이번 글에서 다룰 주제는 지금까지 공부했던 방법론들과는 조금 다른 목적을 가진 방법론을 다루고자 합니다.
그 주인공은 바로 "차원 축소(Dimesionality Reduction)"입니다. 차원 축소란 쉽게 이야기하면 중요한 변수들을 취하여 우리가 다루는 변수의 수를 줄이는 프로세스입니다.
[ML101-#1. Machine Learning?] 을 통해 차원 축소에 대해서 개괄적으로 소개를 해드렸는데요, 조금 더 자세히 살펴보도록 하겠습니다.
차원이란 무엇일까요?
이미 앞선 글들을 통해 계속 공부해오셨다면 쉽게 받아들이시고 있으실 거라고 생각됩니다. 차원이란 변수, 피처(feature), 열(column)과 같은 의미로 이해하시면 됩니다. 그렇다면 이 차원을 왜 축소시켜야 하는 것일까요? 반대로, 차원이 커질수록 왜 문제가 되는 것일까요?
위 질문들을 생각해 보기 전에 먼저 "차원의 저주(The Curse of Dimensionality)"란 무엇인지 살펴보도록 하겠습니다. 차원의 저주는 한 줄로 요약하면, 차원이 커질수록 데이터가 상대적으로 희박해지는 것을 의미합니다. 예를 들어 국내 A사가 축적한 고객 데이터는 1000건이며 남성 고객을 분류해 본다고 가정하겠습니다.
- 차원이 성별 하나(D=1)일 경우 샘플은 1000명 중 500명,
- 연령이 추가(D=2)되면 30대 남성은 500명 중 200명,
- 거주 지역 추가(D=3) 시, 경기도 거주하는 30대 남성은 200명 중 100명,
- 혈액형 추가(D=4) 시, 경기도 거주하는 A형인 30대 남성은 100명 중 10명,
(...) - 재직 기업 형태 추가(D=10) 시, 경기도 거주하는 A형 30대 남성 (...) 중소기업 재직자는 1명
이렇게 차원이 커질수록 컴퓨터 상에는 조건에 해당되지 않는 값들은 모두 0으로 채워지게 될 것입니다. 이는 모델이 학습할 수 있는 정보가 적어지는 현상을 야기하며, 성능 저하로 이어지게 되는 것입니다.
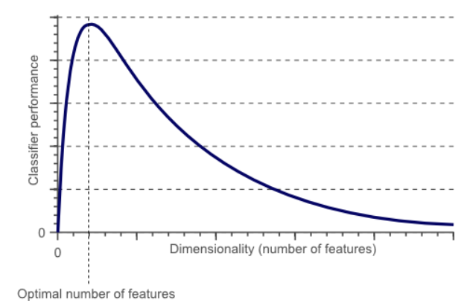
그렇다면 다시 질문으로 돌아가 보겠습니다. 왜 차원이 커질수록 문제가 되는 것일까요?
첫째, 자원(Resource)이 많이 필요합니다.
차원이 커질수록(다루는 피처가 많을수록) 컴퓨터(Machine)가 계산하는 시간이 증가하게 되고, 불필요한 값들을 저장해야 하는 공간이 많이 필요하게 됩니다. 더 적은 자원으로 동일한 목적을 달성할 수 있는 머신러닝 모델이 효율적이지 않을까요? 이러한 관점에서 차원 축소는 효율적으로 변수의 수를 줄일 수 있는 중요한 프로세스가 될 수 있습니다.
둘째, 오버 피팅(Overfitting) 현상이 발생합니다.
우리는 앞선 글에서 [ML101-#6. Overfitting] 을 함께 공부했습니다. 간단하게 리마인드 하자면 오버 피팅의 문제를 야기하는 이유 중 한 가지는 모델의 복잡도 때문이었음을 기억하실 것입니다. 차원이 커질수록 모델은 정교해지지만 복잡해집니다. 모델이 복잡해지면 입력이 약간만 달라져도 오차가 커지는 문제로 이어지며, 이를 방지하기 위해 차원 축소 기법이 활용됩니다.
셋째, 설명력이 저하됩니다.
설명력이란 말 그대로 사람이 모델의 내부구조 혹은 결과를 이해하기 쉬운 정도를 뜻합니다. 차원이 큰 모델들은 복잡해서 모델의 내부 구조를 이해하기 어렵게 되고, 모델이 내놓은 결과를 사람이 이해할 수 있도록 표현하는 것이 어려워지게 됩니다. 10차원의 데이터는 상상하기 어렵지만, 2차원의 데이터로 차원을 축소하면 다음과 같은 그림을 떠올리기 매우 쉬워지는 것과 같은 원리입니다.
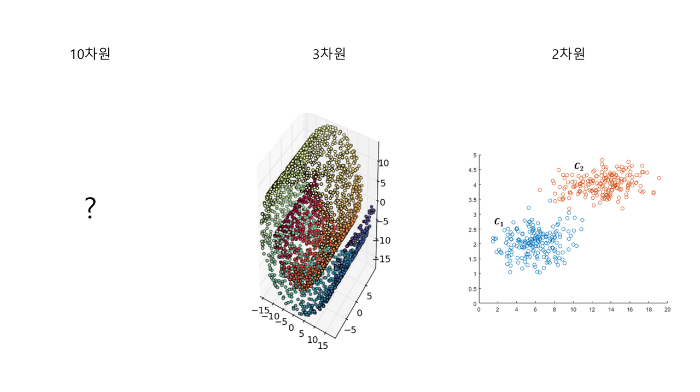
이러한 이유들로 인해 방대한 양의 데이터를 다루게 될수록 차원 축소를 고려하게 되는 것입니다. 이제 차원 축소를 어떻게 하는지 방법론에 대해서 살펴보겠습니다.
차원 축소의 방법에는 크게 Feature Selection과 Feature Extractration으로 나뉘게 됩니다. Feature Selection은 말 그대로 Feature를 선택하여 뽑는 것을 의미하며, Feature Extraction은 압축을 통해(데이터들의 특징 조합) 새로운 특징을 만들어 내는 것을 의미합니다.
1) Feature Selection
Feature Selection은 모델에 사용하기 위한 feature들을 선택하는 과정입니다. 최적의 feature 집합을 구하기 위한 모든 경우의 수는 2^N - 1 로 feature가 많아질수록 너무 많은 경우의 수가 생기기 때문에 현실적으로는 사용하기 어렵습니다. 그래서 최적의 데이터셋을 구하기 위한 방법들을 3가지로 분류합니다.
Filter-based method
Filter-based method 는 Feature 간 상관 관계 혹은 카이 제곱 검정 등 통계 분석을 통해 유의미한 데이터를 담고 있는 feature들을 골라내는 방법입니다.
하지만 feature를 선택하는 통계 분석이 모델의 성능에 직결되지는 않기 때문에 Filter-based 방법으로 나온 feature set이 모두 모델에 적합하다고 말하기는 어렵습니다. 대신, 계산 속도가 빠르고 상관 관계가 높은 feature 파악이 쉬워 1차적으로 전처리하는데 사용할 수 있습니다. 상관관계가 높다는 것은 곧 각 feature에 담긴 정보가 중복된다는 뜻으로 해석할 수 있기 때문에 그 중 하나를 제거해 feature를 줄여나가는 것이죠.
Filter-based method에는 아래와 같은 방법들이 존재합니다.
- information grain
- chi-square test
- fisher score
- correlation coefficient
- variance threshold

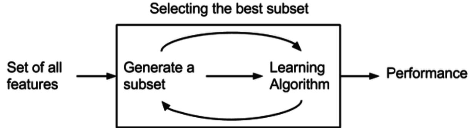
Wrapper-based method
Wrapper-based method 는 모델을 사용하여 성능 측면에서 가장 좋은 성능의 feature를 뽑아내는 방법입니다. 다만 모델을 계속 사용하면서 최적의 feature 집합을 찾아가는 방식이기 때문에 시간과 비용이 매우 높게 발생합니다.
wrapper-based method에는 크게 3가지 방법이 존재합니다.
- Forward selection (전진 선택)
가장 중요한 feature부터 하나씩 추가하면서 추가 전후 성능을 비교하여 feature 추가로 인한 성능 향상이 유의미하지 않을 때까지 feature set을 완성해나가는 방법입니다. - Backward elimination (후진 제거)
전체 feature에서 가장 중요하지 않은 feature부터 하나씩 제거하면서 모델의 성능 향상 정도를 확인하는 방법으로, 해당 방법도 성능의 향상이 유의미하지 않을 때까지 진행합니다. - Stepwise selection (단계별 선택)
Forward selection과 Backward elimination을 결합한 방법으로 시작은 전체 feature 혹은 아무것도 없는 상태로 시작합니다. 그래서 forward selection 혹은 backward elimination을 수행하다 임계점에 다다랐을 때, 반대 방법을 사용하는 것을 반복합니다.
Embedded method
Embedded-based method는 filter-based와 wrapper-based 의 장점을 합친 방법으로, wrapper-based 방식에서 모델 학습 과정에 패널티를 적용시키는 방법입니다. 모델 학습이 진행되면서 패널티로 인해 성능에 영향을 끼치지 못하는 feature들은 자동적으로 버리고, 남은 feature들로 다시 학습을 진행하며 최적의 feature-set을 찾습니다.
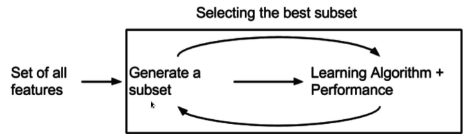
패널티를 적용하는 알고리즘은 대표적으로 아래와 같습니다.
- LASSO(L1-norm)
- RIDGE(L2-norm)
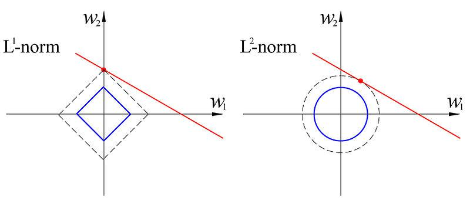
2) Feature Extraction
Feature Extraction 방법은 아래의 2가지 방법으로 분류됩니다.
- Linear methods: PCA(Principal Component Analysis), LDA(Linear Discriminant Analysis) 등
- Non-linear methods: AE(AutoEncoder), t-SNE 등
Feature Extraction은 Feature Selection에 비해 개념적으로 복잡하고 종류가 많아 다음 글에서 보다 자세히 다룰 예정으로, 이번 글에서는 Feature Extraction 종류와 대표적인 알고리즘에 대해서 언급하는 정도에서 넘어가도록 하겠습니다.
변수의 수를 줄이는 것은 머신러닝 프로젝트에서 중요한 과정 중 하나 입니다. 이를 위해서 차원 축소를 하게 된다고 서두에서 말씀드렸습니다. Feature Selection은 주로 정형 데이터(테이블 데이터)를 다루는 과정에서 많이 사용되고, Feature Extraction은 비정형 데티어(텍스트 데이터)를 다루는 과정에서 흔하게 사용되고 있습니다.
차원 축소는 위에서 보셨던 방법들에서도 아실 수 있겠으나 원본 데이터가 가진 정보를 잃어버리는 것입니다. 즉, 어떤 정보를 잘 잃어버리느냐가 차원 축소의 핵심 아이디어라고 할 수 있습니다. 다음 글에서는 간략하게 소개해드린 Feature Extraction의 방법들을 좀 더 자세히 공부해 보도록 하겠습니다.
'AI Study > ML101' 카테고리의 다른 글
| [ML101]#8.Clustering (2) (0) | 2022.04.26 |
|---|---|
| [ML101] #7. Clustering (1) (0) | 2022.04.26 |
| [ML101] #6. Overfitting (0) | 2022.04.26 |
| [ML101] #5. Confusion matrix (0) | 2022.04.26 |
| [ML101] #4. Gradient descent (0) | 2022.04.26 |