안녕하세요. 마인즈앤컴퍼니입니다.
마인즈앤컴퍼니 AI CONNECT 부서에서는 중소벤처기업진흥공단이 주관하는 [스타트업 청년인재 이어드림] 프로젝트에 참여하고 있습니다. AI CONNECT는 AI 경진대회를 주관하는 부서인데요! 풍부한 AI 경진대회 수행 경험을 기반으로 모의 경진대회와 실전 경진대회를 담당하여 교육과 멘토링을 지원합니다.
작년 (2021년) 진행된 이어드림에서도 Kaggle 경진대회에 출전한 입교생들에게 특강과 멘토링을 지원해주었습니다.
그 중 은메달을 수상한 팀의 팀원이 마인즈앤컴퍼니에 입사하게 되었는데요! Data Scientist 로 입사하신 이남주, 김준철 매니저가 Happy Whale 대회 은메달 수상후기와 Insight를 작성해서 공유해주셨습니다. Kaggle 대회 준비하시는 분들에게 도움이 되었으면 좋겠습니다.

Task Description
얼굴이나 지문으로 사람을 판별하는 방법이 많이 상용화 되었지만 동물에 대해서는 접근성이 낮다는 이유로 미루어져 왔습니다. 하지만! 돌고래와 고래의 행동 패턴을 연구하는 국제 기관에서는 관리하는 돌고래와 고래를 빠르게 확인하고 체계적으로 관리하는 것이 필요해졌습니다. 이번 대회에서는 위 기관들의 연구에 도움을 주는 대회라고 이해하면 편할 것 같습니다!
이번 대회는 26가지의 종에 해당하는 약 15000가지의 개체를 분류해야 했습니다. 멀리는 1980년대의 과거에 찍은 사진부터 현재까지 찍은 사진들이 섞여 있었기 때문에 시간이 지날 때마다 바뀌는 고래의 피부 색이나 상처에 대해서 robust한 모델을 만드는 것이 중요한 포인트였습니다. 거기에서 끝나지 않고 기관에서 관리하지 않는 새로운 개체를 판단 할 수 있는 모델을 개발하는 문제도 동시에 존재 했습니다.

Train 데이터로는 51033 장의 이미지가 존재하며 Test 데이터로는 27956 장의 이미지가 존재합니다. Public 기준 Test데이터의 11% 는 처음 보는 새로운 개체입니다.
처음보는 객체에 대해서 새로운 객체라고 판단을 해야하는 문제를 Open Set Classification 이라고 부르는데요. 약 15000가지의 개체를 분류하는 것도 어려운데 추가적으로 새로운 개체까지 판단하는 모델을 만들 수 있을까요?
일반적으로 처음보는 개체를 새로운 개체로 판단하는 연구분야는 Metric Learning 을 기반으로 진행되고 있습니다.
Metric Learning 이란?
우선 Metric Learning은 Softmax based method 과 Contrastive based method 두 가지 범주로 나누어 볼 수 있습니다. 이번 대회에는 각 클래스마다 명확하게 나누어지도록 도와주는 Softmax based method를 선택하게 되었습니다.

Softmax based method 중에서 이번 대회에 적용된 학습 방식은 얼굴인식 분야에서 SOTA 수준의 좋은 성능을 보이는 ArcFace를 통한 학습법입니다. ArcFace는 모든 이미지 embedding vector가 n차원의 Sphere에 존재한다고 가정하고 클래스마다 더 명확한 군집화를 만들어 내는 것을 목표로 학습됩니다.
왜 Open Set Classification 에서 ArcFace를 쓸까?
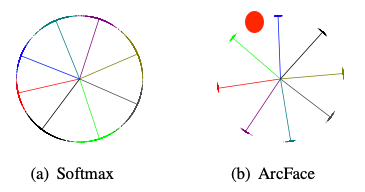
우선 모두에게 익숙한 Naive Softmax 학습방법은 각각의 클래스에 맞춘 확률분포를 만드는 방식입니다. 이를 그림으로 표현하면 왼쪽 위의 그림처럼 나옵니다. 여기에 embedding 벡터 사이의 거리(distance) 개념을 추가하여 같은 클래스끼리 가까워지도록 학습한다면 오른쪽 위 그림처럼 모든 학습된 클래스와 먼 경우에는 새로운 개체라고 인식 할 수 있는 모델이 만들어질 수 있게 됩니다.
이제 학습방법이 결정이 되었기 때문에 원래 연구되었던 실험 환경과 비슷하게 맞추는 것이 중요한데요. ArcFace 논문에서는 아래와 같은 과정을 통해 학습이 진행 됩니다.

결국 실험 환경을 동일하게 세팅하기 위해 주요 Feature 부분만 남기는 Detection과 feature의 일관성을 높여줄 Alignment 가 남았습니다. 아래 그림을 보시면 고래마다 다른위치와 배경이 크게 다르기 때문에 필요한 부분만 Detection을 해주는 것이 필수적으로 보이고 Detection이 잘된다면 Alignment도 성공적으로 이루어 질 수 있는 데이터로 보입니다.


결국 일반적인 캐글 대회와 달리 이번 대회는 데이터 구축이 가장 중요한 주제가 되었습니다. DS 분야의 연구자들이 쉽게 중요성을 간과할 수 있는 데이터를 강조한 대회였기 때문에 더 재밌게 참여할 수 있게 된 것 같습니다.
그렇다면 어떤 식으로 데이터를 구축하는 것이 가장 좋은 방법일까요?
Dataset Building
저희는 Binary Class Detection에서 좋은 성능을 보이는 Yolov5 모델을 활용한 dorsal fin detection 모델을 구축하였습니다. Yolov5 모델은 특히 적은 클래스가 존재할 때 성능이 좋다고 알려져있기 때문에 핀의 여부만 찾는 Binary Detection 에 쓰기 적합하다고 생각했습니다. 실제로 최근에 열린 kaggle의 Binary Detection 대회에서 1-stage model SOTA인 YoloR이나 YoloX를 제치고 Yolov5 모델이 1등 솔루션을 차지하기도 했습니다.
(혹시 자세히 알고싶으시면 Reef Detection Kaggle Competition 를 참고해주세요.)
최종적으로 Yolov5-s 모델과 Yolov5-m 모델, Yolov5-m tta inference 세 가지 결과의 IOU가 0.7 이하 인 것은 직접 Annotation하는 방식으로 구성하였습니다. (위 filtering 결과 99.1 % 는 모델이 구축하게 되었고 0.9 % 내외의 데이터는 직접 Annotation하였습니다.)
결과적으로 얻게 된 데이터는 아래와 같습니다. 중요한 Feature 들만 남아있는 데이터가 구축되었습니다!
Train Sample

▼
Detecting Images

Inference Strategy
이번 대회에서 데이터와 모델링만큼 중요한 것이 추론 방법이었습니다. 왜냐하면 정답을 한 가지만 맞추는 Accuracy와 달리 Ranking을 고려하여 5가지를 후보군을 내야하는 Metric 때문인데요.

위의 메트릭을 보면 가능성이 높은 5가지의의 후보군을 제안하고 맞추는 순간에 점수를 차등지급하는 방식입니다. 물론 새로운 개체는 ‘new_individual’ 로 추론해야 합니다. 첫번째에 맞춘다면 1.0 두번째에는 0.5 ( 1/2 ) 세번째는 0.33 ( 1/3 ) ..방식으로 5 번째까지 점수가 부여되는 Metric입니다.
결국 Metric learning에서는 embedding vector의 distance를 기준으로 학습이 되기 때문에 K-NearestNeighbor을 활용하여 해당 train image와 cosine distance가 가까운 순서로 ranking을 부여하는 방식으로 진행합니다. 추가적으로 threshold를 계산하여 모든 클래스에 대해서 먼 데이터는 new individual로 추론합니다.
시각화 & 아이디어
TSNE by Species
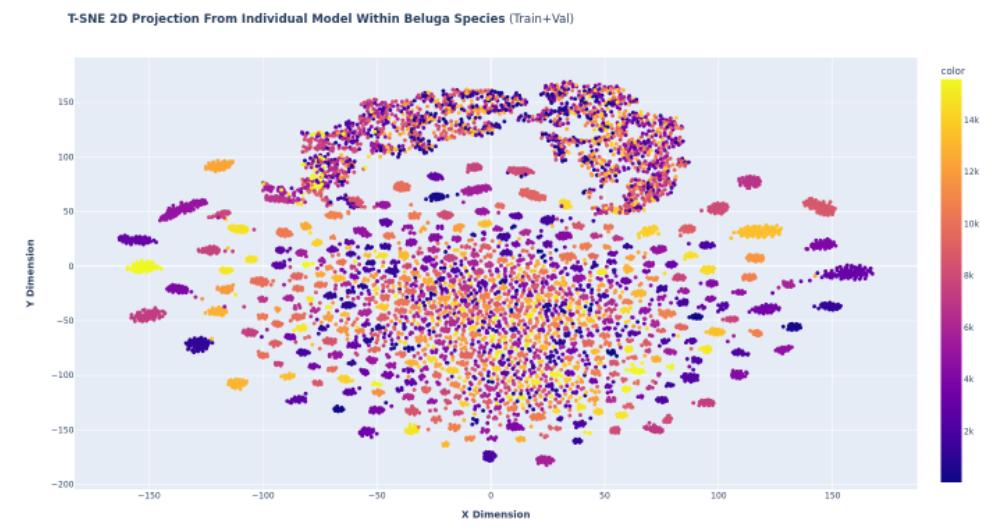
아래 나온 그림처럼 종마다 각 개체의 분포가 크게 상이한 점을 활용하여 종에 new individual을 판단하는 threshold 값을 종마다 다르게 주어야 한다는 아이디어를 얻게 되었고 실제로 이 아이디어를 적용하여 점수를 향상할 수 있었습니다.

Generalization
대회 막바지에 도착하면서 어떤 식으로 일반화에 대한 근거를 확보 할지에 대한 토의를 많이 하였고 아래그림과 같은 TSNE 시각화를 보며 Train과 Test의 분포가 닮았다는 것을 확인하였으며 validation의 분포에 맞춘 추론 전략을 그대로 적용할 수 있었습니다.
Image Embedding TSNE Visualization

Discussion and Winning Solutions
마지막으로 상위 솔루션들과 다른 두 가지 차이점에 대한 이야기 입니다.
1. Pseudo-Labeling: effective on data imbalance
수도라벨링은 Metric Learning에서 높은 confidence값 만을 가져오기 때문에 성능에 큰 영향을 주지 않을 것이라 생각하여 모델 앙상블에 시간을 집중했는데 수도라벨링이 매우 큰 점수 차이를 가져 온 것이 아쉬웠습니다.
상위 솔루션을 가진 분들은 Data Imbalance가 너무 심했기 때문에 성능에 큰 향상을 가져왔다고 판단하였습니다.
2. Ensemble Two Different Datasets: Fin and FulDectection Dataset
가장 생소하게 느껴졌던 방식이었던 만큼 신기하게 받아들였던 데이터 셋 앙상블입니다. 지느러미에 대한 데이터와 전체 몸통에 대한 데이터 모두 시도해 본 데이터 셋이었지만 저희 팀은 최고 데이터만 남겨 학습을 진행했습니다. 두 가지 방식의 데이터의 앙상블이 중요한 포인트가 되는지 몰랐던 점이 큰 차이를 가져오게 되었습니다. 이 부분은 현업에서도 쉽게 적용 할 수 있는 방식이라 나중에 쓸 수 있는 기회가 생길 것이라 생각됩니다.
Summary
- Open Set Dataset의 경우에 Metric Learning을 기반으로 접근 할 수 있다.
- Ranking 에 관련된 Metric일 경우에 Distance 기반의 학습방법이나 KNN을 활용 할 수 있다.
- 데이터는 언제나 모델의 성능을 향상시키는 가장 중요한 Key가 된다.
딥러닝 모델링의 고도화나 다양한 논문을 구축하는 대회라기보다는 데이터 기반의 고민을 많이 적용 할 수 있는 대회였기 때문에 토의 할 부분도 많았고 이 덕분에 재밌게 진행 할 수 있었습니다.
대회를 진행하다보면 데이터보다 모델 고도화가 더 중요하게 느껴질 수 있는데 데이터가 가장 중요하다는 생각을 환기 시킬 수 있는 대회였기 때문에 느낀 바가 많았습니다. 데이터 셋을 나누어 앙상블을 하는 법까지 배울 수 있어 데이터도 하나의 중요한 하이퍼 파라미터로 생각될 것 같습니다.
결과를 마주하고나서 할 수 있는 방법론은 무조건 다 해야 한다는 점을 다시 한 번 느낄 수 있었습니다. 그러려면 시간을 조금 더 효율적으로 쓰고 코드도 더 빠르게 동작하도록 짜야합니다. 다음 나아가야 하는 방향을 잡아준 이번 대회에서 여러모로 배운 것들을 기록하고 마칩니다. 다음에도 봅시다!
'AI to the Real World > 캐글 탐험대' 카테고리의 다른 글
| 🥈은메달 수상기 (2) OTTO 추천시스템 대회: 챌린지와 우리의 솔루션 (0) | 2023.03.13 |
|---|---|
| 🥈은메달 수상기 (1) OTTO 추천시스템 대회 A to Z (0) | 2023.02.16 |
| [Kaggle] Doodle Recognition Challenge Insight-1 (0) | 2022.05.19 |
| [캐글탐험대] PetFinder 대회 (2편) (0) | 2022.04.26 |
| [캐글탐험대] PetFinder 대회 (1편) (0) | 2022.04.26 |