안녕하세요, 저희는 현장실습 프로그램으로 마인즈앤컴퍼니에서 근무하고 있는 정지현(홍익대 컴퓨터공학 19), 정기윤(한양대 산업공학 17) 인턴입니다! 이번 글에서는 저희가 6주간 참여한 프로젝트를 소개해드리려고 합니다.
1. OCR 이란?
OCR (Optical Character Recognition) 이란 손글씨, 인쇄된 글자, 스캔한 문서, 문서의 사진 등의 형태의 텍스트 이미지를 기계가 읽을 수 있을 수 있는 텍스트 포맷으로 변환하는 기술입니다. 문자를 디지털화 해주기 때문에 일상생활에서도 많이 쓰이고 있는데요, 스마트폰으로 카드결제를 진행할 때, 카메라로 카드를 인식하면 자동으로 카드 번호가 입력되는 경우도 해당됩니다.
OCR TASK 단계는 크게 5단계(Preprocessing, Text Detection, Text Recognition, Post processing, Document Understanding)로 나눌 수 있는데, 본 프로젝트에서는 글자의 위치는 선추출 되었다고 가정하여 Text Localization 과정은 진행하지 않았습니다.
전처리(Preprocessing)
컴퓨터는 사람처럼 직관적으로 문자를 구분하지 못하고, 이미지에서 색깔 분석을 통해 비슷한 밝기를 가진 픽셀들을 덩어리처럼 인식하기 때문에 색깔 차이를 분명하게 해주어 인식률을 높여야 효과적인 문자 인식이 가능합니다. 거리 이미지, 영상 속 글자 인식 같은 경우에는 상태가 매우 다양하므로 문서 이미지 보다 복잡한 방법의 이미지 전처리 방법이 필요합니다.

글자 검출(Text Detection, Text Localization)
전체 이미지에서 글자 영역을 골라내서 raw data를 딥러닝 모델이 학습할 수 있는 형태로 만듭니다. 전통적인 text detection는 여기까지만 해주었다면, 최근에는 텍스트 영역과 그 영역의 회전 각도를 구하고 텍스트를 수평 상태로 만들어 주는 과정까지 text detection에 포함됩니다.
글자 인식(Text Recognition)
모델이 특징 추출을 통해 글자를 구분하는 여러 특징들(선, 닫힌 고리, 선 방향 및 선 교차 등)을 학습하여 입력받은 이미지의 글자가 어떤 글자인지 알아냅니다.

후처리(Postprocessing)
마지막으로 후처리 단계는 출력된 텍스트에 포함된 부자연스러운 단어나 문자를 고쳐서 정확도를 향상합니다. 예를 들어 ‘m2’ 라는 문자는 m² 를 잘못 예측한 것임을 알 수 있으므로 수정해줍니다.
2. 학습 데이터 설명
AiHub 공공행정문서 ocr 데이터를 활용하였습니다. 900,000장의 문서 이미지에 포함된 25,000,000 단어 로 구성되어 있는데 이 중 30% 정도를 사용하였습니다.
데이터셋 구성
Label은 images, annotations 2개의 key로 구성되어 있으며, images 에는 행성문서 카테고리, 제작 년도 등의 사진의 기본정보가 담겨있고 annotations에는 문서 내 모든 단어의 bounding box와 해당 text가 담겨있습니다.

전처리
1. crop
label에 있는 annotations의 bounding box를 사용하여 crop하였습니다.

2. Crop된 bounding box 전처리
single special character의 너비와 높이 분포에서 평균-2표준편차 보다 작은 값들은 제거해주었는데, 너비와 높이 각각 8 pixel, 12 pixel 보다 작은 경우가 이에 해당됩니다.


또한 bbox 종횡비, 문자길이 대비 bbox 종횡비등을 기준으로 봤을 때 여러 줄로 이루어져 있거나 글자가 세로로 된 경우가 있어서 역시 모델 학습에는 제외하였습니다.


가로비율이 지나치게 높은 데이터, 저희가 임의로 정한 최소 크기보다 작은 데이터 등등을 삭제하여 cropped bounding box 기준으로 11,843,312 개의 유효한 학습 데이터를 얻을 수 있었습니다.
3. 모델 소개
TrOCR (Transformer-based Optical Character Recognition)
기존 모델의 복잡한 전, 후처리 과정을 개선한 Transformer 기반의 end-to-end text recognition 모델입니다. 기존의 text recognition task 에서는 CNN을 backbone 으로 사용하였으나, TrOCR에에서는 입력 이미지를 정해진 크기(patch)로 나눈 후 patch sequence를 만들어서 transformer에 적용해줍니다.
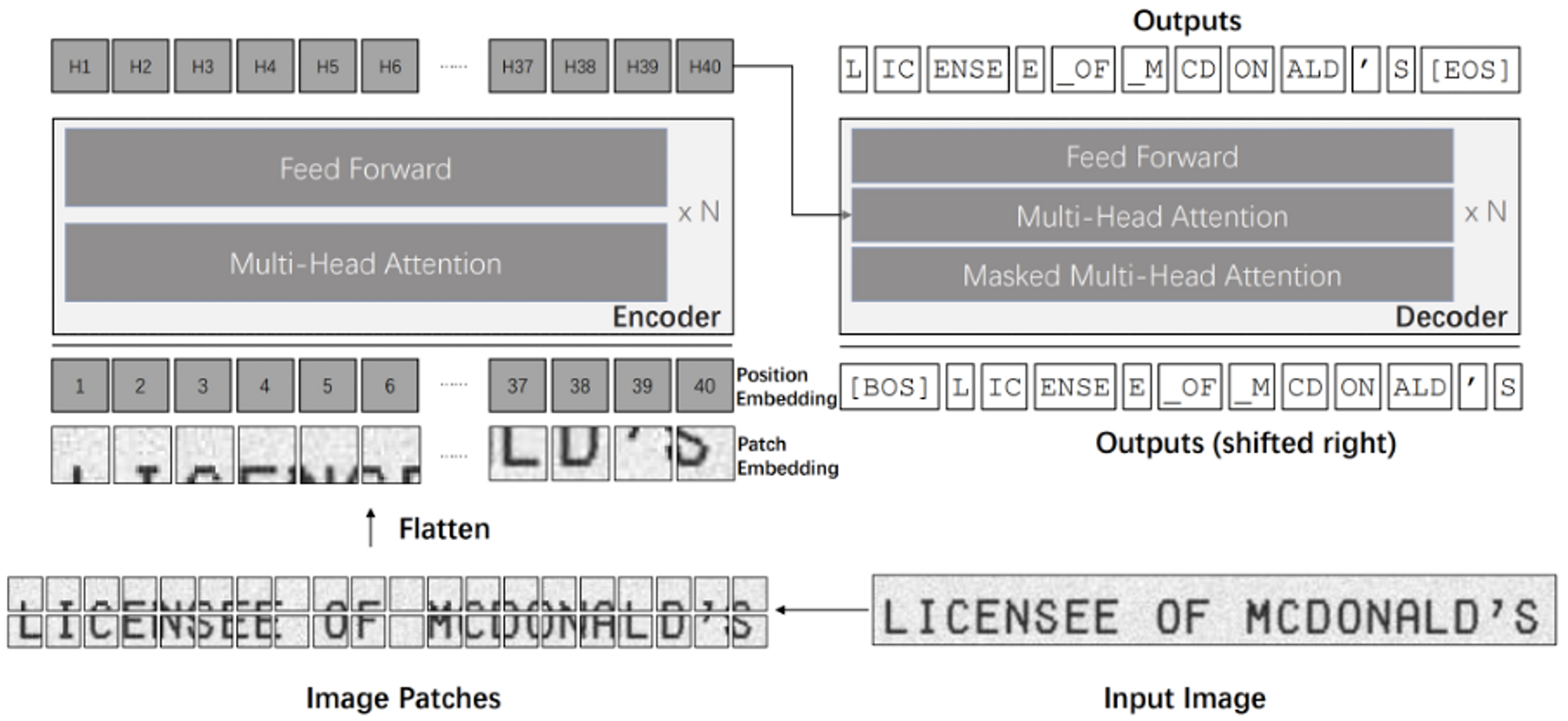
이미지, 텍스트 데이터에 대해 사전학습된 모델을 사용하여 성능을 향상하여 인쇄되거나 사람이 쓴 글씨, 길가의 간판 등의 일상 속 텍스트 이미지에 대해서도 복잡한 후처리 과정 없이 SOTA 수준의 정확도를 달성하였습니다.
VisionEncoderDecoder
HuggingFace의 TrOCR을 구현한 VisionEncoderDecoder을 사용하였습니다. TrOCR은 글자 인식에 사용되는 글자의 특징을 추출하는 encoder와 encoder의 ouput을 바탕으로 어떤 단어인지 예측하는 decoder로 구성되어있ㄴ는데요, encoder와 decoder는 각각 google 에서 ImageNet을 이용하여 사전학습한 ViT 모델, 한국어로 사전학습한 Bert 모델을 사용하였습니다.
4. 실험 설명
데이터
AI Hub 데이터는 Training/Validation 으로 구분되어 있는데요, Validation 폴더를 1:1 비율로 valid와 test데이터셋으로 나누어서 valid 로는 ealy stopping 및 best model 선정에 사용하였고, test 데이터로는 회종 성능 검출에만 사용하였습니다. 각각 데이터 셋의 비율은 train: valid: test = 18 : 1 : 1 입니다.
학습 데이터가 용량이 너무 커서 프로젝트 초반에는 train, test 데이터의 10%만 실험에 사용하였습니다.
평가지표
평가지표는 CER(Character Error Rate)을 사용하였습니다.
CER은 자동 음성 인식(ASR) 및 광학 문자 인식(OCR)에서 모델 정확도를 비교하는 데 쓰이며, 특히 WER(단어 오류율)이 적합하지 않은 다국어 데이터 셋에 대해 유용합니다. Ground Truth와 Hypothesis 간의 최소 편집 거리를 계산하는데, Dynamic Programming 기법 중 Levenshtein을 사용하여 계산합니다.
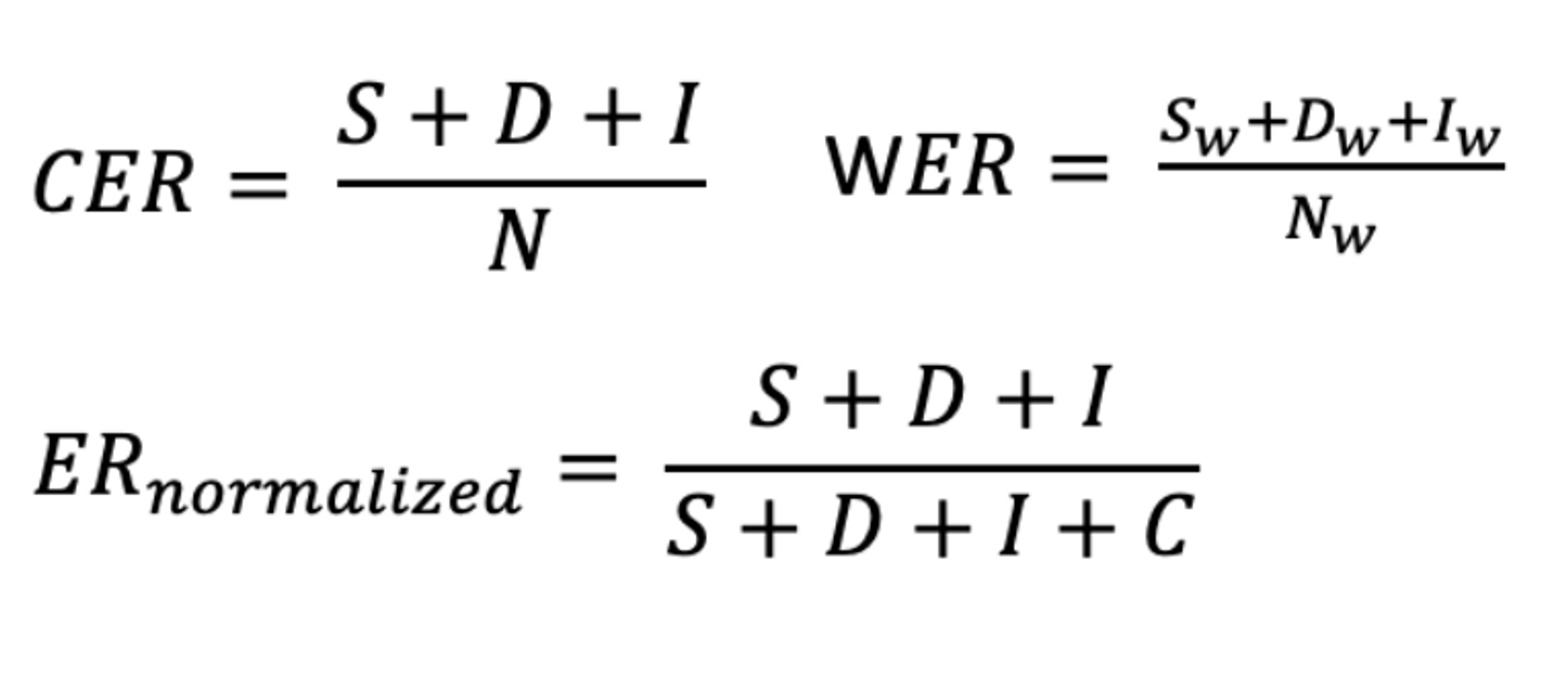
참고) WER은 CER과 비슷하지만 음절 대신 단어에 대해 오류를 확인합니다.
수식 설명
- S : 잘못 대체된 음절 수
- D : 잘못 삭제된 음절 수
- I : 잘못 추가된 음절 수
- C : Ground Truth 와 Hypothesis 간 올바른 음절의 합계( C = N – D – S)
- N: 정답 텍스트(Ground Truth)의 음절 수

CER 값은 잘못 추가된 글자 수가 많은 경우 1보다 커질 수 있기 때문에 항상 0과 1사이의 숫자는 아니며 0 에 가까울 수록 모델의 정확도가 높다는 것을 의미합니다. 원본 ER을 계산하는 대신 오류 음절 수를 편집 작업 수인 (I + S + D)와 C(정확한 문자 수)의 합으로 나눠주면 정규화된 0–100% 범위에 속하는 값을 얻을 수 있습니다.
실험 구성
train 데이터 10%에 대해 전처리만 진행했을 때 사전학습 모델의 초기 정확도는 CER 7.5%가 나왔습니다. CER 이 높은 경우 이미지를 보면서 잘못 예측된 이유를 분석하여 모델 파라미터와 전처리 방법을 바꿔가며 실험해보았습니다.
1. 문자 종류 별 성능비교 - 타입 , 데이터 개수문자 종류 CER
| 문자 종류 | CER |
| 한글 | 2.65% |
| 영어 | 18.32% |
| 숫자 | 4.71% |
| 특자 | 94.0% |
먼저, 글자 종류 별로 정확도를 확인하고 틀리게 예측한 원인을 분석해보았는데요, 특수문자의 CER이 특히 높아서 제대로 예측하지 못하는 경우를 더 자세히 보았습니다.

test 데이터 중 특수문자만 12800개를 랜덤 샘플링하여 분석해보았습니다. 이 중 정답이 11588개(90.5%) , 오답: 1242 (9.5%)였고 오답 중 1/3이 : , / , - , ( , ) , $\centerdot$ 인 것을 확인할 수 있었습니다.
| true | pred | count (전체 비율) |
| : | 총계 | 235 (18.92%) |
| : | 227 | |
| . | 6 | |
| / | 총계 | 60 (4.83%) |
| 1 | 60 | |
| - | 총계 | 47 (3.78%) |
| - | 19 | |
| -_ | 14 | |
| - - | 8 | |
| _ _ | 5 | |
| ( | 총계 | 23 (1.89%) |
| 1 | 23 | |
| ) | 총계 | 19 (1.56) |
| 1 | 19 |
2. 토큰 분석
decoder(kykim/bert-kor-base)에서 사용하는 토크나이저의 vocab 을 분석해보았습니다.
40000개의 pretrained token + 2000 개의 unused token 으로 구성되어 있어서 unused token을 이용하여 최대 2000개의 custom token을 추가할 수 있습니다.
자주 틀리는 단어에 대해 tokenize가 되는지 확인을 해보았는데 한 단어 내에 vocab에 없는 글자가 포함되어 있으면 단어 전체가 [UNK] 처리 되는 것을 알 수 있었습니다.
그래서 학습 데이터에 자주 등장하는 특수문자는 unused token을 이용하여 추가해주었고, vocab에 없는 특수문자 앞 뒤로 띄어쓰기를 넣어서 vocab에 없는 글자에 대해서만 [UNK] 처리될 수 있도록 하였습니다.
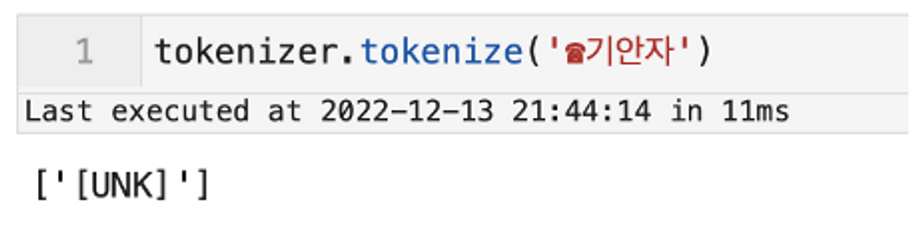

3. 유사 문자 변환
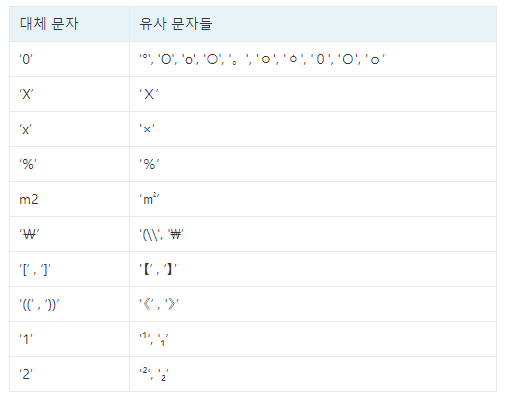
유사 문자 때문에 모델이 잘못 예측한 경우가 다수 있어서 데이터 자체에서 유사 문자를 변환해주었습니다. 다음은 유사문자가 많이 존재했던 예시로 ‘o’와 비슷한 기호들 입니다. 육안으로는 구분하기 힘들어서 유니코드 값을 같이 확인해야 했습니다.
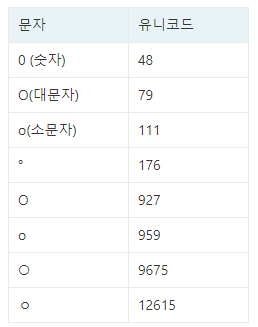
이 외에도 상당히 많은 동그란 모양의 특수문자들이 있었는데요, 영어 대문자와 소문자 제외하고는 모두 숫자 0으로 대체하였습니다.
해당 경우를 제외하고도 제곱과 숫자 2, 대소문자X 와 곱하기 등 여러 경우가 있어서 다음과 같은 방법으로 유사 문자를 처리해주었습니다.
4. 글자 길이 별 성능비교
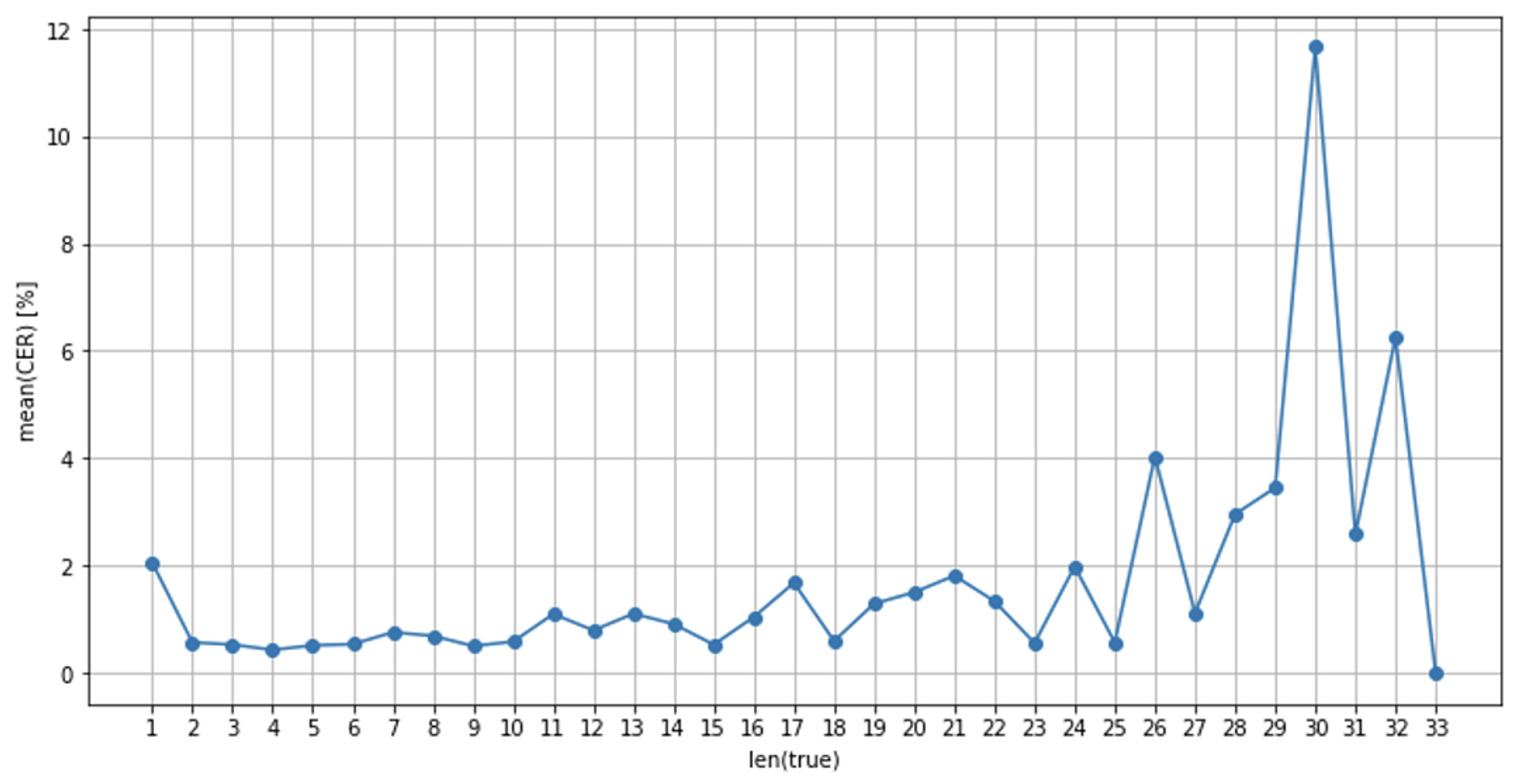
글자 수 10 까지는 준수한 성능을 보이다가 10 이후로 하락하는 추세를 보였습니다.
TrOCR에 예측 문자 길이의 제곱비로 패널티를 주는 파라미터(length_penalty)가 존재해서 0.66, 1.0, 1.33, 2.0 으로 테스트 해 본 결과 1일 때 성능이 가장 좋아서 1로 설정하였습니다.
5. 실험 결과
학습 결과 분석
모델 configuration
- early_stopping = True
- no_repeat_ngram_size = 3
- length_penalty = 1.
- num_beams = 1
- max_length = 32
| 타입 | 개수 | 오답율 | CER | 초기 모델 CER |
| 전체 | 655,530 | 1.8% | 1.75% | |
| 한글 | 447,438(68%) | 1.1% | 0.5% | 2.65% |
| 영어 | 2,071(0.3%) | 7.2% | 6.1% | 18.32% |
| 숫자 | 20.163 | 5.2% | 4.4% | 4.71% |
| 특수문자 | 28.683 | 4.0% | 4.1% | 94.0% |
| 혼합 | 157,175 | 2.6% | 0.7% |
유사문자 처리, 토큰 추가, 잘못된 라벨링 수정을 통해 초기 모델의 CER을 다음과 같이 향상시켰습니다. 전체적으로 정확도가 올라갔지만 특히 특수문자, 영어에서 유의미한 차이를 보였습니다.
| num_beams | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| CER[%] | 1.75 | 1.92 | 1.96 | 1.92 | 1.89 | 1.97 | 1.92 | 1.85 | 1.80 | 1.78 |
| times[ms] | 8.8 | 12.8 | 15.2 | 17.7 | 20.2 | 22.9 | 24.9 | 27.3 | 29.8 | 32.6 |
또한 num_beams 를 바꿔가면서 실험해본 결과 num_beams =1 에서 가장 좋은 성능을 보였습니다.
모델 configuration 에서 num_beams = 1 이라는 건 beam search가 아니라 greedy search 한다는 것을 의미합니다.
간단하게 말하면 greedy search decoder 에서는 해당 시점에서 가장 확률이 높은 후보를 선택합니다.
그렇기 때문에 특정 시점 t 에서의 확률분포 상에서 상위 1등과 2등의 확률 차이가 작더라도 2등이 정답을 경우는 고려하지 않는데요, 이러한 단점을 보완한 방법이 beam search decoder 입니다.
beam search 는 각 시점에서 탐색의 영역을 상위 k개의 토큰으로 유지하며 다음 단계를 탐색합니다. 그래서 greedy search 보다 더 넓은 영역을 탐색하기 때문에 더 좋은 타겟 시퀀스를 생성하게 됩니다. 이 때, 상위 몇 개의 토큰에서 탐색할지, 즉 k를 결정하는 파라미터가 바로 num_beams 입니다.
그래서 beam search의 정확도가 더 높을 것이라고 예상했지만 직접 테스트 해본 결과 greedy search에서 더 좋은 성능을 보였습니다.
6. 모델 성능 개선 방안
- 전처리 방법 수정
실험 결과 여백에 의한 영향은 크지 않고 글자가 선명할수록 모델이 잘 예측하였습니다. 따라서 배경에 비해 글자가 선명하게 보이도록 전처리를 한다면 모델의 정확도가 올라갈 것으로 기대됩니다.
또한 현재 채택한 전처리 방법은 AI hub 데이터에 특화된 방법으로, 추가 데이터셋에 맞게 현재 적용중인 전처리 방법의 재검토가 필요합니다.

- Data Augmentation 적용
학습 데이터의 영어 및 특수문자의 수가 한글에 비해 부족하기 때문에 데이터 증강을 통해 영어 데이터의 수를 늘린다면 영어의 정확도가 개선될 것입니다. - feature extractor / encoder
현재는 feature extractor 에서 input image에 resize , normalize만 적용되는데 OCR에 맞는 적용 기법을 검토하고 encoder 입력 크기 224 x 224 에서 가로 크기를 늘려 재학습해보는 것이 필요합니다.
4개월 동안 OCR 뿐만 아니라 image segmentation, survival analysis 등 다양한 분야를 접해볼 수 있었고 AI가 실무에서 어떻게 사용되는지 알게 되었습니다. 인턴쉽이 처음이라 많이 서툴렀는데 파트너님과 매니저님들께서 도와주시고 챙겨주신 덕분에 많이 성장할 수 있었습니다. 감사합니다!
참고
https://m.blog.naver.com/with_msip/221846680863
https://aws.amazon.com/ko/what-is/ocr/
https://github.com/hyeonsangjeon/computing-Korean-STT-error-rates
'AI to the Real World' 카테고리의 다른 글
| 마이데이터 활용을 위한 업종 분류 모델 개발기 (0) | 2022.09.07 |
|---|---|
| SNU 빅데이터 핀테크 캡스톤 프로젝트 후기 (0) | 2022.08.22 |
| 추천시스템 모델 개발과 현업 프로젝트 적용 (0) | 2022.07.28 |