지난글에서는 대표적인 Unsupervised learning 모델의 하나인 clustering의 개요, 유형에 대해 알아봤습니다.
이번 글에서는 clustering의 대표적인 모델인 K-means clustering / Mean-shift clustering / DBSCAN (Density-based spatial clustering of applications with noise) / EM clustering using Gaussian mixture 에 대해서 좀 더 자세히 알아보고자 합니다.
1. K-means clustering
K-means clustering은 대표적인 분할 군집 기법입니다. 군집 별로 centroid (중심)을 가지고 있으며, centroid에 가까운 data들 끼리 묶어 군집화하는 기법입니다. "K-means"에서 "K"는 연구자가 직접 설정한 군집, 즉 centroid의 숫자를 의미합니다. K-means clustering은 clustering 모델 중 가장 많이 알려진, 상대적으로 이해하기 쉽고 구현하기 쉬운 알고리즘 입니다.
K-means clustering 모델이 구현되는 단계를 설명하자면,
1. 클래스 혹은 그룹의 수(K)를 정합니다. 그러면 정해진 "K" 숫자에 따라 랜덤하게 centroid 를 잡습니다.
2. 각 data들은 centroid 까지의 거리를 측정하여 각 centroid 의 군집으로 분류 합니다.
3. 분류된 data points를 기반으로 그룹 내 벡터의 평균(mean)을 구하고, centroid를 재설정합니다.
4. 1-3 단계를 clustering의 assign이 바뀌지 않을 때 까지 반복합니다.
아래 그림은 1~2단계를 진행한 예시입니다. 초기 centroid는 3개로 잡은 모습이며, 각 centroid에 가까운 data들을 묶어서 군집화한 모습입니다.
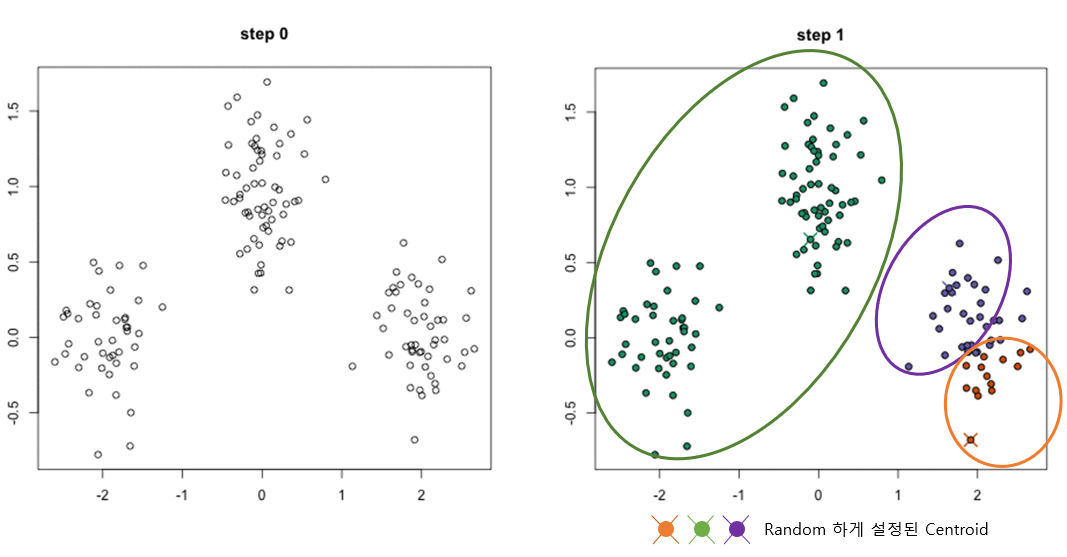
3단계를 진행하면 아래 그림과 같이 centroid를 그룹내의 평균값으로 이동시키며, 이동된 centroid 기반으로 군집을 재분류 합니다.
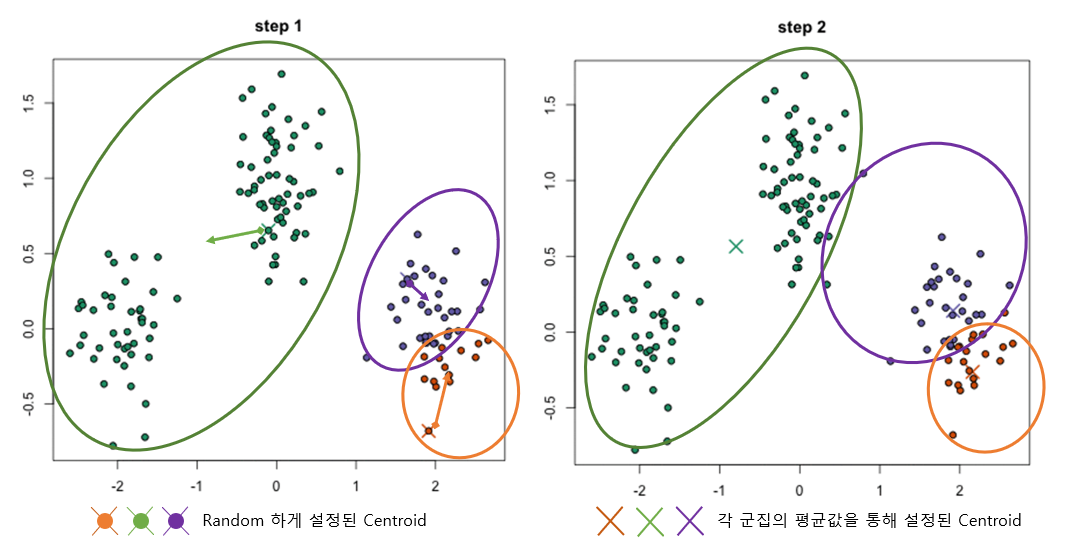
반복적으로 진행하게 되면 단계적으로 centroid가 이동하게되며, clustering의 assign이 바뀌지 않을 때 까지 반복하면 아래그림과 같은 형태로 군집이 형성됩니다.
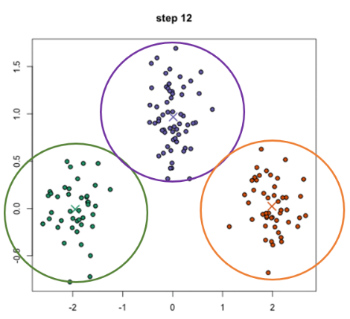
단계를 연속적으로 진행하면 아래 그림과 같은 모습입니다.
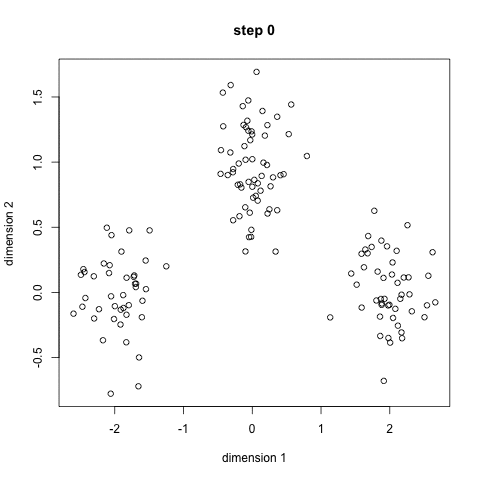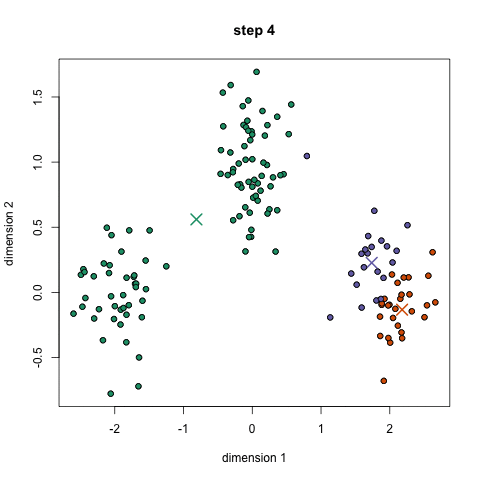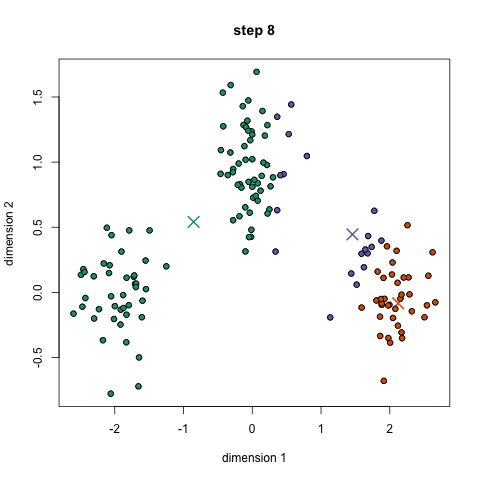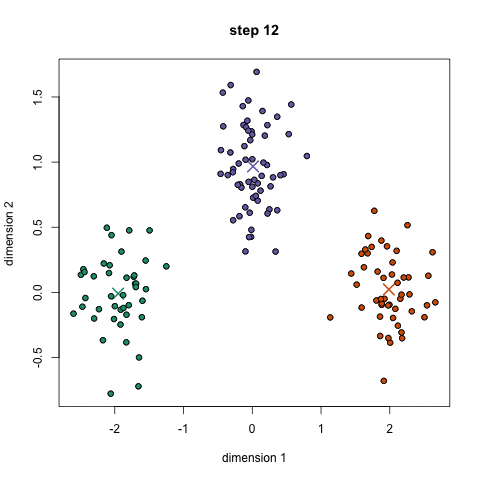
위의 예시는 초기에 설정한 군집의 숫자 "K" 값, 3이 실제 data의 군집 유형과 어느정도 맞아서 합리적인 수준의 clustering 결과를 얻을 수 있었습니다. 하지만 반대로 초기에 설정한 "K" 값에 따라 clustering 결과는 전혀 다른 형태를 보이게 되며, 이는 K-means clustering의 한계점이기도 합니다.
K-means clustering의 장점은,
1. 시간 복잡도가 O(n)으로 빠른 편입니다.
2. 구현하기가 비교적 간단합니다.
단점은,
1. 초기에 cluster의 숫자인 "K" 값을 설정해주어야 합니다.
2. 선택된 K값, 초기 랜덤하게 설정된 centroid의 위치가 clustering 결과에 큰 영향을 끼칩니다.
3. Outlier data의 분석에 취약합니다.
이러한 K-means clustering의 한계를 보완하기 위한 다양한 형태의 clustering 모델이 활용되고 있습니다.
2. Mean-shift clustering
Mean-shift는 어떠한 data의 분포가 있을 때 무게중심을 찾아서, 이동하는 형태로 clustering을 하게 됩니다. 특정 data의 주변에서 data가 가장 밀집된 형태로 이동하게 되며, 단계적으로 data 분포의 중심으로 이동하면서 군집을 이루는 모델입니다.
지난번 경사하강법에서 설명한 비슷한 예를 들어서 설명할 수 있습니다. 안개가 자욱하여 시야가 아주 좁은 상태에서 산의 정상을 찾아가는 방법을 생각해봅시다. 시야가 확보되지 않은 상태이기 때문에 정상을 볼 수는 없지만, 본인의 시야 내에서 가장 높은 곳으로 한걸음 이동하게 될 것이고, 이동한 위치에서의 다시 또 시야 내에서 가장 높은 곳으로 계속적으로 이동하게 될 것입니다.
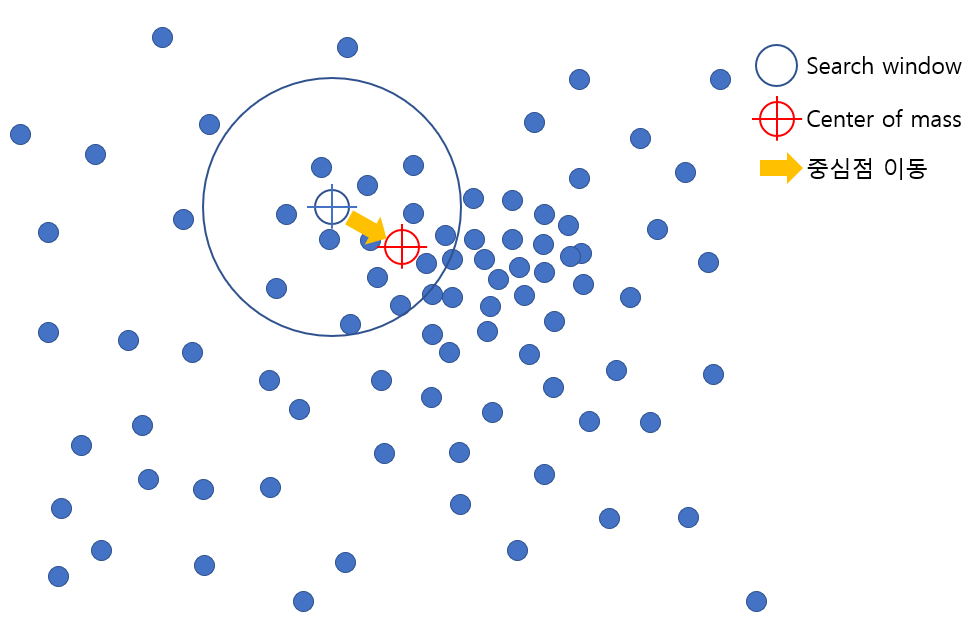
이와 같이 Mean-shift clustering 이란 sliding window의 반경 (정해진 시야) 내에서, data의 분포가 높은 곳으로 (산에서 높이가 높은 곳)으로 단계적으로 이동하여 군집을 완성하는 clustering 기법입니다.
1. Sliding window의 size (kernel = 반지름(radius) r) 를 정의하고, cluster의 centroid가 되는 data point를 랜덤하게 설정합니다.
2. 정해진 크기의 window안에서, data의 분포가 높은 방향으로 center of data point를 이동시키며, cluster의 centroid도 함께 이동합니다.
3. Sliding window가 중첩될 경우, data point가 많은 window를 유지합니다.
4. Cluster의 이동 / 변화가 멈출 때까지 해당 작업을 반복합니다.
Mean-shift clustering이 단계적으로 구현되는 형태를 더 자세히 알아보도록 하겠습니다.
아래 그림과 같이 정해진 반지름 r을 가지는 sliding window안에서 높은 data의 밀도가 보이는 쪽으로 중심을 이동합니다.
아래 그림은 이동을 지속적으로 반복하여, 이동이 일어나지 않는 형태입니다.
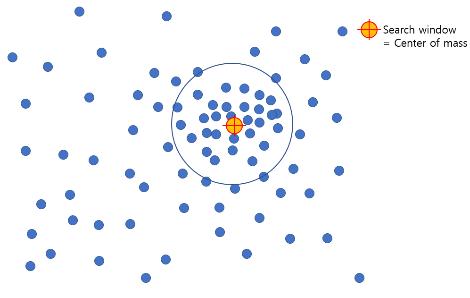
여러개의 sliding window 안에 모든 point들이 포함될 때 까지 해당 작업을 반복하면, 아래 그림과 같이 군집을 형성하게 됩니다.
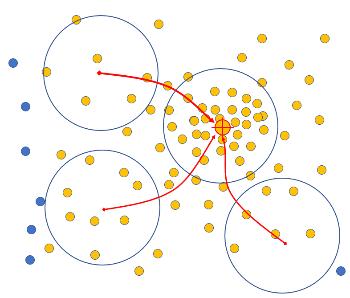
Sliding window가 연속적으로 이동하는 모습을 아래 그림과 같습니다. #point가 점점 많아지는 방향으로 이동하게 됩니다.
아래 그림은 모든 data에 대해서 작업을 반복하여 중심점이 모이는 point를 기반으로 4개의 군집을 형성한 모습입니다.

Mean shift clustering의 장점은,
1. K-means와 달리 초기 "K" 값을 설정할 필요가 없습니다.
단점은,
1. Sliding window의 kernel = 반지름 r 사이즈를 선택해야 합니다.
Mean-shift clustering model도 특이한 형태를 지니는 data를 clustering 하기에는 한계가 있습니다. 이러한 단점을 보완할 수 있는 모델이 DBSCAN (Density-based spatial clustering of applications with noise) 입니다.
3. DBSCAN (Density-based spatial clustering of applications with noise)
DBSCAN은 data의 분포가 세밀하게 몰려 있어서 밀도가 높은 부분을 중심으로 클러스터링을 하는 방식입니다. 간단히 설명하면 어떠한 점을 기준으로 반경 ε 내에 점이 n개 이상 있으면 하나의 군집으로 인식합니다.
DBSCAN의 모델의 구현단계는,
1. Data를 군집하기 위한 반경 (epsilon = ε)을 정의합니다.
2. 반경 내에서 cluster와 outlier를 구분하기 위한 minpoints를 정의합니다.
3. 랜덤하게 정의된 point의 반경 (ε) 내에 minpoints 이상의 data가 존재하는지를 확인합니다.
4. 만약 point의 반경 (ε) 내에 minpoints 이상의 data가 존재할 경우, 이웃 data를 군집 내에 포함시키고, 군집 내 속한 다른 point에 대해서도 작업을 반복합니다.
5. 모든 data point에 작업을 반복하여, cluster data와 noise point를 구분합니다.
일정 반경 epsilon (ε) = 100, minpoints = 4 인 경우를 예를들어 설명하면,
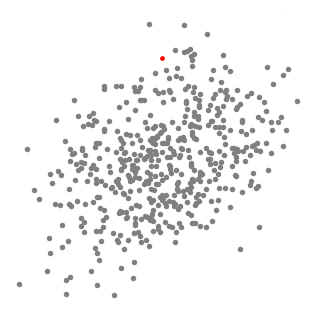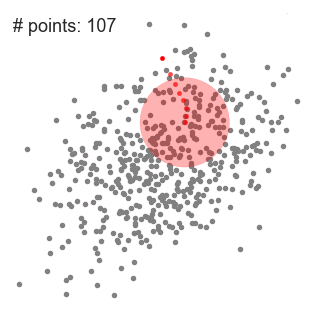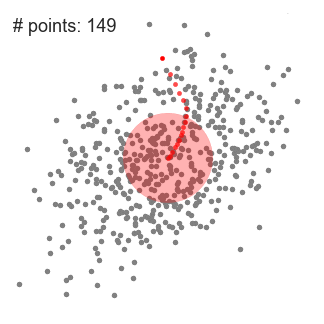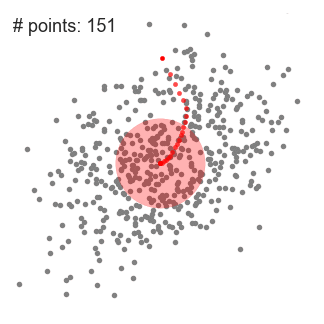
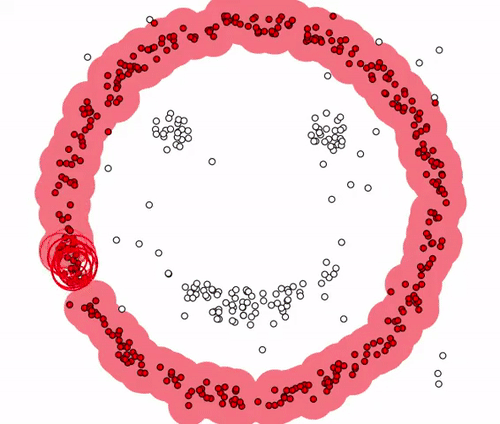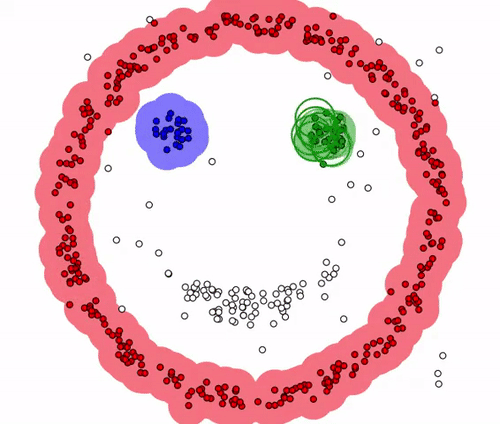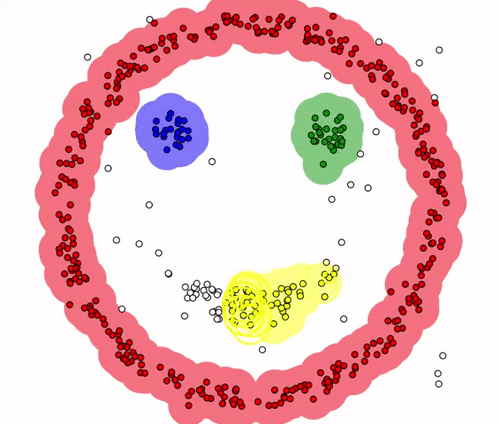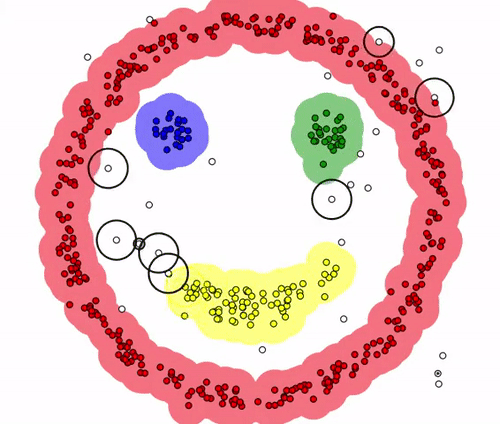
아래 그림과 같이 P1 주변의 반경 내에 minpoints = 4개 이상의 data가 존재할 경우 군집이 형성되며, P1은 corepoint가 됩니다. 또한 P2 역시 4개 이상의 data가 존재하므로 corepoint가 되며, P1과 P2는
서로 군집의 일부가 되므로, 하나의 군집으로 연결이 됩니다.
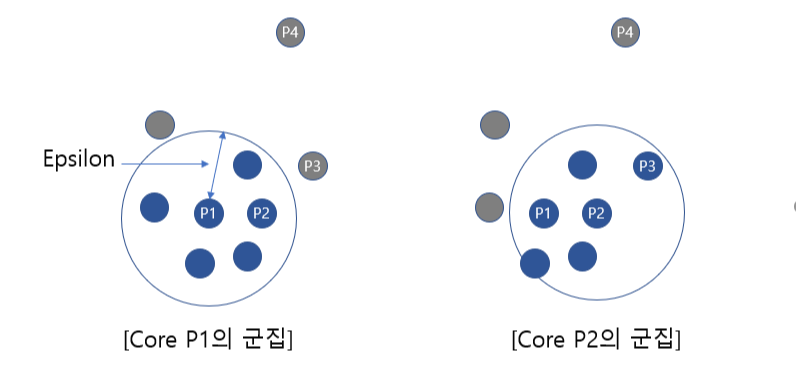
다음은 아래 그림의 P3의 경우, 주변에 2개의 data만 존재하므로 corepoint가 아닌 borderpoint가 되며 군집주변에 포함이 됩니다.
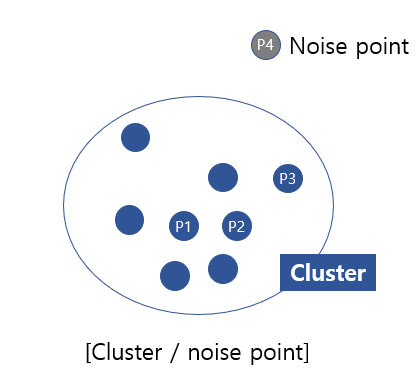
P4의 경우 어떤 점을 중심으로 하더라도, minpoints의 이상의 범위에 포함되지 않으므로 어느 군집에도 속하지 못하게 되며 이를 noise point라고 합니다.

이를 반복적으로 진행하게 되면, 아래와 같이 연결된 군집 / noise point를 구분할 수 있으며,
군집이 완성되어가는 형태는 다음과 같습니다.

최종적으로 3개의 cluster와 noise point들로 구분된 모습입니다.
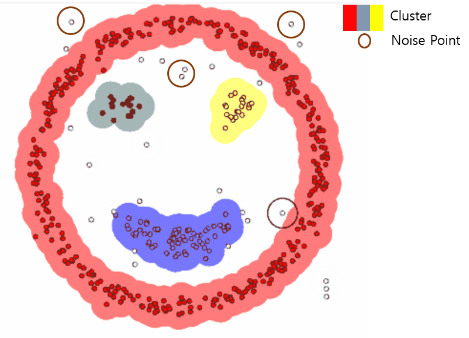
DBSCAN (Density-based spatial clustering of applications with noise)의 장점은,
1. K-means와 달리 초기 "K" 값을 설정할 필요가 없습니다.
2. 임의의 모양, 임의의 크기의 clustering이 가능하며, noise point를 고려한 clustering 또한 가능합니다.
단점은,
1. 초기에 epsilon (ε)과 minpoints를 설정해야 합니다.
2. Data의 밀도가 다양한 경우에 적합하지 않습니다.
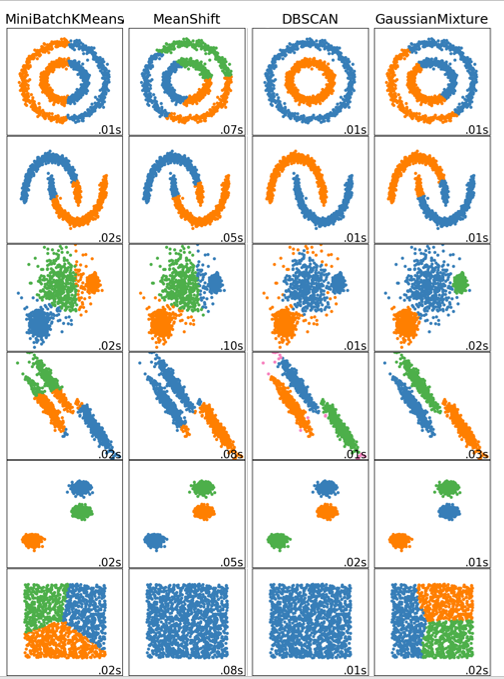
아래 이미지를 보면 K-means clustering과 DBSCAN clustering의 결과의 차이를 확인 할 수 있습니다.

4. EM clustering using Gaussian mixture model
EM clustering using Gaussian mixture model은 K-means 보다 좀 더 다양한 형태의 군집에 활용될 수 있습니다. Data points가 가우시안 분포라고 가정하므로, 평균을 이용한 단순 원이 되는 형태보다 다양한 형태의 clustering의 구현이 가능합니다. Cluster 모양을 정의하기 위해서 "평균", "분산"을 활용하고, 타원의 형태를 가지는 clustering의 군집화가 가능한 모델입니다.
EM clustering using Gaussian mixture model 에 대하여 본 글에서는 수식을 배제하고 대략적인 정의와 구현되는 프로세스에 대해서 알아보고자 합니다.
우선, EM (Expectation - Maximization) 알고리즘은 E-step / M-step 2단계로 나뉘어 지며, 2단계의 Step을 반복하면서 최적의 파라미터 값을 찾아가는 단계입니다.
E-step: 주어진 임의의 파라미터 초기값에서 likelihood 값을 계산합니다.
M-step: E-step에서 계산된 likelihood를 최대화하는 (maximize) 새로운 파라미터 값을 얻는 단계입니다.
E - M 단계를 반복하면서
다음으로 Gaussian mixture model에 대해서 설명하면,
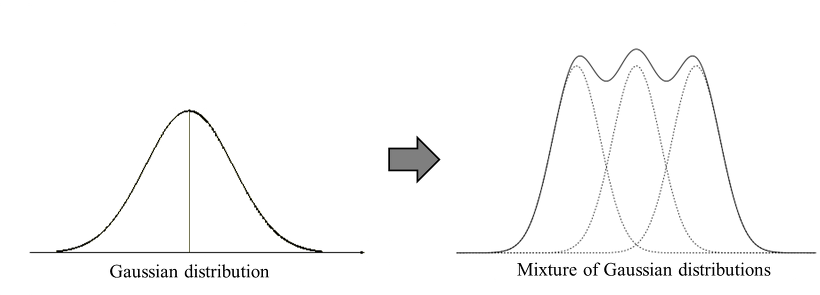
Gaussian mixture model (GMM) 이란 data point가 K개의 Gaussian 분포로 이루어져있다고 가정하는 모델입니다. 현실에 존재하는 복잡한 형태의 확률 분포를 아래 그림과 같이 K개의 Gaussian distribution을 혼합하여 표현하자는 것이 GMM의 기본 아이디어 입니다.
결국, EM clustering using Gaussian mixture model이란 각 data 포인트가 각각의 Gaussian distribution에 속할 확률을 정의하고 계산된 조건부 확률을 기반으로 최적 군집을 찾아나가는 clustering 입니다.
EM clustering using Gaussian mixture model의 구현 단계는 다음과 같습니다.
1. Cluster의 갯수(#)를 선택합니다.
2. 랜덤하게 Gaussian distribution parameter (θ: μ and σ) 를 설정합니다.
3. 모든 data point에 대해서 각각의 cluster에 속할 확률을 계산합니다.
4. 각각의 cluster에 속한 data point를 통해, Gaussian distribution parameter (μ and σ) 를 업데이트 합니다.
5. 각 cluster의 parameter가 변화하지 않을 때 까지 반복합니다.
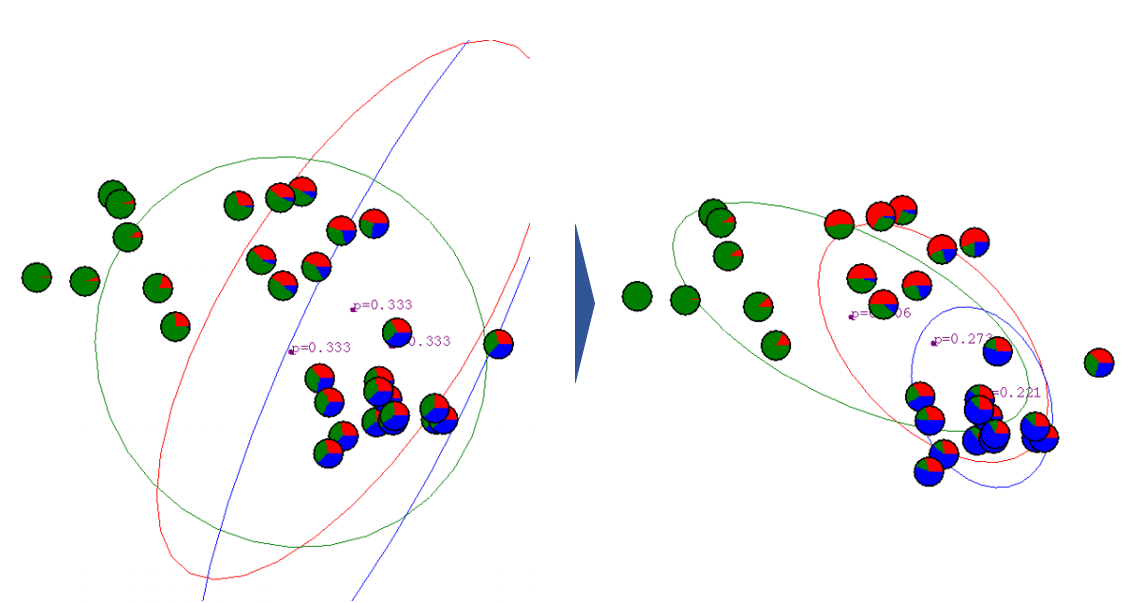
아래 그림은 처음 Gaussian distribution을 설정하고, first iteration을 진행한 모습입니다.
반복적으로 iteration을 진행하게 되면, 아래 그림과 같이 최적화된 clustering 형태가 구현됩니다.
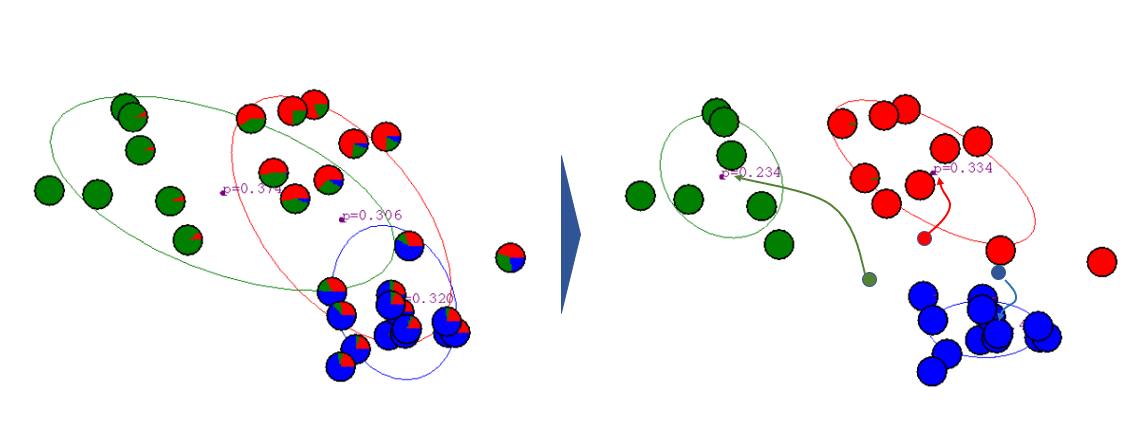
EM clustering using Gaussian mixture model을 구현되는 모습은 다음과 같습니다.
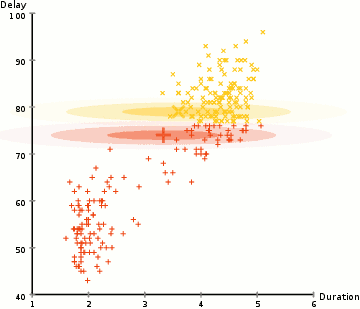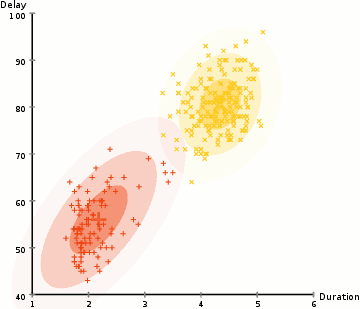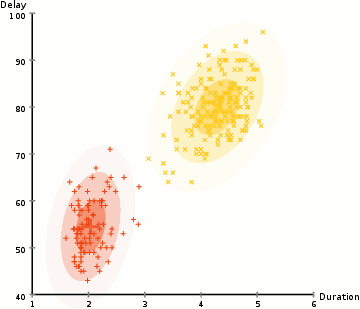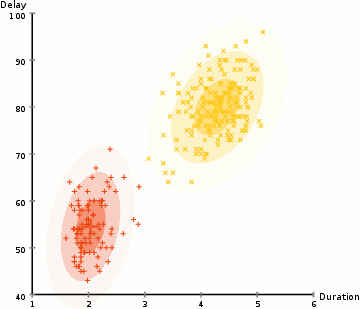
EM clustering using Gaussian mixture model의 장점은,
1. 구현할 수 있는 cluster의 모양이 K-means 에 비해서 flexible 합니다.
2. 복수의 cluster 내에서 overlap 된 data에 대해서 mixed membership 분석이 가능합니다.
예를들어 data point A는 cluster 1에 속할 확률 X, cluster 2에 속할 확률 Y의 형태로 분석이 가능합니다.
K-means의 경우 data point는 cluster 1에 속하거나, cluster2에 속하거나 하는 yes or no의 분석을
수행하는 것과 큰 차이점이라고 볼 수 있습니다.
단점은,
1. K-means clustering과 마찬가지로 임의의 "K" 값을 설정하여야 합니다.
2. 계산이 복잡하고 느립니다.
본 글에서는 주로 활용되는 clustering 모델의 구현 단계 및 장,단점에 대해서 알아보았습니다.
각 모델 별로 장단점이 있고, 동일한 data도 사용하는 모델에 따라 clustering 결과는 다양하게 나타나므로, data의 형태 / 분석 방향에 맞는 모델을 기반으로 clustering 하는 것이 중요하다고 볼 수 있겠습니다.
다음 글에서는 data 분석과정에서 광범위하게 활용되는 Dimensionality reduction에 대해서 알아보고자 합니다.
'AI Study > ML101' 카테고리의 다른 글
| [ML101]#9. 차원 축소(1) (0) | 2022.04.26 |
|---|---|
| [ML101] #7. Clustering (1) (0) | 2022.04.26 |
| [ML101] #6. Overfitting (0) | 2022.04.26 |
| [ML101] #5. Confusion matrix (0) | 2022.04.26 |
| [ML101] #4. Gradient descent (0) | 2022.04.26 |