안녕하세요. 마인즈앤컴퍼니에서는 2021년 9월부터 2022년 1월까지 개최된 Kaggle PetFinder Pawpularity Competition에 참여해 3,537팀 중 97등 (Top 3%)로 은메달을 따냈습니다!
이번 레포트에서는 PetFinder Competition에 참여하면서 얻을 수 있었던 몇 가지 흥미로운 인사이트들을 공유하려고 합니다. 캐글 대회에 참여하고자 하는 국내 많은 데이터 사이언티스트들에게 도움이 되었으면 합니다. 그럼 시작하겠습니다!
대회 소개

A picture is worth a thousand words. But did you know a picture can save a thousand lives?
이번 대회는 보호소와 구조 단체에서 보호되고 있는 애완 동물을 입양할 수 있는 플랫폼 회사인 Petfinder에서 주최한 대회입니다. 유기견과 유기묘의 사진을 예쁘게 찍어주면 더 많은 사람들이 관심을 가질 테니 입양도 빨라지겠죠? 이를 위해 Petfinder에서는 동물 사진 별 인기도(Pawpularity Score)를 평가하는 문제를 출제했습니다. (popularity와 동물 발바닥을 뜻하는 paw를 합쳐서 Pawpularity라고 이름을 붙였네요 ㅎㅎ

The Pawpularity Score is derived from each pet profile's page view statistics at the listing pages, using an algorithm that normalizes the traffic data across different pages, platforms (web & mobile) and various metrics.
Pawpularity Score는 1점부터 100점까지의 정수로, 100점에 가까울 수록 인기도가 높다는 의미입니다. PetFinder측에서는 Pawpularity Score를 각 애완 동물의 프로필 페이지의 Traffic 등을 고려해 normalize한 view statistics를 통해 측정했다고 합니다. 하지만 ‘인기도’ 지표는 주관적이기 때문에 위 사진들처럼 귀여운 아이들도 낮은 점수를 기록했네요. 자연스레 target에 대한 noise 때문에 1등 조차도 RMSE 기준 16.822 수준 밖에 도달하지 못했습니다.
Insight 1 - Transformer, 이미지 분야까지 섭렵하다
이미지 분야 하면 가장 먼저 떠오르는 모델은 CNN입니다. CNN은 1998년 Yann LeCun이 제안한 LeNet부터 시작해 최근에 Efficient Net, ResNeXt 등에 이르기까지 수 많은 발전을 이뤄왔고 여전히 다양한 문제에서 엄청난 성능을 보여주고 있습니다.
그러나 이번 PetFinder Competition에서는 Transformer 기반의 Vision 모델이 CNN기반의 모델보다 대략 4% (참조 링크) 가량 우수한 성능을 거두었습니다. 그럼 여기서 왜 Transformer가 CNN 모델 보다 우수했을까요? 그리고 Transformer는 NLP 모델이 아니었나요..?
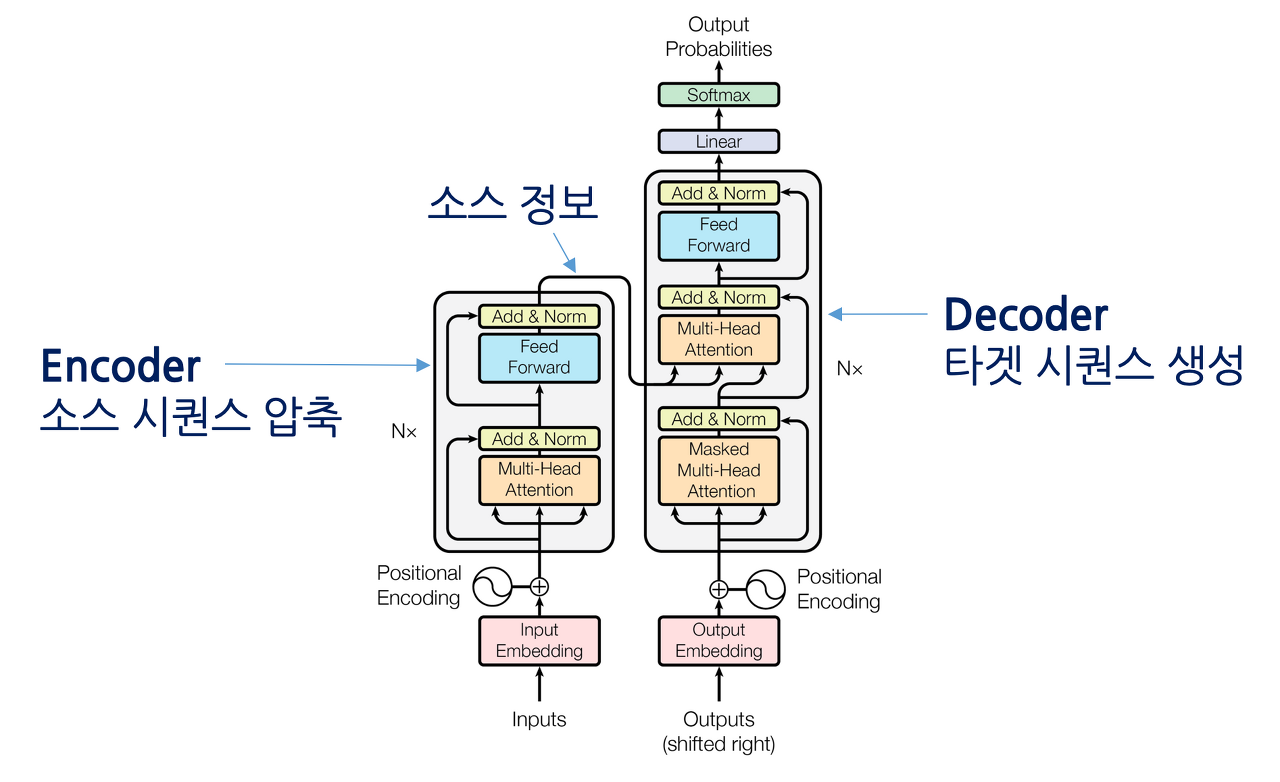
참조: https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
Transformer 간단 소개
Transformer는 2017년 구글에서 제안한 Encoder-Decoder 구조의 모델로 자연어나 시계열과 같이 순서를 가진 데이터에 적용하기 위해 제안된 시퀀스 모델입니다. Transformer는 기존에 주로 사용되던 시퀀스 모델인 Seq2seq와 같은 모델이 LSTM, GRU 등의 Recurrent model을 사용함으로 인해 병렬화가 어렵다는 문제를 해결하기 위해 이를 제거하고 Attention만으로 이루어진 Encoder-Decoder network를 제안했습니다.
Attention이란?
예를 들어, “나는 사과를 좋아한다. 이것은 빨갛다.”는 문장에서 ‘이것’이 무엇을 의미하는지 맞춰야 하는 상황에서 ‘사과’에 집중할 수 있도록 만들어주는 방법입니다.
Transformer의 Attention은 크게 Encoder-Decoder간의 Attention, Encoder 내의 Self-Attention, 그리고 Decoder 내의 Self-Attention으로 이루어져 있습니다. 다양한 Attention 방법의 적용을 통해 병렬화 뿐만 아니라 예측 성능의 개선까지 이루어낸 방법입니다.
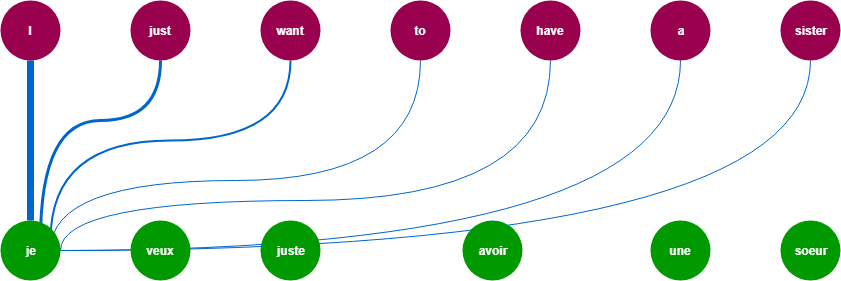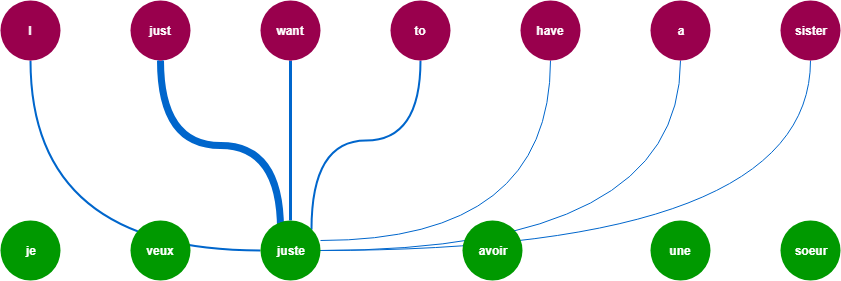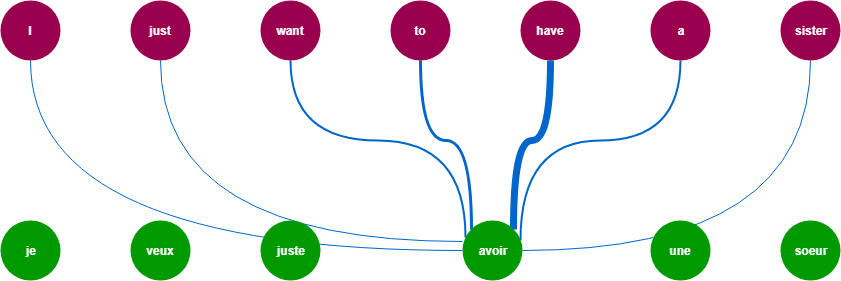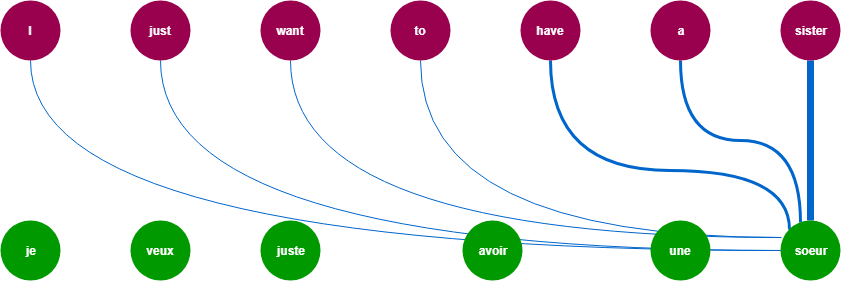
참조: https://trungtran.io/2019/03/29/neural-machine-translation-with-attention-mechanism/
참조: https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
Vision Transformer
최근에는 이러한 Transformer의 장점을 Vision 분야에도 적용하기 위한 시도가 활발하게 이루어지고 있습니다. ICLR 2021에서 공개된 ViT (Vision Transformer)부터 시작해서 ICCV 2021에서 공개된 Swin Transformer까지 작년부터 많은 발전이 이루어지고 있는 분야입니다.
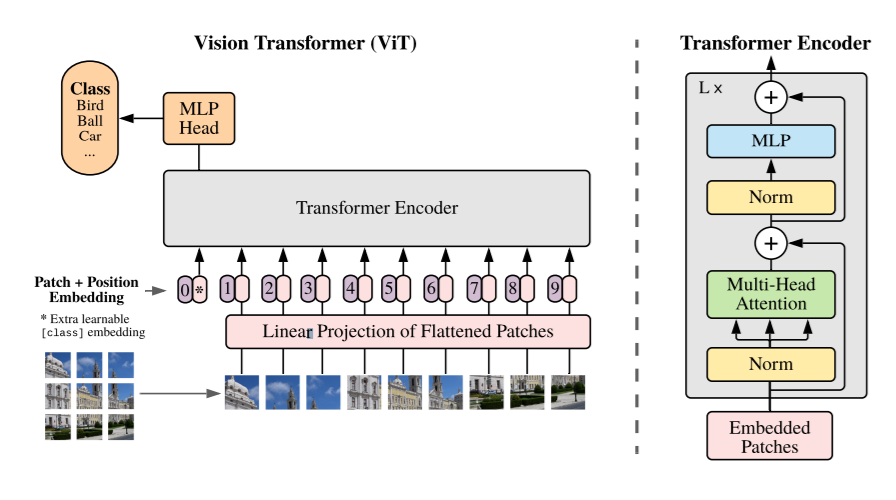
참조: https://openreview.net/pdf?id=YicbFdNTTy
Vision 분야에 Transformer를 적용하기 위해서는 먼저 이미지를 정해진 사이즈의 patch로 나눠줍니다. 예를 들어, 48 x 48 이미지를 16 x 16 사이즈로 나눠 총 9개의 patch를 만들어내는 것입니다. 그리고, 마치 텍스트 시퀀스를 취급하는 것과 같이 각 patch를 입력 시퀀스로 사용하는 것입니다. 구체적으로는, 이 patch들을 Flatten 및 Linear Projection을 해주고 Position Embedding을 통해 patch의 위치가 어디 인지에 대한 정보도 반영하여 Transformer Encoder의 입력으로 합니다. 이 후의 과정은 일반적인 Transformer와 크게 다르지 않습니다. 참고로 Vision Transformer는 Decoder를 사용하지 않습니다. 더 상세한 내용은 논문을 참고하시길 바랍니다.
Transformer vs. CNN

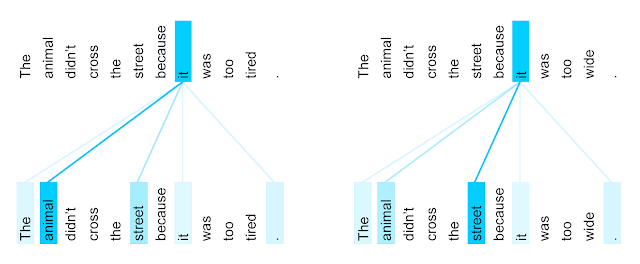
위 그림은 CNN과 Transformer 모델로 Pawpularity 데이터셋을 학습하고 Grad-CAM을 수행한 결과입니다. 색이 붉을 수록 예측에 중요한 영향을 미쳤다는 것을 의미합니다. CNN에서의 히트맵 결과를 보면 얼굴과 같은 Local 영역의 히트맵이 붉은 것을 알 수 있습니다. 반면에 Transformer의 경우 동물의 전반적인 영역에 히트맵이 노랗습니다. 달리 말하면, CNN은 얼굴과 같은 부분적인 부분을 보고 인기도를 예측했고, Transformer는 동물의 전체를 보고 예측했다는 것입니다.
단순히 동물의 종을 분류하는 문제였다면, 귀와 같은 Local 영역만 가지고도 분류가 잘 됐을 테니 CNN도 잘 동작했을 것입니다. 하지만, ‘인기도’와 같은 추상적인 지표는 동물의 전반적인 모습에 의해 오히려 큰 영향을 받을 것입니다. 예를 들어, 얼굴은 귀엽지만 몸이 매우 뚱뚱하다면 인기가 없겠죠. 반면, Transformer가 이러한 형태의 예측을 하는 것은 Attention 메커니즘 때문일 것입니다. 인기도를 예측하려면 ‘얼굴’, ‘털 색’에 집중해!라고 하는 것처럼 말이죠.
Target이 ‘인기도’, ‘예쁨’, ‘잘생김’, ‘나이 들어 보임’ 등의 추상적 개념이라거나, 사람이 보기에도 일부만 보고 판단할게 아니라 전반적으로 판단해야 할 Task라면 Vision Transformer를 사용해보면 어떨까요?
2편에서 계속 됩니다!
마인즈앤컴퍼니는 적극 인재 채용 중입니다. 많은 관심과 지원 바랍니다.
마인즈앤컴퍼니
Make the Most of AI
mnc.ai
'AI to the Real World > 캐글 탐험대' 카테고리의 다른 글
| 🥈은메달 수상기 (2) OTTO 추천시스템 대회: 챌린지와 우리의 솔루션 (0) | 2023.03.13 |
|---|---|
| 🥈은메달 수상기 (1) OTTO 추천시스템 대회 A to Z (0) | 2023.02.16 |
| [캐글탐험대] Happy Whale 대회 (0) | 2022.05.19 |
| [Kaggle] Doodle Recognition Challenge Insight-1 (0) | 2022.05.19 |
| [캐글탐험대] PetFinder 대회 (2편) (0) | 2022.04.26 |