안녕하세요. 마인즈앤컴퍼니의 AI 경진대회 플랫폼 ‘AI CONNECT’를 운영하는 AI 커넥트팀입니다.
저희 팀에서 함께 데이터사이언스의 세계를 파헤치고 있는 전혜령 인턴과 커넥트팀의 데이터사이언티스트들이 Kaggle에서 개최된 OTTO - Multi-Objective Recommender System 경진대회에서 2,587 팀 중 128등이라는 기록을 내며 은메달을 차지했습니다!
이 기쁜 소식과 함께, 은메달 수상기를 블로그를 통해 미래의 데이터사이언티스트 및 AI 과학자들과 공유하려 하는데요. 첫 번째 편인 이번 글에서는 OTTO 대회에 대한 자세한 소개 및 대회에 참여하며 얻게 된 몇 가지 팁을 소개합니다.
작성: 마인즈앤컴퍼니 전혜령 인턴 (연세대 응용통계학 19)
검수: 마인즈앤컴퍼니 Data Scientist 박기돈 매니저 (AI커넥트사업부)
마인즈앤컴퍼니 Data Scientist 곽치영 매니저 (AI커넥트사업부)
OTTO는 어떤 대회야?
온라인 쇼핑 플랫폼은 고객의 편의를 위해 다양한 상품 및 서비스를 제공합니다. 그러나 고객에게 너무 많은 제품 선택지를 줄 경우, 오히려 뭘 결정해야할지 혼란을 줄 수 있습니다. 많은 온라인 쇼핑 플랫폼이 추천 시스템을 도입해 개인화된 상품을 추천하여 소비자들의 선택에 도움을 주고 더 많은 구매를 유도하기 위해 노력하는 이유죠.
이번 경진대회 주최사인 독일 온라인 쇼핑 플랫폼 OTTO은 19,000개 이상의 브랜드로부터 무려 1,000만 개가 넘는 제품을 보유하고 있습니다. 이렇게 제품이 많다보니 OTTO에서도 소비자들의 제품 선택을 위해, 고객들의 활동 기록을 바탕으로 적절한 제품을 추천해주기를 원했습니다.바로 이 문제를 Kaggle 경진대회를 주최해서 해결하고자 했습니다. 좀더 구체적으로 설명드리자면, 고객이 1) 클릭하고(click), 2) 카트에 담고(cart), 3) 주문할(order) 아이템을 추천하는 "multi-objective 추천 시스템 모델"을 구축하는 것이 이번 대회의 목적입니다.

데이터셋과 EDA
(1) Dataset Description
{
"session": 42,
"events": [
{ "aid": 0, "ts": 1661200010000, "type": "clicks" },
{ "aid": 1, "ts": 1661200020000, "type": "clicks" },
{ "aid": 2, "ts": 1661200030000, "type": "clicks" },
{ "aid": 2, "ts": 1661200040000, "type": "carts" },
{ "aid": 3, "ts": 1661200050000, "type": "clicks" },
{ "aid": 3, "ts": 1661200060000, "type": "carts" },
{ "aid": 4, "ts": 1661200070000, "type": "clicks" },
{ "aid": 2, "ts": 1661200080000, "type": "orders" },
{ "aid": 3, "ts": 1661200080000, "type": "orders" }
]
}
데이터는 크게 session과 events로 구성됩니다. 여기서 session은 데이터 수집 기간 동안 저장된 사용자 정보로, 한 유저를 식별할 수 있는 아이디이며, 일반적인 session과는 그 의미가 약간 다릅니다. 각 단어의 의미는 아래와 같습니다.
- session : 세션 id
- events
- aid: event가 발생한 아이템 id
- ts: event 발생 시간(UNIX time)
- type: event 종류로, click, cart, order 중 하나
이를 토대로 위의 자료의 일부를 가져와서 살펴보겠습니다.
"session": 42,
"events": [
{ "aid": 0, "ts": 1661200010000, "type": "clicks" },
{ "aid": 1, "ts": 1661200020000, "type": "clicks" },
해당 데이터는 42번 session에 대한 정보를 나타내며, 발생한 첫 번째 event는 0번 아이템에 대한 클릭, 두 번째 event는 1번 아이템에 대한 클릭인 것을 알 수 있습니다.
(2) Train/Test Split
데이터셋 내의 총 session id는 약 1,300만개(12,899,779개), aid id는 약 186만개(1,855,603개), event는 약 2억개(216,716,096) 정도 존재합니다. 모델의 학습 및 평가를 위해 데이터셋은 시간에 따라 아래와 같이 train과 test로 나누어 제공되었습니다.
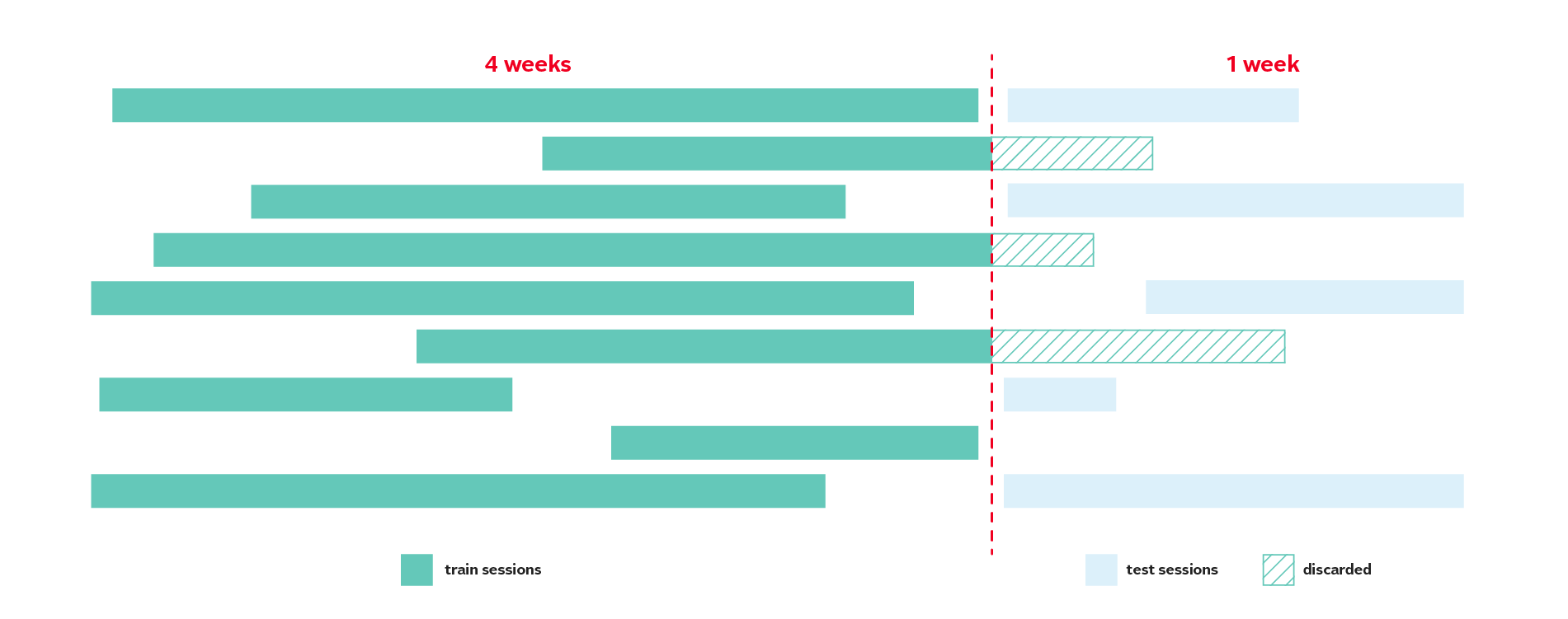
수집 기간은 22/08/01부터 22/09/04로 총 5주 입니다. 이 중 시작일로부터 4주간 관측된 데이터는 train으로, 마지막 1주 동안 관측된 데이터는 test로 제공되었습니다. 이 때 위 그림에서 볼 수 있듯이 미래 정보에 대한 유출을 막기 위해 train에서 test까지 이어진 session의 경우 test에서 제거된 상태입니다.
이렇게 가공된 train 데이터셋은 총 12,899,779개의 session을 포함하며, test 데이터셋은 총 1,671,803개의 session을 포함합니다. 즉, test의 session 약 160만개에 대하여 각 event type 별로 전체 아이템 186만 개 중 유저가 관심있을 만한 아이템을 최대 20개 추천해야 하는 것입니다.
(3) EDA
Train 데이터셋에 대한 각 type 별 분포는 아래와 같습니다.
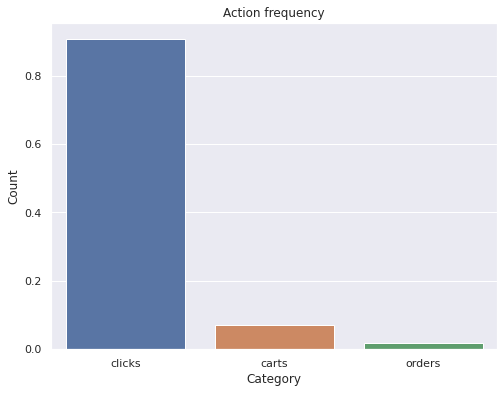
총 event 중 약 90% 정도가 click, 약 8% 정도가 cart, 나머지 약 2%가 order로 구성되어 있습니다.
다음으로 각 session 별로 몇 번의 event를 포함하고 있는지 살펴보겠습니다. 아래 그래프의 x축은 세션에 포함된 event 수, y축은 세션 수를 나타냅니다. (event 수의 경우 30 미만으로 제한하였습니다.)
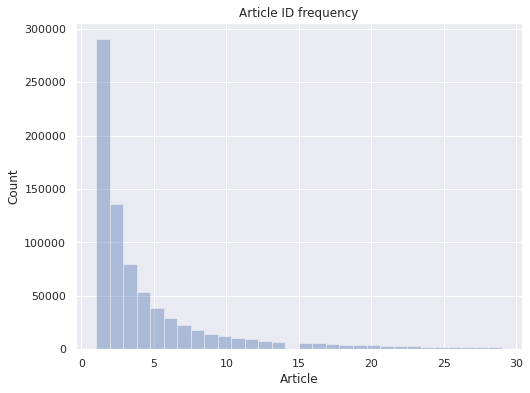
그래프에서 볼 수 있듯 대부분의 session에 5번 이하의 event가 존재하는 것을 볼 수 있습니다. 따라서 한정된 개인 활동 정보를 활용해 추천을 하는데 어려움이 발생할 것으로 예상할 수 있었습니다.
Evaluation
위의 데이터셋을 활용하여 이번 대회에서 예측하고자 하는 바를 정리하면 아래와 같습니다.
- test session의 마지막 시점으로부터
- click: 바로 다음 aid 예측
- cart, order: 이후 발생하는 aid 예측
- 각 type 별 최대 20개까지 예측 가능
위 조건에 따른 예측 결과는 아래와 같은 형식으로 제출되어야 합니다.
session_type,labels
12906577_clicks,135193 129431 119318 ...
12906577_carts,135193 129431 119318 ...
12906577_orders,135193 129431 119318 ...
12906578_clicks, 135193 129431 119318 ...
제출된 결과는 각 type에 따라 Recall@20에 따라 평가되고, event type 별 Recall의 가중합으로 최종 점수가 계산됩니다.
먼저 추천 시스템의 대표적인 평가 지표들(Recall@k, MAP@k, NDCG@k)을 살펴본 뒤, OTTO 챌린지의 평가 지표를 보다 자세하게 보도록 하겠습니다.
(1) Recall@k

Recall@k는 사용자가 관심 있는 아이템 중 모델이 추천한 k개의 아이템에 얼마나 포함 되는지를 의미합니다. 식에서 m은 사용자가 관심 있는 아이템, n은 추천 아이템 중 사용자가 관심 있는 아이템을 의미합니다.
$$ Recall@k = {n \over m} $$
예를 들어, 실제로 사용자가 구매한 아이템은 A, B이고 모델이 이 사용자가 구매할 것이라고 예측한 아이템은 A, C, D, E, F 라고 생각해 봅시다. 이 때 사용자가 구매한 아이템은 2개(A, B), 이 중 모델이 추천한 아이템은 1개(A)이므로 Recall@5 = 1/2 = 0.5로 계산됩니다.
Recall의 경우 값의 최댓값을 1로 맞춰주기 위하여 분모를 min(m,k)로 하여 계산하기도 합니다. 모델이 추천한 아이템보다 사용자가 관심 있는 아이템 수가 많다면 모델이 최대로 추천하여도 값이 1이 되지 않는 문제를 해결하기 위하여 사용하는 방법입니다.
$$ Recall@k = {n \over min(m,k)} $$
이처럼 Recall은 사용자가 관심 있는 아이템을 모델이 모두 잘 추천해주었는지를 나타냅니다. 그러나 Recall의 경우 상대적인 선호도를 반영할 수 없다는 단점이 있습니다. 예를 들어 사용자가 A와 B를 모두 구매했지만 A를 더 선호한다고 했을 때, Recall을 평가 지표로 사용하게 된다면 두 아이템의 추천 순서와 상관없이 동일한 평가값을 얻게 됩니다.
가장 연관성이 높은 상위 k개를 노출 시키는 것도 중요하지만 k개를 어떤 순서로 사용자에게 보여줄 것인지도 중요합니다. 앞으로 살펴볼 MAP와 NDCG는 이러한 순서를 반영한 평가 지표입니다.
(2) MAP@k
MAP@k는 Mean Average Precision@k로, Average Precision의 Mean을 의미합니다. Precision, AP(Average Precision), MAP(Mean Average Precision) 순으로 하나하나 살펴보도록 하겠습니다.
- Precision@k

Precision@k는 ‘모델이 추천한 k개의 아이템 중 사용자가 관심 있는 아이템이 얼마나 포함되는지’를 의미합니다. 위와 같은 예시에서 모델이 추천한 아이템은 5개(A, C, D, E, F) 중 사용자가 실제로 구매한 아이템은 1개(A)이므로 Precision@5 = 1/5 = 0.2로 계산됩니다.
- AP@k
AP(Average Precision)의 경우 위의 지표들과는 다르게 추천의 순서에 영향을 받게 됩니다. 이전에는 추천 결과와 실제 사용자의 관심 상품이 일치 하는지에 대해서만 확인했다면, 이제는 모델이 가장 먼저 추천한 결과와 관심 상품이 일치 하는지에 대해 구하게 됩니다. AP@k의 식은 아래와 같습니다.
$$ AP@k = {1 \over m}\sum_{i=1}^{k}Precision@i \cdot rel(i) $$
위 식에서 Precision@i는 추천한 k개의 아이템 중 i번 째 까지만 고려 하였을 때의 값을 나타내고, rel(i)는 사용자의 관심 상품인지 아닌지를 나타냅니다. 실제 관심 상품인 경우 1, 아닐 경우 0의 값을 갖게 됩니다. 마지막으로 m은 사용자의 관심 상품의 수를 의미합니다. 아래 그림의 예시를 보도록 하겠습니다.
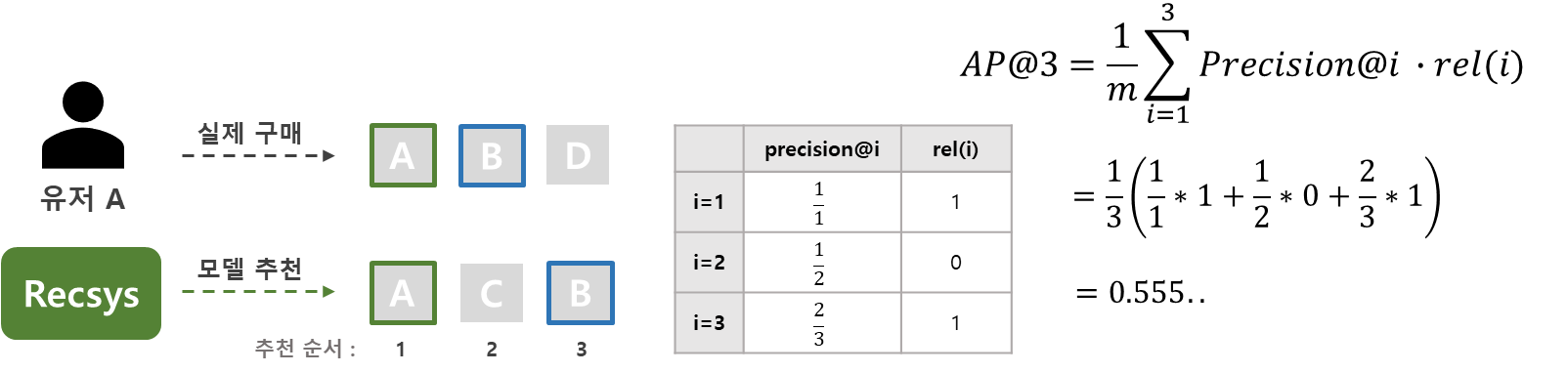
그림에서 모델은 순서대로 A, C, B 3가지 아이템을 추천 하였고, 이 중 사용자는 A, B 아이템을 구매하였습니다. 사용자는 모델이 첫 번째로 추천한 아이템 A를 구매 하였으므로, Precision@1은 1이 되게 됩니다. 이런 식으로 그림의 표와 같이 Precision@i와 rel(i)를 구하여 AP@3를 계산하면 약 0.56 정도의 값을 얻을 수 있습니다.
만일 모델이 C, A, B 순서대로 아이템을 추천 했다면 값이 어떻게 바뀌었을까요? Precision@1이 0, Precision@2가 1/2이 되며 전체적인 AP@3값이 작아졌을 것입니다. 이렇듯 같은 아이템을 추천 하더라도 추천 순서에 따라 값이 다르게 도출되도록 하는 지표가 AP@k 입니다.
Recall과 마찬가지로 AP 역시 값을 0과 1사이로 정규화하기 위해서 아래의 식을 통해 값을 구하기도 합니다.
$$ AP@k = {1 \over min(m,k)}\sum_{i=1}^{k}Precision@i \cdot rel(i) $$
- MAP@k
마지막으로 MAP(Mean Average Precision)는 모든 사용자들의 AP 값의 평균입니다. MAP@k의 식은 아래와 같습니다.
$$ MAP@k = {1 \over \vert U \vert}\sum_{i=1}^{\vert U \vert}(AP@k)_{u} $$
위 식에서 $\vert U \vert$는 사용자의 수를 의미합니다. 식에서 볼 수 있듯 각 사용자들의 AP값의 평균인 MAP값은 아래 예시와 같이 구할 수 있습니다.

이와 같이 MAP는 어느 정도 순서를 반영한 평가값을 얻을 수 있지만, 선호도가 있는 아이템인지 없는 아이템인지 (binary rating)에 대해서만 구분하고 별점과 같은 구체적인 rating으로 선호도를 구분할 수는 없다는 단점이 있습니다.
3. NDCG@k
NDCG(Normalized DCG)의 경우 위에서 살펴본 MAP@k와 같이 추천 순서를 반영하는 지표입니다. 그러나 MAP@k는 relevance(rel(i))가 0 또는 1의 값을 가졌던 반면, NDCG는 순서 별로 다른 값을 갖게 됩니다. 즉, NDCG는 구체적인 rating과 같은 상대적 선호도도 평가에 반영한 지표입니다.
NDCG을 소개하기 앞서 CG(Cumulative Gain), DCG(Discounted Cumulative Gain)에 대해 먼저 알아보도록 하겠습니다.
- CG(Cumulative Gain)
CG(Cumulative Gain)란 모델이 추천한 아이템들의 relevance의 총합을 의미하며, 아래와 같은 식으로 표현 가능합니다.
$$ Cumulative \ Gain = \sum_{i=1}^{k}relevance_{i} $$
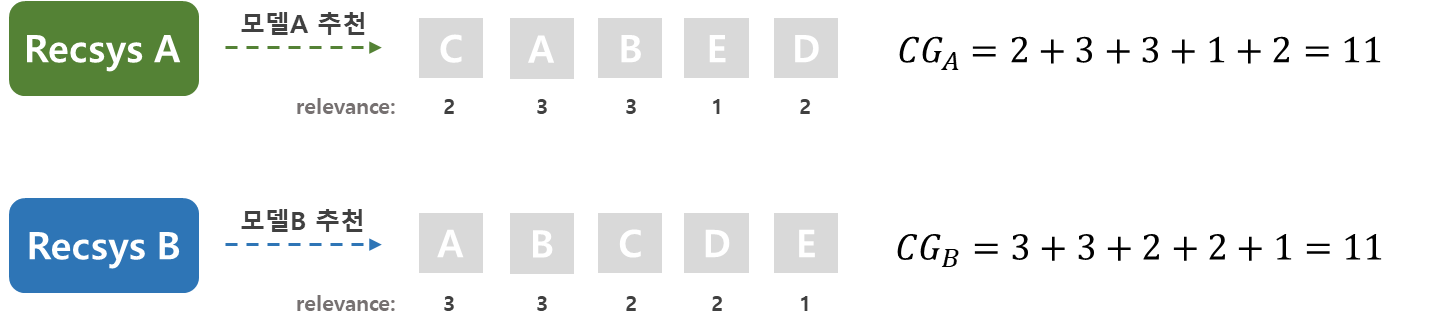
예를 들어, 어떤 사용자가 A, B, C, D, E 5개의 아이템을 구매하였고, 먼저 위치한 순서대로 사용자의 실제 우선 순위가 높다고 가정해보도록 하겠습니다. 모델A와 모델B의 결과를 보면 모델B가 먼저 위치한 아이템에 relevance score를 더 크게 부여 하였으므로 더 우수한 모델이라고 생각해볼 수 있으나, 두 모델의 CG 값은 11로 동일하므로 이를 통해서는 성능 평가가 불가능하다는 것을 알 수 있습니다.
이를 해결하기 위해서는 먼저 위치한 relevance score가 결과에 더 큰 영향을 주도록 조정해주어야 할 필요가 있습니다.
- DCG(Discounted Cumulative Gain)
위의 문제점을 해결한 지표가 DCG(Discounted Cumulative Gain)입니다. DCG는 나중에 위치 할수록 분모가 커지게끔 하여, 아이템의 순서가 뒤에 있을수록 relevance score가 전체 결과에 영향을 작게 미치도록 조정합니다.
$$ DCG_k = \sum_{i=1}^{K} {relevance_{i}\over log_{2}(i+1)} $$
모델A와 모델B의 DCG를 구해보도록 하겠습니다.
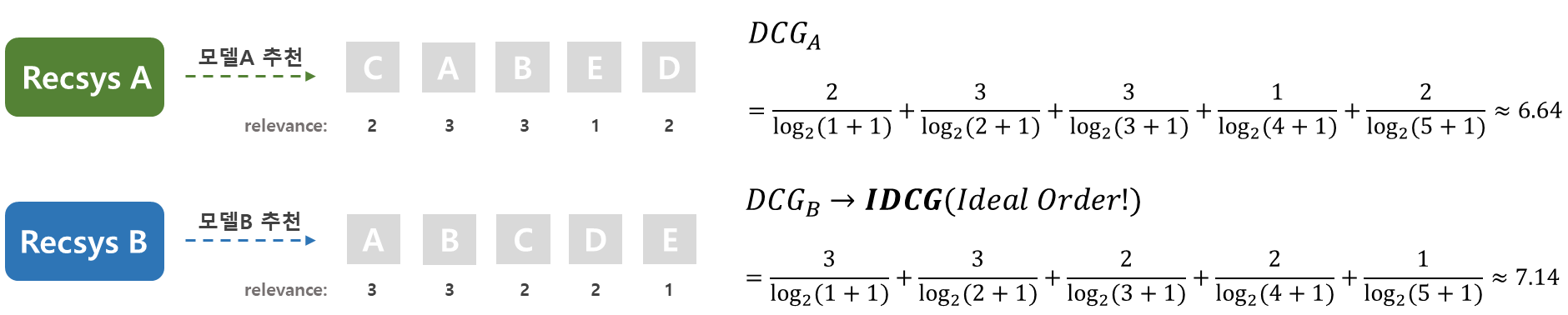
k=5라고 가정하고 값을 구했을 때, 모델B의 DCG값이 더 크게 나오는 것을 확인할 수 있습니다.
IDCG(Ideal DCG)는 아이템의 relevance가 큰 순서대로 배열하였을 때 나오는 최대 DCG 값을 의미합니다. 그림에서는 모델B의 결과값인 7.14가 아이템에 대한 IDCG 값이 됩니다.
- NDCG(Normailzed DCG)
DCG의 경우 성능 평가가 가능한 것은 확인 하였으나 추천 아이템의 수가 많을수록 값이 커진다는 단점이 있습니다. 이를 해결하기 위하여 DCG에 정규화가 추가된 지표가 NDCG이며, 식으로는 아래와 같이 표현 가능합니다.
$$ NDCG_k = {DCG_k\over IDCG_k} $$
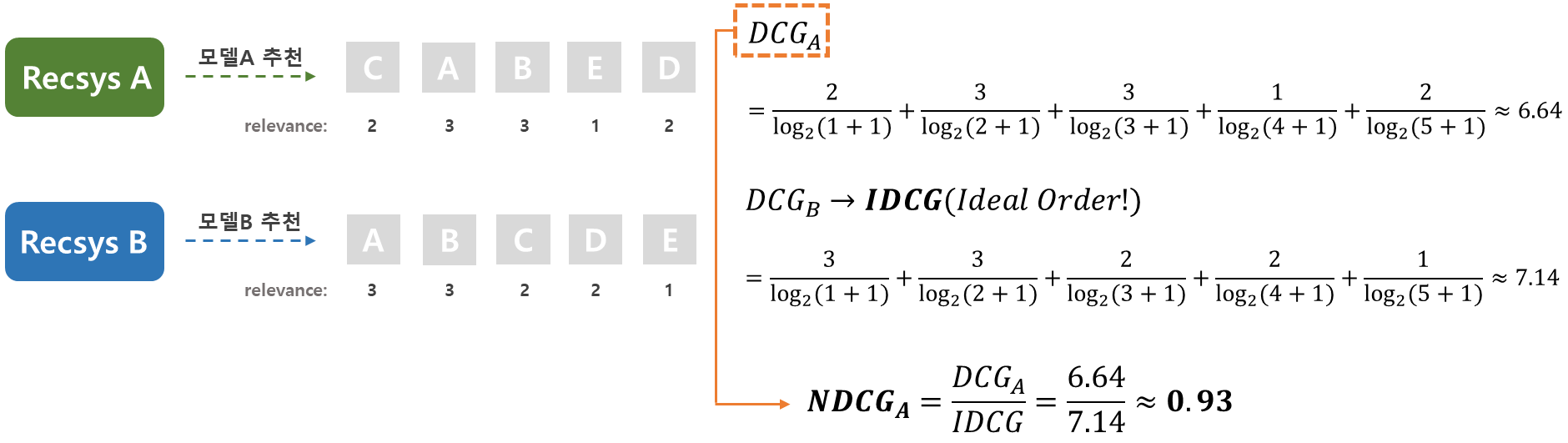
위 식을 사용하여 계산해보면 그림과 같이 NDCG_A의 값은 0.93, NDCG_B의 값은 1이 됩니다. 이처럼 모델이 가장 이상적인 추천 결과를 낼 때의 NDCG값은 1이 되고, relevance값이 모두 0일 때는 NDCG값이 0이 되므로 최종 지표를 0과 1 사이의 값으로 표현 가능합니다.
결과적으로 NDCG는 구체적인 rating에 기반한 순서를 고려한 지표로, 가장 이상적인 조합 대비 현재 모델의 추천 리스트가 얼마나 좋은지를 의미합니다.
정리해보면,
- 추천 순서 고려하지 않음 → Recall@k (또는 Precision@k)
- 추천 순서 고려해야 함
- 선호도에 대해 선호한다(1)/안한다(0)와 같이 binary rating 사용 → MAP@k
- 선호도에 대해 별점과 같은 구체적인 rating 사용 → NDCG@k
와 같이 사용하면 되겠습니다.
(4) OTTO Evaluation Metric
본 대회의 경우 각 session에 대하여
- click의 경우 바로 다음 click 아이템 예측
- cart, order의 경우 순서 상관없이 아이템 예측
을 수행해야 합니다. 즉, 추천 순서를 고려하지 않으며, 추가로 구체적인 rating feature도 주어지지 않은 상황입니다.
따라서 이번 대회에서 사용되는 Metric은 각 event type별 Recall@20이며, 최종 점수는 아래의 식을 통하여 계산됩니다.
$$ score = 0.10 \cdot R_{clicks} + 0.30 \cdot R_{carts} + 0.60 \cdot R_{orders} $$
식을 통하여 order에 대한 Recall의 가중치가 가장 큰 것을 확인할 수 있습니다. 따라서 앞으로 주문할 아이템을 잘 예측하는 것이 중요한 태스크라고 볼 수 있겠습니다. 실제 비지니스 관점에서 생각해보아도 단순히 다음에 클릭할 아이템을 맞추는 것보다 장바구니에 넣거나 주문할만한 아이템을 추천하는 것이 더 중요 할 텐데 이를 반영한 Metric이라는 생각이 듭니다. 식에서 R은 아래와 같이 정의 되며, $N$은 test set의 전체 session 수를 의미합니다.
$$ R_{type} = {\sum_{i}^{N}{\vert{\{predicted \ aids\}{i,type}\cap\{ground \ truth \ aids \}{i, type}\vert}}\over{\sum_{i}^{N} min(20, \vert\{ground \ truth \ aids \}_{i, type}\vert )}} $$
간단한 예시를 하나 살펴보도록 하겠습니다.
추천 결과와 실제 정답값이 위 표와 같다고 가정 했을 때, 해당 세션에 대한 점수는
$$ 0.10 \cdot \frac11 + 0.30 \cdot \frac01 + 0.60 \cdot \frac14 = 0.25 $$
와 같이 계산됩니다.
지금까지 OTTO 챌린지를 대략적으로 설명드리면서, 추천 시스템의 평가 지표에 대해서도 함께 소개해드렸습니다. 다음 포스팅에서는 실제 이 대회의 어려운 점과 해결 방법 그리고 어떤 솔루션이 좋은 성능을 냈는지 공유하려하니, 많은 관심을 부탁드립니다. 감사합니다.
'AI to the Real World > 캐글 탐험대' 카테고리의 다른 글
| 🥈은메달 수상기 (2) OTTO 추천시스템 대회: 챌린지와 우리의 솔루션 (0) | 2023.03.13 |
|---|---|
| [캐글탐험대] Happy Whale 대회 (0) | 2022.05.19 |
| [Kaggle] Doodle Recognition Challenge Insight-1 (0) | 2022.05.19 |
| [캐글탐험대] PetFinder 대회 (2편) (0) | 2022.04.26 |
| [캐글탐험대] PetFinder 대회 (1편) (0) | 2022.04.26 |