안녕하세요. 마인즈앤컴퍼니 (이하 MNC) 입니다. :-) MNC의 새로운 'RL' 시리즈를 소개드립니다.
테크리더 명대우 파트너님의 지도 아래, MNC 의 Data scientist 인 최창윤 매니저가 뜻을 모아 강화학습에 대해 연구를 진행하고 있습니다.
몇년 전부터 강화학습에 대한 공부를 해왔지만 내용을 정리하지 않아 다시 공부하는 경우가 많았는데요!
이번 연구를 진행하면서 정리할 필요성을 느꼈고, 해당 내용들을 블로그에 공유드리기로 하였습니다.
연구 배경
해당 연구는 딥러닝 비전 검사 기술을 로봇 팔과 접목하여 실제 산업에 적용하기 위해 진행하게 되었습니다. 바닥과 닿아있는 부분이나 복잡한 물체는 카메라로 촬영할 수 없는 영역이 존재하고 이러한 상황에서도 제품을 효과적으로 검사하기 위해 그리퍼가 달린 로봇 팔을 강화학습으로 제어하는 것입니다.
※ 2015년 DeepMind의 David Silver 가 강의한 강화학습 내용을 바탕으로 정리하였습니다. David Silver의 강의 내용을 최대한 담고 그 이외에도 여러가지 보충 자료들을 추가할 생각입니다. 그로인해 조금 어렵게 느껴질 수 있지만 이론 뿐 아니라 중간중간에 코드를 이용한 실습을 포함하여 강화학습 내용을 보다 쉽게 이해할 수 있게 작성하는 것을 목표로 하였습니다.
강화학습이란?
자연적인 학습에 대해 생각해보면 우리는 주변의 환경과 상호작용을 통해 학습합니다. 태어난지 얼마 안된 애기가 명시적인 가르침 없이 팔을 흔들거나 움직이는 사물을 보고 시선을 고정할 수 있는 것은 주변의 환경을 인식하고 몸을 제어할 수 있기 때문이죠. 이렇듯, 모든 Learning, Intelligence와 같은 이론의 근본적인 아이디어는 상호작용을 통한 학습에서 유래되었습니다. 이 중 우리가 학습할 강화학습은 목표 지향(goal-directed learning)에 초점을 둔 학습 방법입니다.
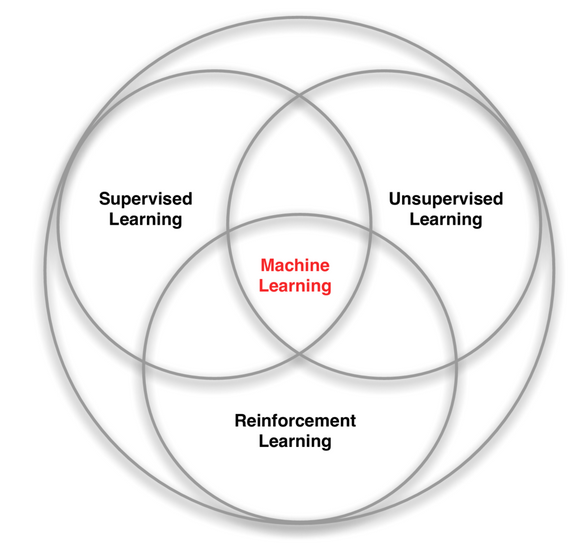
강화학습은 Machine Learning의 한 종류로, 행동을 수행하는 학습자가 어떤 행동을 해야하는 지 알지 못하는 상태에서 행동에 대한 보상을 극대화하기 위해 어떻게 행동해야 할 지 방향을 찾는 학습 방법입니다.
Wikipedia에서는 강화학습을 다음과 같이 정의하고 있습니다.
Reinforcement learning is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward.
강화학습의 특징
데이터에 대한 라벨의 여부로 분류되는Supervised/Unsupervised Learning과는 다르게, Reinforcement Learning은 그 자체의 독특한 특징들을 가지고 있습니다.
대표적인 특징 두 가지를 살펴보자면,
Trial and Error
강화학습은 어떤 Action을 해야 하는 지 전달받지 않고 많은 시도와 실패를 통해 가장 높은 Reward를 받을 수 있는 Action을 발견합니다.
Delayed Reward
Reward Signal은 객체 (Agent)가 수행한 행동(Action)을 평가하는 값인데, 특정 행동에 대한 Reward Feedback이 시간적으로 지연될 수 있으며 즉각적이지 않습니다. 즉, 지금 한 행동의 보상이 어느 시점의 미래에 돌아올 지 모르는 것이죠.
강화학습 문제의 예시

출처: https://www.youtube.com/watch?v=tF4DML7FIWk
보행 로봇 연구 개발로 유명한 Boston Dynamics 는 다양한 상황에서 사람의 보행을 그대로 따라할 수 있는 로봇을 만들었습니다. 이 로봇은 단순히 걷기라는 하나의 동작만을 수행한다고 가정해도 다양한 환경에 놓여질 수 있으며, 상황에 따라 걷는 방식이 달라져야 합니다. 길의 경사가 갑작스럽게 변화하면 경사에 따라 걷는 자세를 변경해야 하며, 계단이 앞에 있으면 계단의 높이를 인식하고 올라가야 합니다.
이러한 문제를 Supervised Learning과 Unsupervised Learning으로 해결하려고 하면 라벨은 어떻게 정의해야 할 지, 걷는다는 연속적인 행위를 어느 단위에서 끊어서 하나의 데이터로 만드는 것이 좋을 지 정하기가 어렵습니다.
그러면 강화학습으로 풀 수 있는 문제는 무엇이 있을까요?
강화학습으로 풀린 대표적인 예시들은 딥마인드의 알파고 (바둑)와 보스턴 다이내믹스의 아틀라스 (보행), DQN 논문에서 수행한 Atari 게임 (벽돌깨기) 등이 있습니다. David Silver의 강의에서는 강화학습의 예시를 다음과 같이 나열하였습니다.
- Fly stunt manoeuvres in a helicopter
- Defeat the world champion at Backgammon
- Manage an investment portfolio
- Control a power station
- Make a humanoid robot walk
- Play many different Atari games better than humans
강화학습의 구성요소
강화학습은 Agent가 주어진 Environment에서 누적된 Cumulative Reward를 최대화하기 위한 Action을 하는 것입니다. 다시 말해, 어떤 문제를 강화학습으로 풀기 위해서는 Agent, Environment, Reward를 정의할 수 있어야 합니다.
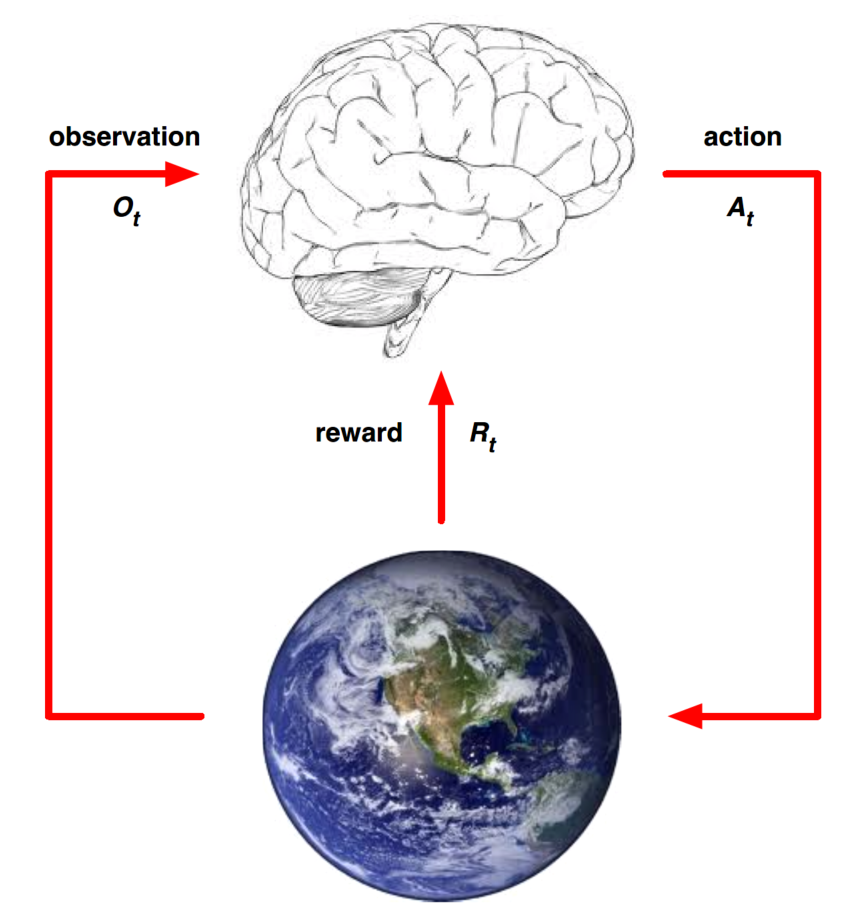
강화학습의 구조를 나타낸 것으로 뇌는 Agent, 지구는 Environment를 의미합니다. Agent가 어떤 Action을 Environment 에게 전달하면 Environment는 뇌에게 다시 Observation과 Reward를 전달합니다. 간단히 말해서 뇌는 주어진 환경에서 다양한 경험을 수행하며 행동에 대해 받는 피드백으로 학습하는 과정입니다.
강화학습의 개념과 강화학습 프로세스가 진행되면서 Agent와 Environment 간의 상호작용이 어떤 방식으로 이루어지는지 간략히 살펴보았습니다.
다음 포스팅에서는 Agent와 Environment, Reward과 강화학습에 필요한 다른 개념들을 살펴보겠습니다.
참고자료
- Sutton http://incompleteideas.net/book/RLbook2020.pdf
- David Silver https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ
마인즈앤컴퍼니는 적극 인재 채용 중입니다. 많은 관심과 지원 바랍니다.
마인즈앤컴퍼니
Make the Most of AI
mnc.ai
'AI Study > 강화학습' 카테고리의 다른 글
| [RL] 2-2. Exploration과 Exploitation: Greedy Method vs. Epsilon-greedy Method (0) | 2022.09.14 |
|---|---|
| [RL] 2-1. Exploration과 Exploitation: Multi-armed Bandit Problem (0) | 2022.07.15 |
| [RL] 1-2. 강화학습의 구성 요소 (0) | 2022.04.28 |