 있습니다.
Hybrid(CF + Contents based Filtering)
Contents based Filtering은 CF의 문제점인 Cold Start를 해결해 줄 수 있기 때문에 CF와 Contents based Filtering을 조합하여 사용하는 Hybrid 모델이 발전하였습니다.
Deep Learning based Model
선호도 정보뿐만 아니라 사용자의 행동정보(온라인상에서 발생하는 사용자 로그)도 활용하여 추천 시스템 모델링을 할 수 있는 방식입니다. Deep Neural Network는 Feature 간 상호작용을 학습하는 것에 용이하기 때문에 사용자 행동정보들의 상호작용을 학습하여 추천 상품을 예측하는 데에 도움을 줍니다.
eXtreme Deep Factorization Machine(xDeepFM)
Neural Network를 구성요소로 활용하는 추천 시스템 알고리즘 중 하나입니다. 사용자의 선호도 정보 외에도 다양한 Feature를 활용하여 추천을 할 수 있습니다.

- 명시적인 방식 또는 벡터 수준에서 Feature 간 상호작용을 생성하고 학습할 수 있도록 새로운 Compressed Interaction Network(CIN) 구조를 사용합니다.
- CIN과 Deep Neural Net을 활용하여 Low-Order, High-Order Feature Interaction 학습이 가능합니다.
- Sparse data 학습이 가능하며 CIN과 Deep Neural Net이 Embedding layer를 공유하므로 학습시간의 이점이 존재합니다.
- User, Item, User behavior 관련 Feature를 모델 학습 Input으로 사용 가능합니다.
- 입력정보의 개수에 따라 Input vector의 길이가 가변적입니다.
- Cold Start 문제에 대해 Robust한 알고리즘입니다.
전략분석
전략1. Explicit Data가 없기 때문에 특정 Rule를 정의하여 산출한 값을 Explicit Data 대신 사용하여 모델링을 진행한다.
Explicit Data를 대체할 수 있는 값을 산출하는 Rule를 만들기가 상당히 까다롭습니다. Explicit Data는 고객의 호/불호를 명확히 알 수 있는 정보이기 때문에 매우 정교한 Rule를 정의해야 왜곡을 최대한 줄일 수 있습니다. 하지만 정교한 Rule을 만들기 위해서는 현업과의 긴밀한 의사소통이 필요하며, Rule 정의를 위한 데이터분석도 상당 부분 진행돼야 하기 때문에 프로젝트 기간 내 완료가 어렵습니다.
상품 판매 플랫폼 런칭 후 새로운 Feature가 수집되면 해당 Feature를 포함한 Rule을 재생성해야 합니다. 완전히 새로운 Rule를 만드는 작업이 되기 때문에 상당한 노력이 필요합니다.
상품판매 플랫폼 런칭 후부터는 Explicit Data를 수집하는 방안도 생각해볼 수 있으나 Explicit Data를 남기는 고객수는 매우 적기 때문에 모델링을 하기위한 데이터를 충분히 모으기에는 시간이 걸릴 수 있으며, 플랫폼 런칭 전 개발한 추천 시스템 모델을 사용할 수 없게 됩니다.
전략2. Implicit Data를 사용하여 모델링하고 추후 수집될 Implicit Data에도 대응 가능한 모델링을 진행한다.
Implicit Data이기 때문에 모델링에 바로 활용이 가능합니다. 하지만 사용 가능한 데이터가 많지 않기 때문에 모델 성능상에 문제가 발생할 수 있습니다.
상품판매 플랫폼 런칭 후 수집되는 사용자의 행동정보(온라인상에서 발생하는 사용자 로그)는 더 풍부한 정보를 제공할 수 있으며, 수집이 쉽습니다. 그래서 모델 성능 향상의 여지가 존재합니다.
추천 시스템 알고리즘의 변경 없이 Input 데이터 변경만으로 재학습이 가능한 모델이 존재하기 때문에 상품판매 플랫폼 런칭 후 상황에도 대응이 가능합니다.
전략분석 결과
프로젝트의 전반적인 상황과 추천 시스템 알고리즘의 특성을 고려하여 “전략2. Implicit Data를 활용한 모델링” 을 진행하기로 결정했습니다. 앞서 살펴보았던 xDeepFM 추천모델 알고리즘을 활용하기로 하였습니다. 그 이유는 다음과 같습니다.
- xDeepFM은 Rating 정보가 반드시 필요하지 않으며 고객정보, 상품정보, 고객 행동정보를 활용한 모델링이 가능합니다. 그래서 Implicit Data만 존재하는 현 상황에 사용 가능합니다.
- xDeepFM은 Input Data의 길이가 가변적이기 때문에 모델에 대한 수정 작업 없이 Implicit Feature를 추가, 수정, 삭제하여 재학습할 수 있습니다. 이는 사용자의 Rating 정보를 수집하거나 새로운 Rule를 정의하여 Explicit Data를 생성하여 모델링하는 것보다 더 적은 비용이 발생할 것으로 예상됩니다.
- xDeepFM은 Collaborative Filtering 모델보다 Cold Start 문제에 더 Robust 합니다.
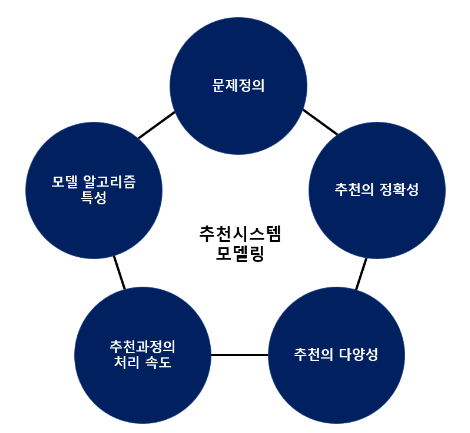
문제 상황에 맞는 추천을 하기 위해서는 추천의 정확성, 추천의 다양성, 추천 과정의 처리속도를 고려하여 추천 시스템 모델링을 진행해야 합니다. 문제 상황마다 정확성, 다양성, 처리속도의 요구 정도가 다르고 추천 시스템 알고리즘마다의 특성이 있기 때문에 문제상황에 대한 정확한 이해와 정의를 선행하고, 이에 적합한 추천시스템 알고리즘을 선정하는 것이 원하는 결과를 만들어내는 초석이 됩니다.
국내 제조사 추천시스템 프로젝트를 진행하며 데이터를 전처리하고 모델을 학습하는 것도 중요하지만 이에 못지않게 문제를 정의하고 적합한 모델 알고리즘을 선정하는 것도 중요하다는 것을 다시 한번 상기할 수 있었습니다.
독자분들도 코딩과 함께 문제를 보는 안목을 높이는 하루 보내시길 바랍니다.
감사합니다.
'AI to the Real World' 카테고리의 다른 글
| TrOCR을 활용한 Text Recognition 모델 개발기 (0) | 2022.12.16 |
|---|---|
| 마이데이터 활용을 위한 업종 분류 모델 개발기 (0) | 2022.09.07 |
| SNU 빅데이터 핀테크 캡스톤 프로젝트 후기 (0) | 2022.08.22 |