안녕하세요. 마인즈앤컴퍼니입니다.
연세대학교 현장실습 프로그램으로 최명헌님, 김서연님께서 6주간 참여해주셨는데요.
마이데이터 구축에 필요한 가맹점 업종 분류 모델을 개발하고, 해당 모델로 웹사이트까지 구현하며 탄탄한 실무 경험을 쌓을 수 있었다고 합니다. 인턴 프로그램을 성공적으로 수료하고 그 과정을 김서연님이 작성해주셨습니다.
마인즈앤컴퍼니는 학점 연계로 오시는 학생 인턴분들을 특히나 더 아끼고 챙겨주려고 합니다.
의미 없는 잡무를 하면서 일손을 거드는 게 아니라 실무 경험을 쌓고 그 과정에서 많은 것을 체득할 수 있도록 든든한 선배들이 되어줄 것이니 학생분들 많관부 🤗
안녕하세요, 저희는 연세대학교 현장실습 프로그램으로 마인즈앤컴퍼니에서 근무하고 있는 최명헌, 김서연 인턴입니다!
이번 글에서는 저희가 6주간 참여한 프로젝트를 소개해드리려고 합니다.
마이데이터란?
지난 1월부터 금융위원회는 개인의 동의 하에 제3자가 개인의 금융정보에 접근하고 가공할 수 있게 하는 마이데이터 서비스를 시행하고 있습니다. 본인이 직접 본인 데이터의 권리를 행사할 수 있게 되면서, 기업에서 개인으로 데이터 관리의 주체가 이동하게 된 것이죠. 이전까지는 타사가 가지고 있는 고객의 금융정보나 소비내역을 볼 수 없었지만, 앞으로는 금융 데이터를 API 형식으로 제공 받아 여러 곳에 흩어져 있던 데이터를 한 곳에 모아볼 수 있게 되었습니다.
마이데이터 서비스는 EU, 미국, 영국, 일본 등 많은 국가에서 이미 시행되고 있는 추세입니다. EU에서는 2007년부터 PSD(Payment Services Directive)를 시행하여 금융 기관과 비금융 기업 간 정보 공유를 가능하게 함으로써 지급결제시장의 성장을 촉구하고 있습니다. 영국 역시 적극적으로 은행이 API를 공개하는 오픈뱅킹을 추진하고 있는데, 제3사업자가 이를 활용해 서비스를 개발할 수 있게 되면서 영국 금융 산업에 폭넓은 가능성을 제공할 수 있게 되었습니다.
마이데이터의 활용
해외에서 시행하는 마이데이터 관리 서비스로는 Mint가 있는데요, 미국의 핀테크 기업 Intuit가 2009년 인수한 Mint는 북미에서 3천만 이상이 사용하는 개인 자산관리 서비스입니다. Mint에서 제공하는 기능으로는 소비 분석, 고정지출 관리, 맞춤형 분석 리포트 제공, 예산 관리 등이 있습니다.

마이데이터 서비스로 제공이 가능한 정보로는 은행, 보험, 금융투자, 저축은행, 통신 등이며 점진적으로 그 범위를 늘려갈 계획이라고 합니다. 그렇다면 마이데이터를 어떻게 활용할 수 있을까요?
- 하나의 서비스에서 데이터를 종합적으로 조회할 수 있습니다.
- 소비패턴을 분석해서 현금의 흐름을 파악할 수 있습니다.
- 고객의 소비 패턴과 설정한 자산목표에 맞는 금융상품을 추천할 수 있습니다.
- 고객들의 금융 정보를 분석해서 다양한 고객에게 필요한 금융 서비스를 개발할 수 있습니다.
이제는 금융과 비금융권 간의 경계가 없기 때문에 너도나도 앞다투어 마이데이터 분석 서비스를 출시하고 있는 추세입니다. 은행 역시 가장 적극적으로 서비스 개발에 앞장서고 있는 기관인데요, 업체명의 업종을 분류할 수 있는 모델이 필요하다는 은행의 요청에 따라 저희는 가맹점 업종 분류 모델을 개발하게 되었습니다.
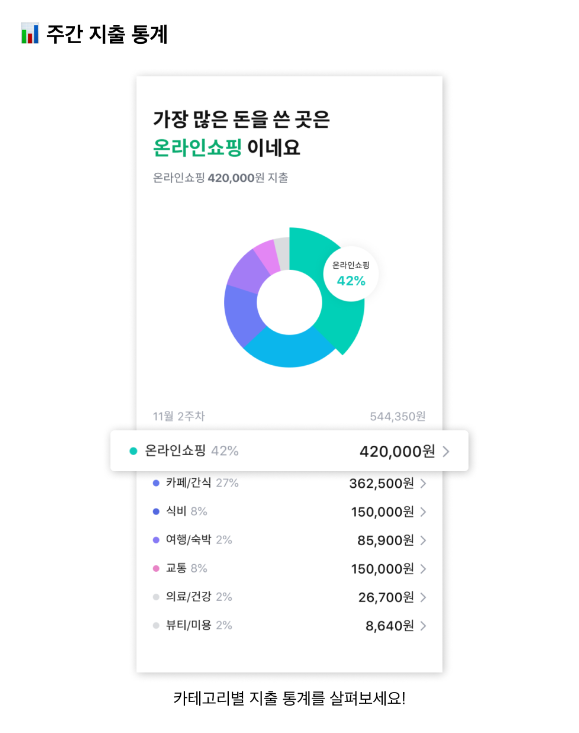
개인의 소비 패턴을 카테고리 별로 확인할 수 있다면 지출 관리가 더 쉬워지지 않을까요?
카드 결제를 하게 되면 하단 좌측 그림처럼 결제일자와 결제한 업체 이름 등이 알림으로 뜨는데요, 이 업체가 어떤 업종인지에 대한 정보는 주어지지 않습니다. OO마트는 대형마트, XX 카페는 카페와 같이 업체명을 보고 자동으로 분류할 수 있다면 고객이 어떤 업종에서 가장 많이 소비하며 과거 대비 어디에서 추가 지출이 발생했는지 파악이 가능할 것입니다. 또한 카테고리 별로 예산을 설정해서 지출을 관리할 수 있겠죠. 기업들은 고객에게 맞춤형 분석 리포트를 제공하며, 그들의 소비 습관에 맞는 금융상품을 추천하고 개발할 수 있습니다.

데이터 설명
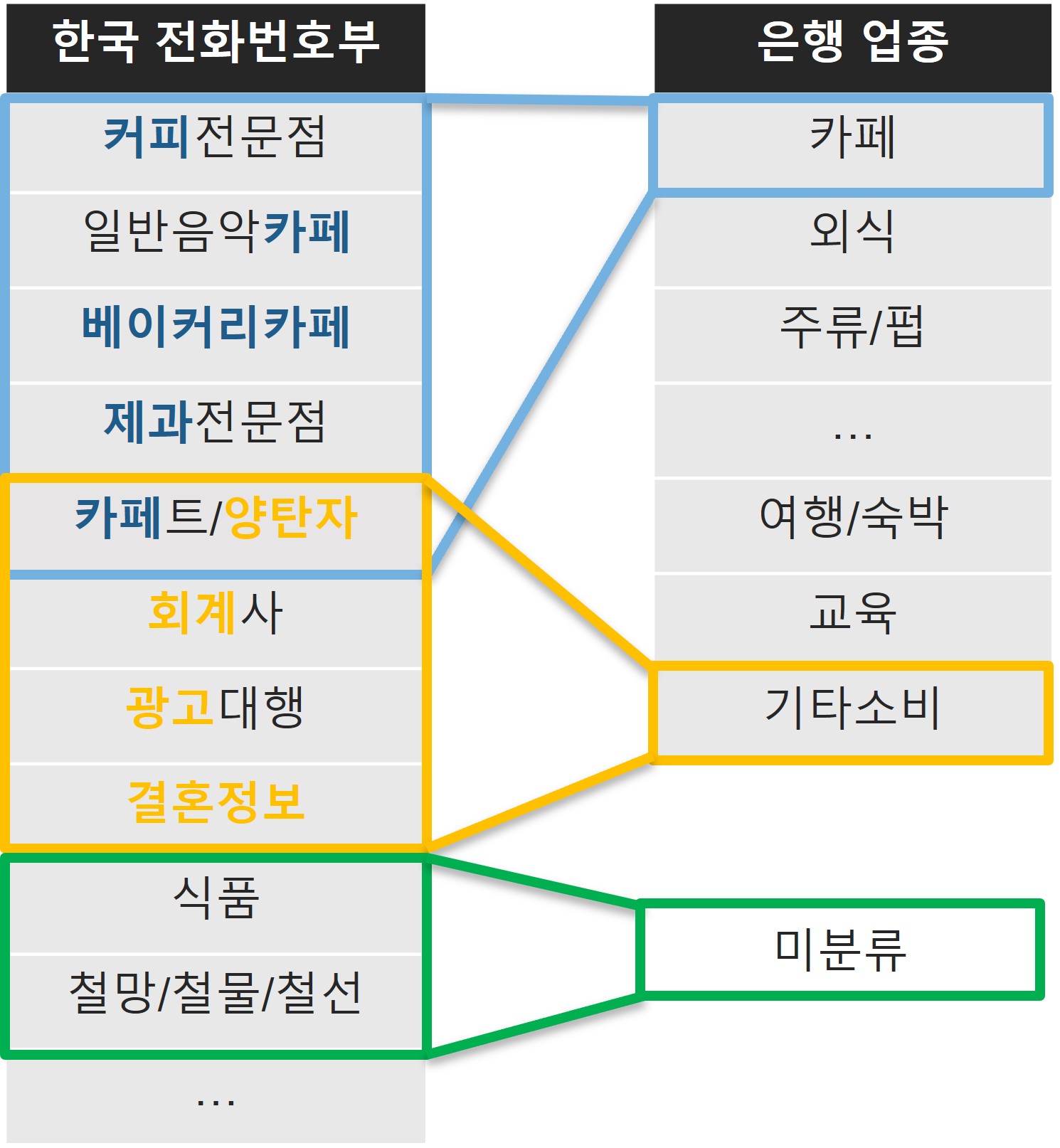
저희는 한국전화번호부 사이트에서 약 2000개의 업종에 해당하는 265만여 개의 업체 데이터를 얻을 수 있었습니다.
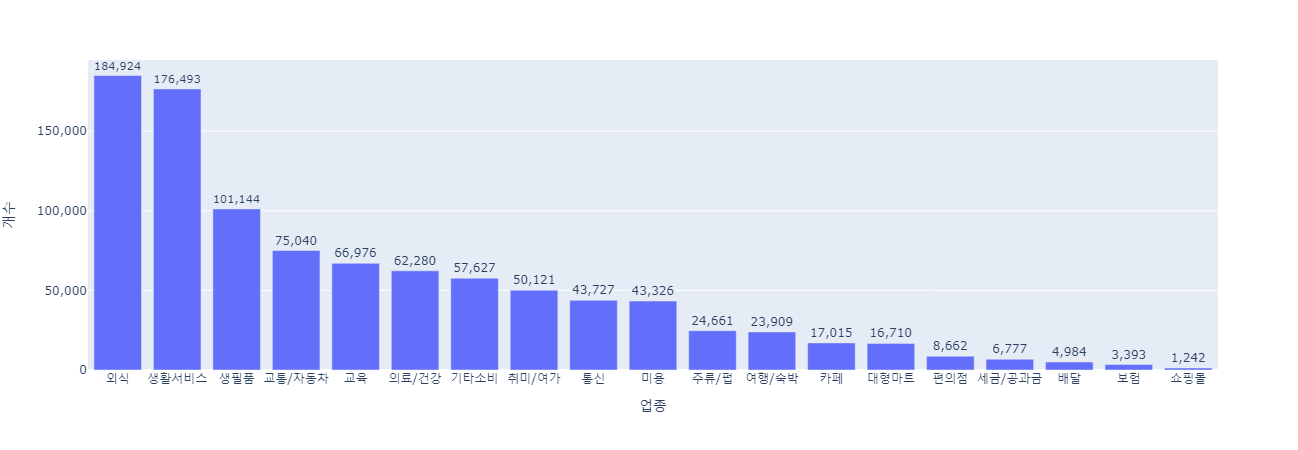
카페 외식 주류/펍 배달 편의점 대형마트 생필품 생활서비스 통신 쇼핑몰 의료/건강 미용 교통/자동차 취미/여가 여행/숙박 교육 세금/공과금 기타소비 보험 총 19개의 클래스에 대해 multi-class classification task를 진행했습니다.
전처리
전화번호부 데이터에 있는 2000개의 업종은 프로젝트에서 사용할 19종에 비해 너무 세분화되었고, 건설자재, 종교단체 등 일반적으로 소비가 잘 이루어지지 않는 업종이 다수 존재했기 때문에 업체가 1000개 이상 존재하는 업종만 고려했고, 일반적이지 않은 업종은 제외하였습니다.
데이터 라벨링
전화번호부 데이터의 업종 분류를 주어진 19개의 업종에 맞추기 위해 저희는 업종 별 키워드를 사용했습니다.
1. 먼저 업종 별로 키워드를 선정하고

2. 전화번호부 데이터의 업종명에 키워드가 해당한다면 해당 업종에 매칭합니다.
3. 만약 키워드가 두 개 이상의 업종에 해당하거나 어디에도 해당되지 않는다면 직접 검수를 통해 분류했습니다.
데이터 전처리
라벨링이 완료된 데이터에 대해 다음의 전처리 과정을 수행했습니다.
1. 업체명과 업종이 일치하는 데이터는 제거했습니다. 예를 들어 업체명이 ‘스타벅스’인 가게가 131개 존재했고, 라벨링 과정에서 모두 카페로 라벨링 되었습니다. 이렇게 되면 중복 샘플이 생기기 때문에 하나만 남기고 모두 제거하였습니다.
2. 업체명은 같으나 업종이 다른 데이터는 업종 분포를 확인한 다음 가장 많은 업종으로 분류했습니다. 예를 들어 ‘토마토’라는 이름은 같지만 업종이 다른 업체가 여러 곳 존재하는데, 이 업체는 주류/펍이 가장 많은 관계로 주류/펍으로 분류하였습니다.

3. 정규표현식을 사용하여 기호를 제거하고 중복되는 업체명은 제거했습니다. 예를 들자면 ‘베이징 덕’과 ‘베이징.덕’은 기호를 제거하면 업체명이 ‘베이징덕’으로 중복되므로 제거하는 식입니다.
전처리를 거쳐 최종적으로 965,404개의 데이터를 얻었습니다. 가장 많은 클래스는 18만여개의 외식, 가장 적은 클래스는 1200여개의 쇼핑몰로, 클래스 분포가 매우 불균형한 데이터임을 확인할 수 있었습니다.
모델 소개
분류 모델을 만들기 위해서 세 가지의 모델을 사용했는데요, 차례대로 소개해드리도록 하겠습니다.
1) KoBERT
Korean Bidirectional Encoder Representations for Transformers
BERT는 구글이 발표한 트랜스포머 기반의 사전학습 모델로, 한국어에 대한 성능의 한계를 극복하기 위해 KoBERT가 개발되었습니다.
위키피디아, 뉴스 등에서 수집한 500만 여개의 문장으로 이루어진 코퍼스에 대해 학습했으며, 데이터로 훈련된 SentencePiece 토크나이저를 사용하여 기존 대비 27%의 토큰으로 2.6% 이상의 성능 향상을 기록했다고 합니다.
KoBERT의 베이스라인 모델인 BERT base 모델은 12개의 트랜스포머 층, 768차원의 hidden size, 12개의 어텐션 헤드로 구성되어 있습니다.

2) KoELECTRA
Efficiently Learning Encoder that Classifies Token Replacements Accurately
BERT는 하나의 데이터 중 15%에 대해서만 마스킹해서 학습하기 때문에 손실이 발생하기 쉽고 비용이 많이 들며, 학습 시에는 마스킹 토큰을 학습할 수 있지만 추론 과정에서는 마스킹 토큰이 존재하지 않는다는 한계가 있습니다.
따라서 ELECTRA는 이 한계점을 극복하기 위해 Generator 모델을 이용해 일부 토큰을 가짜 토큰으로 바꾸고, Discriminator 모델이 해당 토큰이 가짜인지 진짜인지 분류하는 Replaced Token Detection 태스크를 적용했습니다. Generator 모델의 메커니즘은 BERT의 Masked Language Modeling과 같습니다.
Generator과 Discriminator 모델이 등장하기 때문에 GAN과 유사해 보이지만, GAN은 새로 생성된 토큰에 대해 가짜로 간주하는 반면 ELECTRA의 Discriminator 모델은 진짜로 간주한다는 차이가 있습니다. 또한 adversarial하게 학습하지 않는다는 점에서 GAN과 다르다는 것을 알 수 있습니다.

3) RoBERTa
Robustly optimized BERT pretraining approach
RoBERTa는 BERT가 underfitted된 점을 극복하기 위해, BERT와 비교해서 더 큰 batch size와 방대한 데이터로 학습되었습니다. 또한, masking하는 토큰의 위치를 계속 바꾸는 Dynamic Masking을 적용한 모델입니다.
그 중 한국어 사전학습 모델인 Klue/RoBERTa는 KLUE Benchmark에서 공개한 한국어 자연어 이해 데이터셋으로 사전학습되었습니다.

실험 설명
데이터
96만 개의 데이터 중 10만 개를 테스트 데이터셋으로 고정하고, 나머지 데이터에 대해 8:2의 비율로 train과 valid 데이터셋으로 나누었습니다. 따라서 데이터셋의 개수는 train: valid: test = 69만: 17만: 10만으로 분리하였습니다.
전처리 단계에서 중복 제거와 정규표현식을 제외하면 별다른 전처리를 거치지 않았는데, 실험 과정에서 다양한 버전의 데이터셋을 실험해보기로 하였습니다. 따라서 영어를 모두 소문자로 변환한 uncased/대문자를 살린 cased/숫자를 제거한 nonumber까지 총 세 종류의 데이터셋을 저장하여 실험해보았습니다.
실험 구성
저희는 사전학습 모델을 사용했는데, 이 모델들은 이미 방대한 데이터에 대해 학습한 모델이기 때문에 하이퍼파라미터 튜닝의 효과가 미미할 것이라고 판단했습니다. 따라서 시퀀스의 최대 길이와 손실함수를 바꿔가며 실험해보기로 결정했습니다.
시퀀스의 최대 길이는 하나의 데이터의 길이를 의미합니다. 다시 말해 업체 이름의 길이라고도 할 수 있겠습니다. 저희는 26과 32 두 종류로 실험했는데, 데이터를 확인했을 때 보통 카드사에서 26자까지 표시하는 것으로 확인했기 때문에 26, 그리고 더 긴 업체명이 존재할 수 있으므로 32로 설정했습니다.
손실함수는 Cross Entropy, Focal Loss, Weighted Cross Entropy 세 개를 번갈아 바꿔가며 실험해보았습니다. 이 프로젝트는 다중 분류 태스크로, 보통 다중 분류 문제에서는 cross entropy 함수를 손실 함수로 사용합니다. 하지만 앞서 언급했듯 불균형한 데이터의 특성 상 Cross Entropy보다는 클래스마다 다른 가중치를 주는 손실함수를 사용하는 것이 더 효과적일 수도 있겠다고 판단하였습니다.
Focal Loss는 분류 성능이 높은 클래스에 대해서는 낮은 가중치를, 분류하기 어려운 클래스에 대해서는 높은 가중치를 주는 손실함수이고, Weighted Cross Entropy 함수는 이름에서 유추할 수 있듯이 클래스에 업종 별 비율의 역수만큼의 가중치를 부여하여 적은 수의 클래스에 더 많은 가중치를 주는 손실함수입니다.
여담) WeightedRandomSampler 실패기
데이터 불균형을 다루기 위해서 저희는 다양한 방법을 시도했는데요, 그 중 하나가 PyTorch의 WeightedRandomSampler사용이었습니다. 수가 적은 클래스의 데이터는 데이터 샘플링을 할 때 그만큼 적게 뽑힐 것이고, 그렇게 되면 적은 수의 클래스는 학습 배치에 적게 반영될 수 밖에 없습니다.
이 문제를 해결하기 위해 WeightedRandomSampler를 사용하였는데, 데이터 개수의 역수만큼, 즉 (전체 데이터 개수/해당 클래스의 데이터 개수)만큼 가중치를 곱하여 데이터가 샘플링될 수 있는 확률을 높여주는 방법입니다. PyTorch에서는 RandomSampler 클래스를 제공하고, DataLoader에서 sampler를 지정할 수 있도록 해놓았습니다.
하지만 WeightedRansomSampler를 적용한 경우와 그렇지 않은 경우의 성능에 유의미한 차이가 보이지 않아 결국 최종적인 모델에서는 사용하지 않았습니다.
실험 결과
사전학습 모델 실험
모델 공통 configuration:
- data: uncased
- batch size: 256
- epoch: 5
- dropout rate: 0.5
- learning rate: 5e-5
- max grad norm: 1
- warmup ratio: 0.1
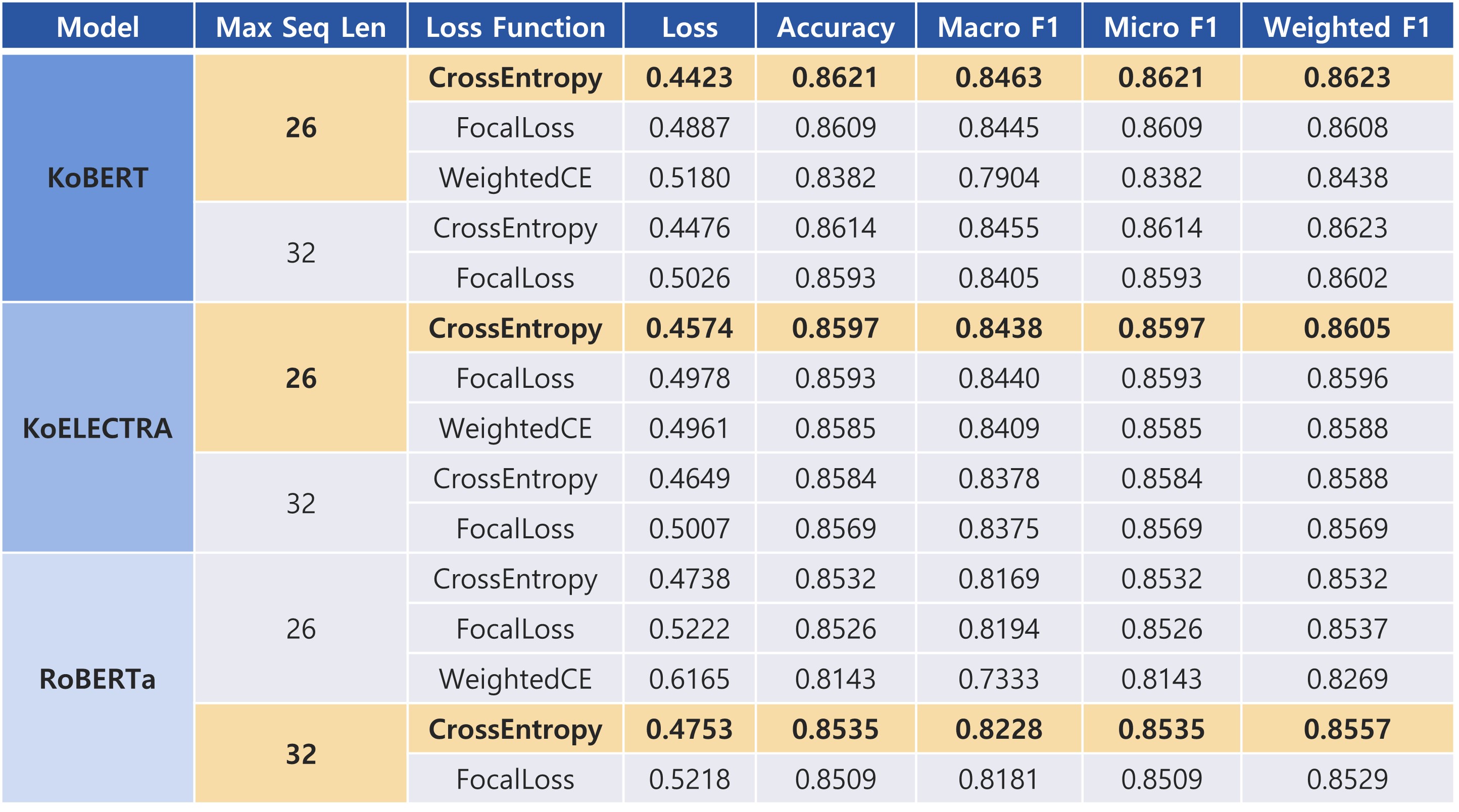
시퀀스의 길이와 손실함수를 바꿔가며 실험한 결과, KoBERT-26-Cross Entropy를 사용한 실험이 validation loss 0.4423, weighted F1 score 0.8623으로 가장 성능이 좋았습니다. 앞서 저희 데이터셋이 불균형한 클래스 분포를 보인다고 말씀드렸는데요, 그렇기 때문에 세 종류의 F1 score을 사용해서 성능을 평가했습니다.
- Macro F1은 각 클래스의 F1 score을 평균 낸 점수입니다. 따라서 클래스의 불균형은 고려되지 않았습니다.
- Weighted F1은 각 클래스의 F1 score에 전체 데이터에 대한 클래스의 비율을 곱해서 평균 낸 점수입니다.
- Micro F1은 전체 클래스에 대해 TP, FP, FN을 구해서 F1을 계산한 점수입니다.
다음으로 가장 좋은 성능을 보인 KoBERT-26-Cross Entropy 모델에 대해 세 가지의 데이터셋을 바꿔서 실험을 진행해보았습니다. 그 결과 숫자를 제거하지 않고 영어는 모두 소문자로 변환한 uncased 데이터셋이 가장 좋은 결과를 보였습니다.

예시
다음은 오분류한 예시입니다. 대체로 매우 준수한 성능을 보였는데요, 제대로 분류하지 못한 샘플 중 특이한 케이스 몇 가지를 소개해드릴까 합니다.
1) 사람이 봐도 업종을 예측하기 힘든 경우

위 표에 나와있는 업체명은 사람이 보기에도 가게 이름에서 업종의 힌트를 찾기 어렵습니다. 모델이 제대로 예측하지 못 할 만 해보입니다.
참고로 한국전화번호부에 등록된 바에 따르면 이씨스는 자동차 부품 제조, 홍종국은 부동산중개업이라고 합니다.
2) 데이터가 잘못된 경우

저희는 한국전화번호부 사이트에서 업체 데이터를 크롤링해서 학습에 사용했는데요, 업체에 등록된 업종 자체가 이상한 경우도 많았습니다.
예를 들어 GS양구정림점은 실제로 편의점이지만 잡화점으로, 카페뮤토는 실제로는 카페지만 술집으로, 비치타운리조텔은 실제로는 리조트이지만 부동산중개로, 우리생협메트로시티점은 실제로는 마트지만 건강식품으로 잘못 등록된 것을 확인했습니다. 모델은 제대로 예측했지만 정답이 잘못되어서 틀린 케이스라고 할 수 있겠습니다.
3) 업체명에 다른 업종 키워드가 포함된 경우

다음 예시는 업체명에 다른 업종의 키워드가 들어있는 경우입니다. 업체의 이름과 업종이 일치하지 않지만, 모델은 이 키워드를 보고 잘못 예측한 것으로 보입니다.
시각화
모델링한 결과를 토대로 마이데이터 데모 웹사이트를 만들어보았습니다. Streamlit 라이브러리를 활용해서 시각화하고, FastAPI로 서버에 연결했습니다.
1) 간단 시연

간단 시연 페이지에서는 저희가 학습한 모델 중 하나를 선택해서 직접 결과를 확인할 수 있습니다. 모델은 19개의 클래스 중 가장 높은 소프트맥스 값을 갖는 클래스를 예측 결과로 반환합니다. 저희는 시연 페이지에서 예측 결과는 물론 모델이 예측한 top 5개의 클래스에 대한 예측 확률까지 확인할 수 있도록 해두었습니다.
2) 가계부
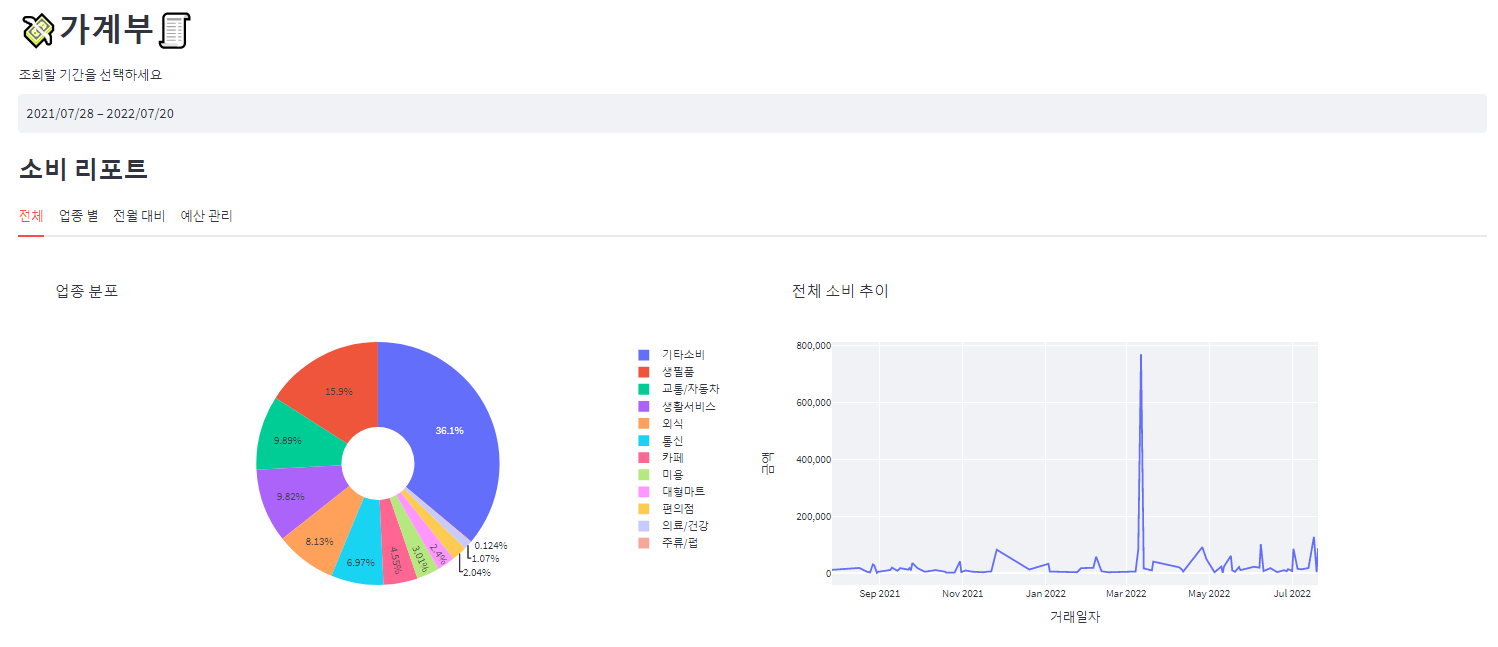
가계부 페이지에서는 마이데이터 서비스의 데모 버전을 구현하였습니다.
업종 예측에 사용할 모델을 설정하고 카드 사용내역 csv 파일을 업로드한 뒤 조회할 기간을 선택합니다. 전체 탭에서는 설정한 기간 동안 소비한 업종의 분포와 추이를 파이차트와 시계열 차트로 확인할 수 있습니다.
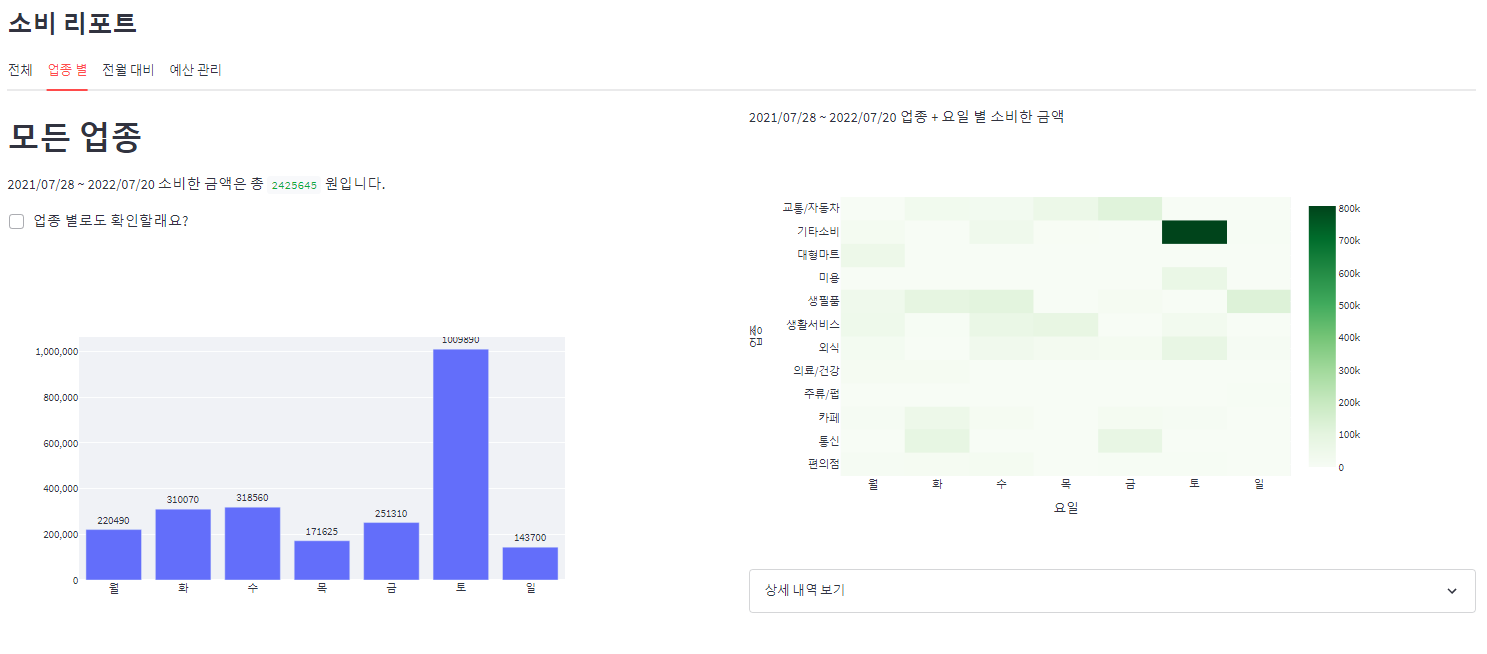
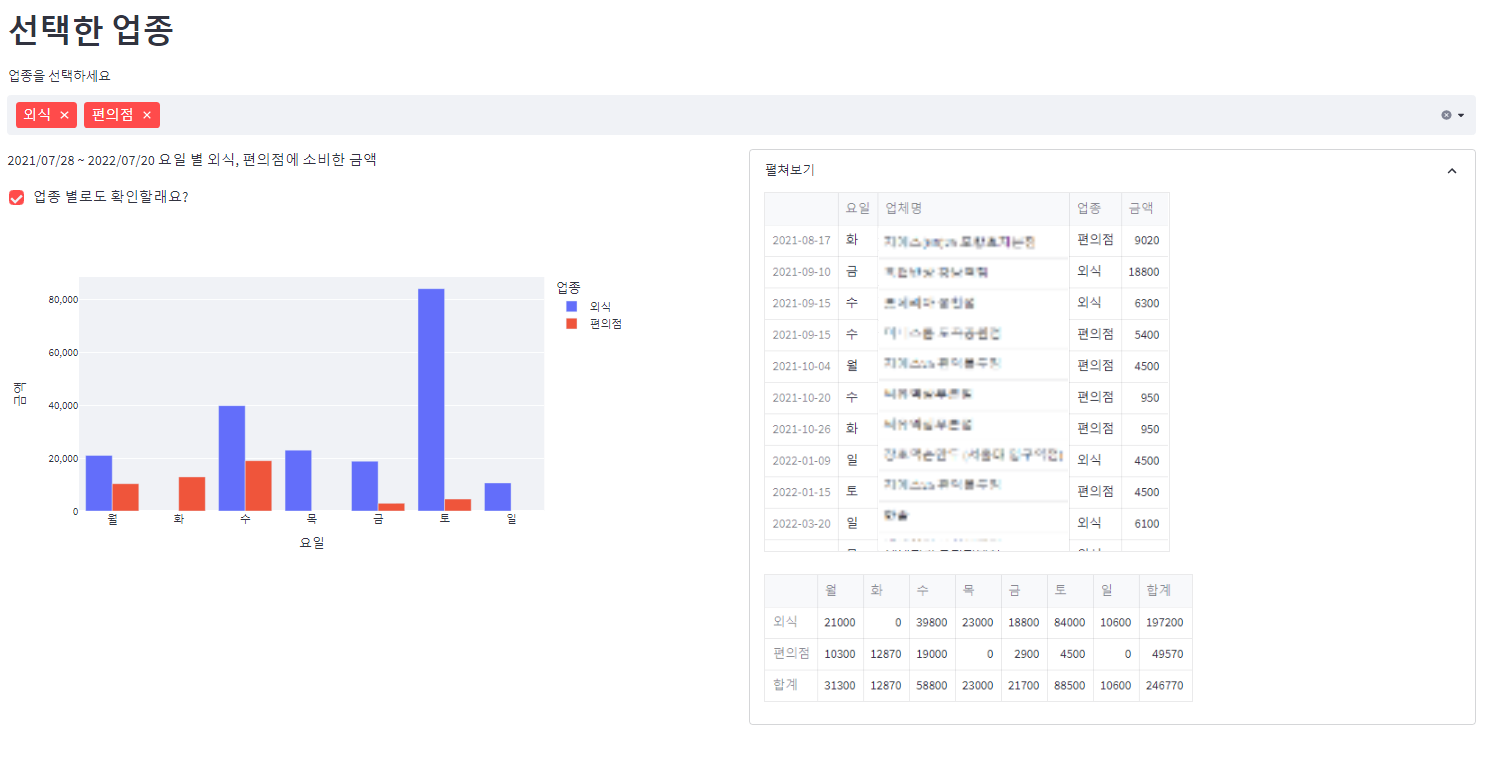
업종별 탭에서는 모든 업종에 대해서, 그리고 선택한 업종에 대해서 요일 별 소비 그래프와 내역을 확인할 수 있습니다.
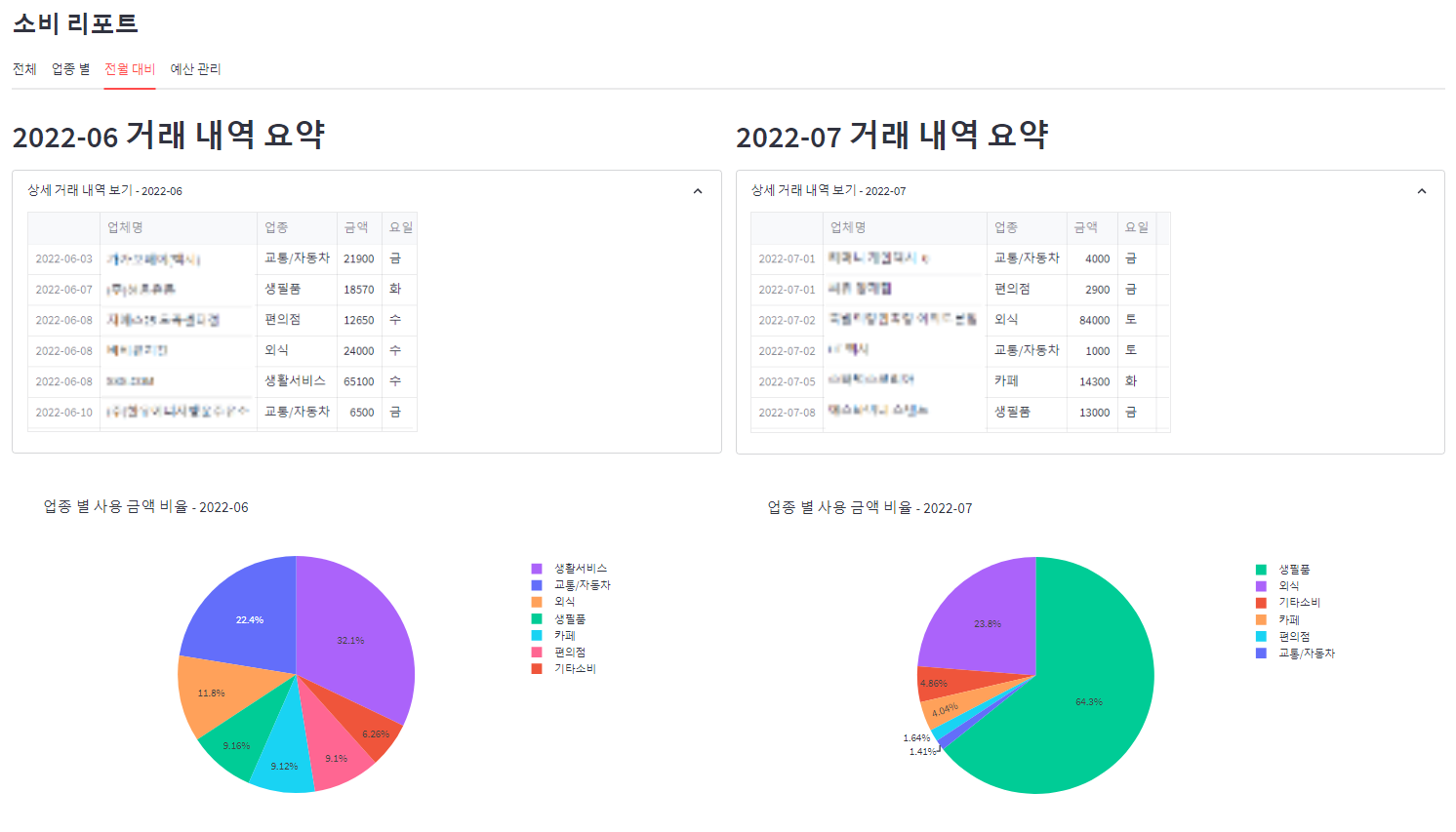
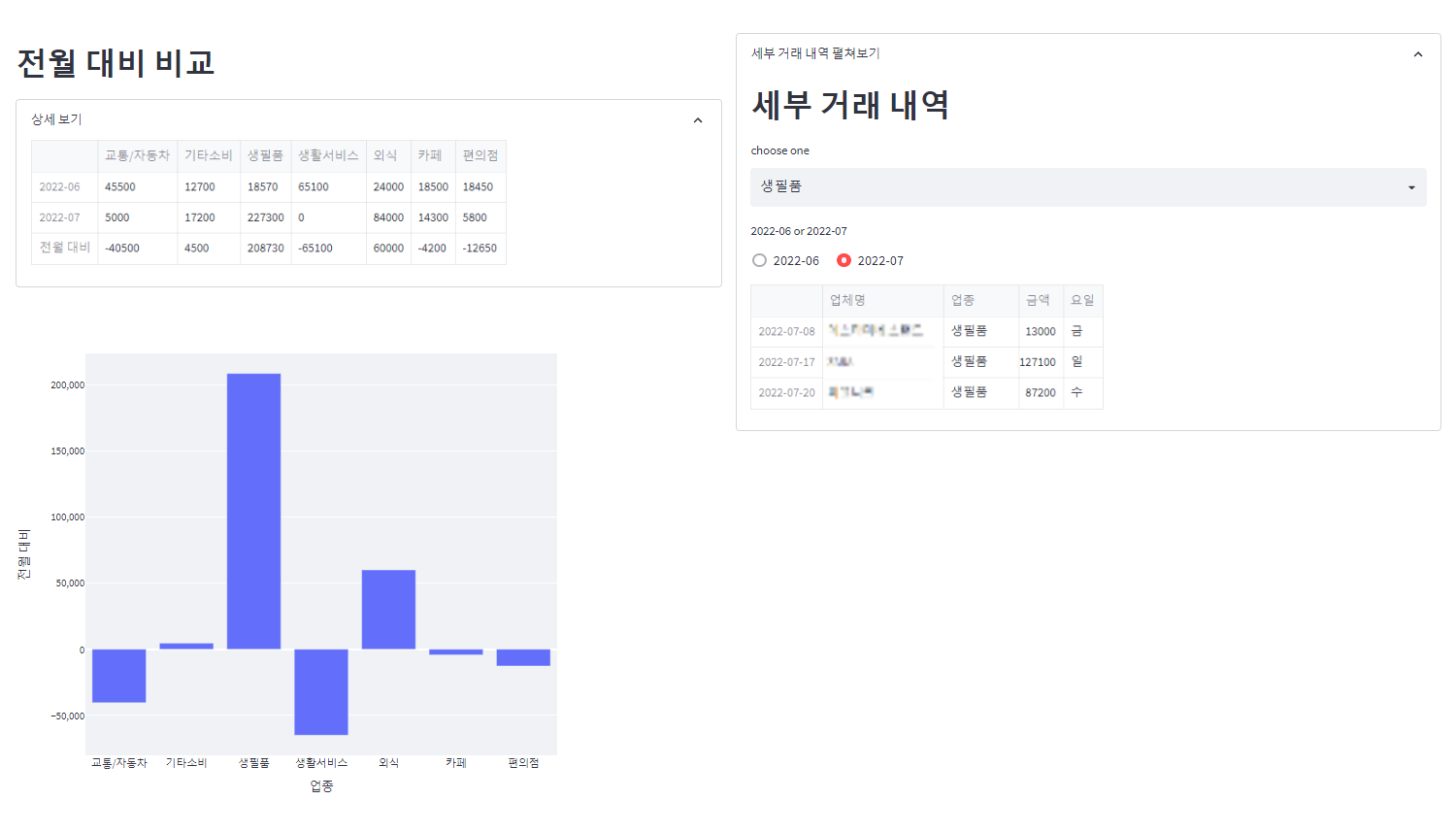
마지막으로 전월 대비 탭에서는 전월과 현월의 업종별 소비 분포, 그리고 비교 그래프를 확인할 수 있습니다. 위에서 설정한 기간이 2개월 이상일 경우 말일을 기준으로 전월과 현월을 선정했습니다. 예를 들어 설정한 기간이 2022-05-01~2022-07-20일 경우 2022-07-20을 기준으로 현월을 2022-07, 전월을 2022-06으로 간주하여 분석했습니다.
참고
[마이데이터 100일]上 금융권 뒤흔들었다
지난 1월 5일부터 본격 도입돼 국내 금융산업을 뒤흔들 것이라 예상됐던 마이데이터(본인신용정보관리업)산업이 14일 본시행 100일을 맞이한다. 실제로 마이데이터 산업 도입 이후 많은 변화가
news.bizwatch.co.kr
보도자료 - 위원회 소식 - 알림마당 - 금융위원회
□ ’21.12.1일부터 API 방식의 금융 마이데이터 시범서비스 실시 ㅇ 동 시범서비스 기간 동안 시스템 안정화, 데이터 정합성 제고, 사설인증 및 정보제공기관 확대 등 개선필요사항은 신속하게 보
www.fsc.go.kr
Micro, Macro & Weighted Averages of F1 Score, Clearly Explained
Micro, Macro & Weighted Averages of F1 Score, Clearly Explained
Understanding the concepts behind the micro average, macro average and weighted average of F1 score in multi-class classification
towardsdatascience.com
https://github.com/MyeongheonChoi/merchandise_clf
GitHub - MyeongheonChoi/merchandise_clf: Merchandise Classifier using KoBERT, KoELECTRA, RoBERTa, Character CNN (NLP)
Merchandise Classifier using KoBERT, KoELECTRA, RoBERTa, Character CNN (NLP) - GitHub - MyeongheonChoi/merchandise_clf: Merchandise Classifier using KoBERT, KoELECTRA, RoBERTa, Character CNN (NLP)
github.com
금융 마이데이터 도입 현황과 시사점, 노현주, 보험연구원
인턴십이 처음이었는데 프로젝트를 끝까지 잘 완료하며 모델 구현을 넘어서 웹사이트까지 만들 수 있는 좋은 배움의 기회를 통해 소중한 경험을 얻을 수 있었고, 조금 더 성장할 수 있었습니다. 데이터 사이언스 실무에 대해 많이 배울 수 있는 좋은 경험이었습니다. 그리고 많이 도와주시고 챙겨주신 파트너님, 매니저님들께 너무 감사합니다.
마인즈앤컴퍼니 화이팅!
'AI to the Real World' 카테고리의 다른 글
| TrOCR을 활용한 Text Recognition 모델 개발기 (0) | 2022.12.16 |
|---|---|
| SNU 빅데이터 핀테크 캡스톤 프로젝트 후기 (0) | 2022.08.22 |
| 추천시스템 모델 개발과 현업 프로젝트 적용 (0) | 2022.07.28 |