안녕하세요. 마인즈앤컴퍼니의 테크리더 명대우 파트너님은 Kaggle Master 이신데요.
마인즈앤컴퍼니에 오신 이후에도 다른 매니저들과 함께 Kaggle 을 출전하기도 하시고,
매니저들에게 Kaggle Insight를 전해주기도 합니다.
그 중 Kaggle 의 Quick, Draw! Doodle Recognition Challenge 로 학습하고 싶은 분들과,
다른 Kaggle 대회 출전을 준비하고 있으신 분들을 위해 도움이 되는 글을 작성해주셨습니다.
Quick, Draw! Doodle Recognition
작성: 마인즈앤컴퍼니(MNC) 명대우 파트너
대회소개
이 대회는 사람이 제한시간 20초 이내에 빨리 그린 낙서들을 분류하는 대회입니다. 직접 관련이 있는 애플리케이션으로는 필기 인식(Handwriting Recognition), 문자 인식(OCR-Optical Character Recognition) 등이 있습니다.

| 구분 | 내용 |
| 주 제 | 낙서 분류 |
| 주최 | Google Research |
| 총 상금 | $25,000 |
| 문제 유형 | 멀티 클래스 분류 |
| 데이터 타입 | Tabular |
| 평가 방법 | Mean Average Precision |
| 대회 참여 팀 | 1,316 팀 |
데이터 소개
다음 URL에 접속하면 《Quick, Draw!》(퀵, 드로!)라는 게임이 나옵니다.
Quick, Draw!
신경망이 학습을 통해 낙서를 인식할 수 있을까요? 내 그림은 얼마나 잘 맞추는지 확인하고, 더 잘 맞출 수 있도록 가르쳐 주세요. 게임을 플레이하기만 하면 됩니다.
quickdraw.withgoogle.com
게임을 시작하면 20초 내에 그림을 그리라는 지시사항이 나옵니다. 그림을 그리면 신경망 모델이 어떤 그림인지 맞추는 게임입니다. 이 게임에서 발생한 데이터들이 대회에서 사용되었습니다.
데이터를 좀더 구체적으로 이해하기 위해 직접 게임을 해보았습니다. 그림을 잘 그리는 편이 아닌데 아래 그림과 같이 모델이 상당히 정확하게 맞추고 있습니다.
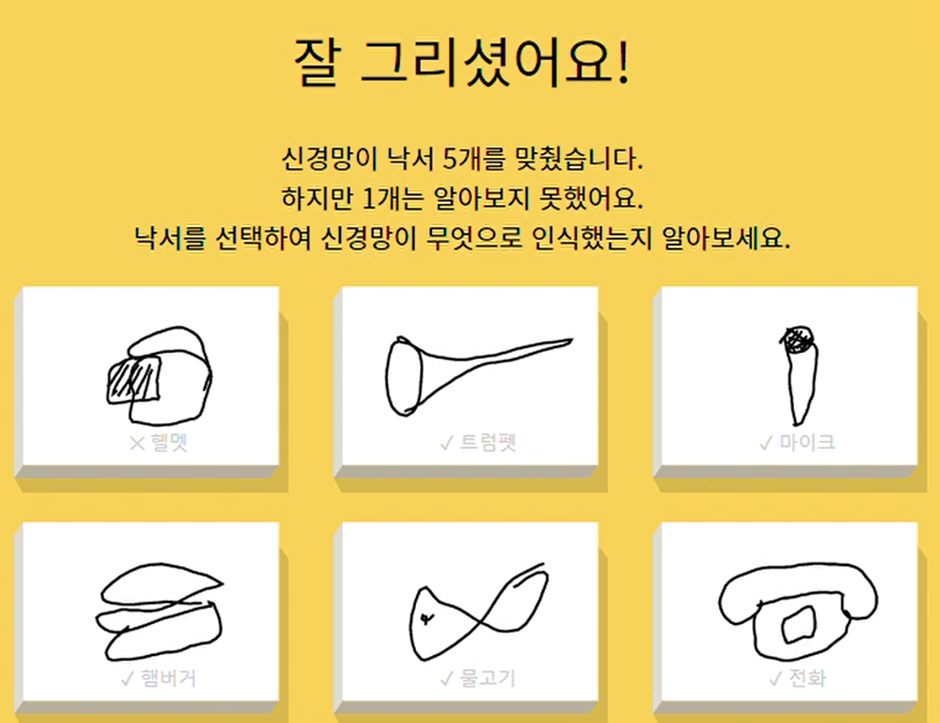
이와 같이 캐글 대회를 할 때는 (사람이 확인이 가능한 데이터라면) 샘플 데이터를 직접 확인해 보는 것을 추천합니다. 이미지라면 각 레이블 별로 몇 장씩 확인해 보고, 음성이라면 각 레이블 별로 들어 보고, 동영상이라면 재생해 봅니다. 이렇게 하면 추후 모델 설계 및 데이터 생성 기 구현에 대한 아이디어가 떠오를 때가 많습니다.
평가지표
이 대회의 평가 지표는 MAP@K(mean average precision at k)를 쓰고 있습니다. 이 대회에서는 k가 3입니다. 주로 정보 검색 분야에서 많이 쓰는 평가 지표로 알고리즘이 k개 추천/예측한 값들이 몇 번째 만에 맞춘 것인지 가중치가 반영된 점수입니다.
MAP@K는 테스트 셋 들의 AP@K 평균입니다. AP@K가 어떻게 계산되는지 예를 통해서 살펴보겠습니다. 정답인 'A'인 4개의 테스트 셋에 대해, 각 데이터 별로 예측 값 3개씩을 제출했을 경우 아래 표와 같습니다. 이 대회에서 테스트 셋 1개 행 별 정답은 1개이고, 3개의 값을 제출하며, 중복된 값은 제출하지 않습니다.
[AP@K 점수]
| 정답 | 모델의 예측 값 | AP@K 점수 |
| A | A, B, C | 1.0 |
| A | B, A, C | 0.5 |
| A | B, C, A | 0.333 |
| A | B, C, D | 0.0 |
최종 점수인 MAP@K는 각 테스트 셋 행 별 AP@K 점수들의 평균입니다. AP@K 점수에서 최종 점수인 MAP@K는 (1.0 + 0.5 + 0.33) ÷ 4 입니다. AP@K 계산을 함수로 만들면 다음과 같습니다.
def apk(actual, predicted, k):
if actual not in predicted: # 제출한 값에 정답이 없으면 score는 0
return 0.0
for i in range(k):
if actual in predicted[:i+1]: # 제출한 값이 K번째 만에 정답
return 1.0 / len(predicted[:i+1]) # score정답이 'A' 인 데이터가 있다고 할 때, 모델이 3개의 값을 예측할 경우 AP@K점수가 어떤 값이 나오는지 확인해 보겠습니다.
actual ='A'
predicted = ['A','B','C']
apk(actual,predicted, 3)예측한 값 중 첫 번째 인덱스의 값인 'A'가 정답과 같으므로 점수는 1.0으로 가장 높습니다.
predicted = ['B','A','C']
apk(actual,predicted, 3)두 번째 인덱스의 값이 정답과 같을 경우 점수는 0.5 입니다.
predicted = ['B','C','A']
apk(actual,predicted, 3)세 번째 인덱스의 값이 정답과 같을 경우 점수는 0.33입니다.
predicted = ['B','C','D']
apk(actual,predicted, 3)예측한 3개의 값 모두 정답이 아닐 경우에 점수는 0.0입니다.
대회의 평가 지표에 대해 먼저 구현 및 확인하는 이유는 나중에 만들게 될 모델을 검증 셋으로 평가하고, 학습 과정 중에는 조기 정지 및 학습 율 조정에 활용하며, 모델의 출력 값을 후처리 및 앙상블 하는 데 활용, 최종 대회 제출을 선택할 때에도 활용하기 때문입니다. 해당 글에서 작성한 전체 코드는 다음 캐글 노트북 링크에서 다운로드 받을 수 있습니다.
1. 전체 학습 코드 설명 : https://www.kaggle.com/ttagu99/train-model
2. 1개 모델 예측 (금메달 점수) : https://www.kaggle.com/ttagu99/prediction-single-model
3. 4개 모델 앙상블 코드(1등 보다 높은 점수) : https://www.kaggle.com/ttagu99/ensemble-models-2epoch
4개 모델 앙상블 코드의 경우 대회 1등 점수 보다 높은 점수를 얻을 수 있습니다. 대회 때는 24위 점수를 얻을 수 있었지만, 위 코드는 대회 종료 후 코드 정리를 하며 발견한 오류들을 수정하고 다시 학습한 결과입니다. 4개 모델 앙상블이 다소 복잡해 보일 수 있지만, 1등을 한 팀이 공개한 솔루션은 모델을 40여개 학습한 뒤 스태킹 모델을 추가 학습한 것으로, 이 글에서 소개할 솔루션이 구현 및 학습에서 보다 간단합니다.
데이터 탐색적 분석
이 대회에서 제공하는 데이터 중 "sample_submissions.csv"을 먼저 확인하면 예측해야 할 행의 수는 112,199개이며, “key_id” 열이 인덱스 열이고, 예측 값을 "word" 열에 3개 공백으로 구분하여 제출해야 합니다.
한가지 주의해야 할 사항은 레이블 이름 중 "The Eiffel Tower"처럼 여러 단어로 구성된 경우 제출 파일인sample_submission.csv에는 표 1-1과 같이 “_”가 사용 되었고, 학습 데이터인 train_raw.csv, train_simplified.csv 에는 표 1-2와 같이 공백이 사용되었습니다. 때문에 학습 후에 제출 파일을 만들 때에는 “_”로 변환하여 제출해야 합니다.
import pandas as pd
sub_df = pd.read_csv(data_path+'sample_submission.csv')
print("test data 수:",len(sub_df))
sub_df.head()1-1. sample submission 파일 내용
| key_id | word | |
| 0 | 9000003627287620 | The_Eiffel_Tower airplane donut |
| 1 | 9000010688666840 | The_Eiffel_Tower airplane donut |
| 2 | 9000023642890120 | The_Eiffel_Tower airplane donut |
대회에서 제공한 데이터는 raw, simplified 두 종류입니다. country code열은 그림을 그린 사용자의 국가 정보, key_id 열은 인덱스, recognized열은 기존 모델의 인식 여부, timestamp열은 그린 시간입니다.
train_file_path = data_path + 'train_raw/'
eiffel_df = pd.read_csv(train_file_path + 'The Eiffel Tower.csv')
eiffel_df.head()1-2.raw 데이터
| country code |
drawing | key_id | recognized | timestamp | word | |
| 0 | GB | [[[16, 33.507999420166016, 44.75699996948242, ... | 5027286841556990 | TRUE | 2017-03-11 14:47 | The Eiffel Tower |
| 1 | FR | [[[142.64599609375, 141.76100158691406, 141.67... | 5716269791707130 | TRUE | 2017-03-12 22:51 | The Eiffel Tower |
| 2 | GB | [[[559, 560, 556, 549, 542, 532, 520, 509, 494... | 5942899998982140 | TRUE | 2017-03-29 1:12 | The Eiffel Tower |
| 3 | US | [[[151, 160, 173, 195, 224, 254, 287, 320, 355... | 6226163091374080 | TRUE | 2017-03-29 16:48 | The Eiffel Tower |
| 4 | GB | [[[216, 229, 244, 266, 293, 322, 352, 383, 417... | 4889008825958400 | TRUE | 2017-03-04 15:50 | The Eiffel Tower |
train_simple_file_path = data_path + 'train_simplified/'
eiffel_simple_df = pd.read_csv(train_simple_file_path + '\
The Eiffel Tower.csv')
eiffel_simple_df.head()
1-3. simplified 데이터
| country code |
drawing | key_id | recognized | timestamp | word | |
| 0 | GB | [[[0, 22, 37, 64, 255], [218, 220, 227, 228, 2... | 5027286841556990 | TRUE | 2017-03-11 14:47 | The Eiffel Tower |
| 1 | FR | [[[47, 47, 36, 26, 0, 10, 23, 46, 46, 63, 68, ... | 5716269791707130 | TRUE | 2017-03-12 22:51 | The Eiffel Tower |
| 2 | GB | [[[184, 115, 67, 57, 36, 18], [251, 103, 12, 1... | 5942899998982140 | TRUE | 2017-03-29 1:12 | The Eiffel Tower |
| 3 | US | [[[0, 187, 177, 132, 105, 79, 38, 19, 11], [24... | 6226163091374080 | TRUE | 2017-03-29 16:48 | The Eiffel Tower |
| 4 | GB | [[[0, 21, 43, 83, 97, 158, 169, 172], [162, 16... | 4889008825958400 | TRUE | 2017-03-04 15:50 | The Eiffel Tower |
문자열을 파이썬 리스트로 받기 위해 다음 코드처럼 json.loads 함수를 사용했습니다.
import json
raw_images = [json.loads(draw) for draw in eiffel_df.head()\
['drawing'].values]
simple_images = [json.loads(draw) for draw in eiffel_simple_df.head()\
['drawing'].values]
raw 파일의 drawing열 데이터와 simplified파일의 drawing열 데이터를 그려서 비교해 보면 다음과 같은 차이가 있습니다.
import matplotlib.pyplot as plt
for index in range(3):
f, (ax1, ax2) = plt.subplots(ncols=2,nrows=1,figsize=(8,4))
for x,y,t in raw_images[index]:
ax1.plot(x, y, marker='.')
for x,y in simple_images[index]:
ax2.plot(x, y, marker='.')
ax1.set_title('raw drawing')
ax2.set_title('simplified drawing')
ax1.invert_yaxis()
ax2.invert_yaxis()
ax1.legend(range(len(raw_images[index])))
ax2.legend(range(len(simple_images[index])))
plt.show()

위 그림에서 컬러는 획 순입니다. raw는 포인트 수가 많은 반면, simplified는 raw데이터의 포인트에서 같은 방향으로 이동한 부분들을 생략하여 포인트 수가 적습니다. 그 외에도 raw의 X, Y축 범위를 보면 일정하지 않습니다. 그림을 그린 디바이스 창 크기에 따라 좌표가 다르기 때문으로 예상됩니다. simplified drawing열은 256×256으로 전 처리 되어있습니다. 또한, 다음과 같이 raw 데이터에는 시간 정보가 있으며, 공식적으로 명시하지는 않았지만 m-sec 단위로 추측됩니다.
print("======== 첫 번째 raw drawing의 첫 획 Data 중 5개 Point 정보 \
=========")
print("x좌표: ", json.loads(eiffel_df['drawing'][0])[0][0][:5])
print("y좌표: ", json.loads(eiffel_df['drawing'][0])[0][1][:5])
print("m-sec: ", json.loads(eiffel_df['drawing'][0])[0][2][:5])
print("======== 첫 번째 Simplified drawing의 첫 획 Data 중 5개 Point 정보 \
=========")
print("x좌표: ", json.loads(eiffel_simple_df['drawing'][0])[0][0][:5])
print("y좌표: ", json.loads(eiffel_simple_df['drawing'][0])[0][1][:5])
< 실행결과 >
======== 첫 번째 raw drawing의 첫 획 Data 중 5개 Point 정보 =========
x좌표: [16, 33.507999420166016, 44.75699996948242, 52.5620002746582, 58.189998626708984]
y좌표: [350, 351.0889892578125, 353.135009765625, 355.37799072265625, 359.0950012207031]
m-sec: [0, 73, 89, 105, 123]
======== 첫 번째 Simplified drawing의 첫 획 Data 중 5개 Point 정보 =========
x좌표: [0, 22, 37, 64, 255]
y좌표: [218, 220, 227, 228, 211]
</ 실행결과 >
데이터 취급 및 쉬운 모델 작성을 위해서는 simplified 데이터를 사용해도 무방하겠지만, 메달권 점수를 얻는 것이 목표였음으로, 정보가 많은 raw 데이터를 사용하였습니다.
'AI to the Real World > 캐글 탐험대' 카테고리의 다른 글
| 🥈은메달 수상기 (2) OTTO 추천시스템 대회: 챌린지와 우리의 솔루션 (0) | 2023.03.13 |
|---|---|
| 🥈은메달 수상기 (1) OTTO 추천시스템 대회 A to Z (0) | 2023.02.16 |
| [캐글탐험대] Happy Whale 대회 (0) | 2022.05.19 |
| [캐글탐험대] PetFinder 대회 (2편) (0) | 2022.04.26 |
| [캐글탐험대] PetFinder 대회 (1편) (0) | 2022.04.26 |