2022.04.26 - [[스터디] 강화학습] - [RL] 1-1. 강화학습이란?
[RL] 1-1. 강화학습이란?
안녕하세요. 마인즈앤컴퍼니 (이하 MNC) 입니다. :-) MNC의 새로운 'RL' 시리즈를 소개드립니다. 테크리더 명대우 파트너님의 지도 아래, MNC 의 Data scientist 인 최창윤 매니저가 뜻을 모아 강화학습에
blog.mnc.ai
2022.04.28 - [[스터디] 강화학습] - [RL] 1-2. 강화학습의 구성 요소
[RL] 1-2. 강화학습의 구성 요소
이전 포스팅에서 Agent가 Action을 수행했을 때 Environment와의 상호작용을 통해 Agent가 학습한다고 배웠습니다. Agent와 Environment, Action 에 대해 구체적이지는 않지만 간단한 개념을 이해하고 계실텐데
blog.mnc.ai
이전 포스팅에서 Agent가 Action을 수행했을 때 Environment와의 상호작용을 통해 Agent가 학습한다고 배웠습니다. Agent와 Environment, Action 에 대해 구체적이지는 않지만 간단한 개념을 이해하고 계실텐데 앞의 두 포스팅에서는 강화학습의 개념을 이해하고, 강화학습을 구성하는 필수 요소들에 대해 대략적으로 알아봤습니다. 앞에서 나온 모든 개념들을 복잡한 문제에 적용하기 전에, 간단한 문제에 적용하는 것에서 시작하겠습니다.
본 포스팅부터는 강화학습 분야에서 오랜 기간동안 연구되어 온 Multi-armed Bandit 문제를 기반으로 Exploration과 Exploitation에 대해 살펴보려고 합니다. 대부분의 내용은 Sutton의 강화학습 책을 주로 참고하였습니다.
Multi-armed Bandit Problem

Multi-armed Bandit Problem을 설명하기 위해 보통 카지노의 슬롯머신을 예로 듭니다. 한 강도(Bandit)가 카지노에 침입하여 K 개의 슬롯머신(K-armed)을 경찰이 도착하기 전까지 제한된 시간동안 작동시킬 수 있다고 합시다. 이 슬롯 머신들은 잭팟이 터질 확률이 모두 다르다고 했을 때, 어느 슬롯머신을 사용하는 것이 가장 많은 수익을 얻을 수 있을까요? K-armed Bandit Problem 이라고도 불리는 이 문제는 이와같이 1개의 State와 K 개의 Action을 가진 상황에서 어떠한 Action을 취하는 것이 가장 좋을 것인지를 푸는 모든 문제를 말합니다.
K-armed Bandit Problem은 단 하나의 State만을 갖고 있기 때문에 State transition을 고려해야 하는 다양한 State를 가진 문제보다 단순합니다. 이로 인해 K-armed Bandit Problem이 현실적인 문제에서 적용 불가능하다고 의문점을 가질 수 있을 것 같습니다.
하지만 이러한 유형의 문제는 강화학습에서 가장 기본이 되는 문제이자, 실제로도 사용되고 있습니다. 예를 들어 심각한 병에 걸린 환자에게 의사가 치료법을 적용할 때, 어떤 치료법을 적용할 지 선택하거나, 특정 고객에게 어떤 광고를 띄울 지 선택하는 문제에서 사용될 수 있습니다.
Exploration과 Exploitation
다시 K-armed bandit problem 상황으로 돌아가서, 어떤 슬롯머신을 작동시키는 것이 가장 높은 수익을 낼 수 있을까요? 모든 슬롯 머신들을 무한히 작동시켜서 경험적인 실험을 해보는 것이 가장 이상적이겠지만, 제한된 시간이 존재하기 때문에 현실적인 방법은 아닙니다. 처음에 강도는 사용해본 슬롯머신이 없기 때문에 랜덤으로 하나를 선택할 것입니다.
우연히도 처음 돌려본 슬롯머신에서 잭팟이 터진다면 그 슬롯머신이 가장 좋다는 선입견에 모든 시도 횟수를 하나의 슬롯머신에 투자할 수 있겠지만, 다른 슬롯머신의 잭팟 확률이 더 높을지는 알 수 없습니다. 강도는 다음과 같은 의문점에 빠질 것입니다.
하나의 슬롯머신만 계속 돌리는 것이 좋을까요? 아니면 다른 슬롯머신들도 테스트해보는 것이 좋을까요? 만약 다른 머신을 테스트한다면 강도가 사용할 수 있는 시간 중 어느정도를 투자하는 것이 좋을까요?
이러한 질문에서 나온 것이 바로 Exploitation과 Exploration 입니다. Exploitation은 기존에 시도했던 방법들 중 가장 좋다고 평가한 방법을 Action으로 취하는 것이고, Exploration은 좋다고 평가한 것과 상관없는 행동을 하는 것이죠.
특정 순간에는 Exploitation을 하는 것이 가장 좋겠지만, 현재 가장 좋다고 생각하는 행동보다 더 좋은 행동이 있을 수 있기 때문에 장기적인 관점에서 보았을 때는 Exploration이 필수적입니다. Exploration과 Exploitation은 어느 정도의 비율로 정하는 것이 가장 좋을지에 대한 의문점이 생길 수 있으나, 아쉽게도 이 문제에 대한 명확한 답은 없습니다.
10-armed Testbed
명확한 정답이 없더라도, 문제에 Exploration과 Exploitation을 다양하게 적용해 보는것으로 간단한 감을 잡을 수는 있을 것입니다. 또한, Exploration과 Exploitation에 대한 여러 알고리즘들의 장단점에 대해서도 알아볼 수 있습니다. 여기서는 Sutton 의 책에서 소개된 10-armed Testbed의 Environment를 구현하고, 이후 포스팅에서 다양한 알고리즘을 실험해볼 예정입니다. 전체 코드는 Github를 참고해주세요.
Environment 의 구현
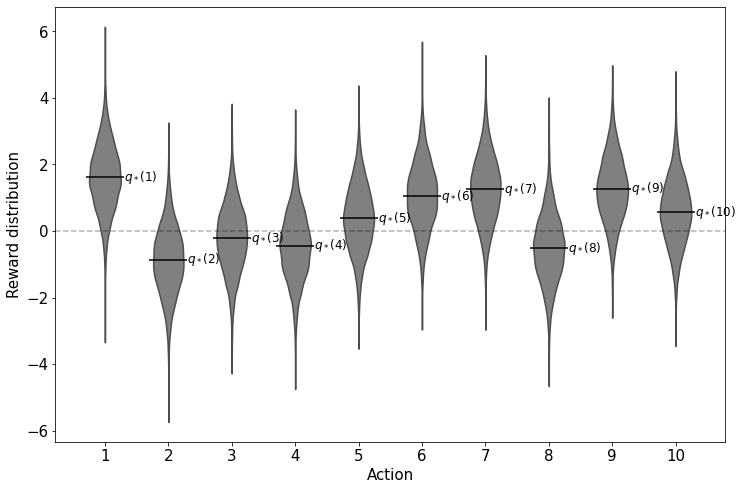
본 Testbed에서는 10개의 슬롯머신이 있을 때 Greedy method와 $\epsilon$-greedy method 의 성능을 확인해봅니다. 여기서 Optimal value $(q_*)$가 $N(0, 1)$ 인 정규분포를 따른다고 가정합니다. 이 분포로부터 각 슬롯머신의 실제 Value 값이 추출됩니다. 그리고 각 슬롯머신을 작동시키면 $N(q_*(a), 1)$인 분포를 따르는 Reward를 반환합니다. 아래의 그림은 각 슬롯머신(Action) 당 Reward의 분포를 그린 것입니다.
class Env():
def __init__(self, n_action):
self.n_action = n_action
self.init_optimal_q_value()
def init_optimal_q_value(self):
# 실제 Optimal q value 생성
self.optimal_q_value_list = [np.random.normal(loc = 0, scale = 1) for i in range(self.n_action)]
def get_reward(self, action:int):
# reward distribution 생성
return np.random.normal(loc = self.optimal_q_value_list[action], scale = 1)
def sampling_random_reward(self, n):
data_list = []
for iter in range(n):
data_list.extend([[i+1, self.get_reward(i)] for i in range(self.n_action)])
return pd.DataFrame(data_list, columns=['x', 'reward'])Action을 취했을 때 Reward를 랜덤으로 추출하는 것은 Environment의 역할이므로, Env class를 위와 같이 구현하였습니다. init_optimal_q_value 는 슬롯머신들의 Optimal Value 값을 랜덤하게 추출하는 역할을 합니다. get_reward 는 특정 action을 입력으로 받아서 해당하는 action의 Reward를 반환합니다. sampling_random_reward는 각 action으로부터 n개의 reward를 sampling한 결과를 DataFrame 형태로 반환합니다.
Reference
http://incompleteideas.net/book/RLbook2020.pdf
https://en.wikipedia.org/wiki/Multi-armed_bandit
Multi-armed bandit - Wikipedia
Machine Learning A row of slot machines in Las Vegas In probability theory and machine learning, the multi-armed bandit problem (sometimes called the K-[1] or N-armed bandit problem[2]) is a problem in which a fixed limited set of resources must be allocat
en.wikipedia.org
'AI Study > 강화학습' 카테고리의 다른 글
| [RL] 2-2. Exploration과 Exploitation: Greedy Method vs. Epsilon-greedy Method (0) | 2022.09.14 |
|---|---|
| [RL] 1-2. 강화학습의 구성 요소 (0) | 2022.04.28 |
| [RL] 1-1. 강화학습이란? (0) | 2022.04.26 |