안녕하세요. 마인즈앤컴퍼니의 AI 경진대회 플랫폼 ‘AI CONNECT’를 운영하는 AI 커넥트팀입니다.
저희 팀의 데이터사이언티스트들이 Kaggle에서 개최된 OTTO - Multi-Objective Recommender System 경진대회에서 2,587 팀 중 128등이라는 기록을 내며 은메달을 차지했다는 소식, 지난 번 첫번째 수상기 글을 통해 알려드렸습니다. 이번에는 OTTO 대회가 어떤 챌린지가 있었는지, 그리고 그 챌린지를 어떻게 풀어냈는지에 대해 두 번째 글로 소개해드립니다.
작성: 마인즈앤컴퍼니 Data Scientist 곽치영 매니저 (AI커넥트사업부)
마인즈앤컴퍼니 전혜령 인턴 (연세대 응용통계학 19)
검수: 마인즈앤컴퍼니 Data Scientist 박기돈 매니저 (AI커넥트사업부)
OTTO, 이 대회의 챌린지는?
앞선 포스팅에서 소개한 바와 같이 OTTO 추천 시스템 대회는 약 1,200만 명에 달하는 사용자의 과거 데이터를 기반으로 180만 종류가 넘는 상품 중 사용자가 관심 있어 할 만한 상품을 추천해야 하는 문제였습니다. 이러한 대규모 추천 시스템을 개발하는 과정에서 메모리 이슈와 속도 이슈는 주요한 챌린지였습니다. 이를 어떻게 해결했는지에 대해 소개하도록 하겠습니다.
Memory Management
전처리 과정에서, 피처를 추가한 데이터프레임을 메모리에 로딩하는데만 40GB 이상의 메모리를 차지하게 됩니다. 이 경우 속도 저하 문제 뿐만 아니라 groupby, merge 등의 연산을 수행할 때 메모리 문제로 인해 커널이 중단되는 등의 문제가 발생하였습니다. 이러한 문제를 최소화하기 위해 데이터 용량을 줄이고자 다음 두 가지 방법을 시도하였습니다.
(1)Data Type 변경
데이터 타입을 명시하지 않으면 컬럼 값은 일반적으로 int64나 float64로 자동 지정됩니다. 그러나 대부분의 피처는 그렇게 넓은 표현 범위를 필요로 하지 않기 때문에 더 작은 범위의 dtype으로 변경하여 메모리 사용량을 줄일 수 있었습니다.
df[col] = df[col].astype('int32')
(2) chunk로 분리
하지만 dtype 변경만으로는 메모리 문제를 완전히 해결할 수 없었습니다. 이에 데이터를 chunk 단위로 분할하여 각각의 chunk 별로 결과를 생성한 후에 concat 하는 식으로 진행하였습니다.
CHUNKS = 10
chunk_size = np.ceil( len(candidates) / CHUNKS)
for k in range(CHUNKS):
df = candidates.iloc[k*chunk_size:(k+1)*chunk_size].copy()
df = df.merge(item_features, left_on='aid', right_index=True, how='left').fillna(-1)
df = df.merge(user_features, left_on='session', right_index=True, how='left').fillna(-1)
df.to_parquet(f'candidate_with_features_p{k}.pqt')
Speed
테이블 데이터 분석에 주로 활용하는 Pandas 라이브러리는 데이터를 메모리에 적재한 후 연산하는 방식으로 작동하기 때문에 메모리 부족 문제가 자주 발생합니다. 또한, 단일 코어를 사용하기 때문에 처리 속도가 느린 문제점도 있습니다. 이런 문제를 해결하기 위해 사용할 수 있는 몇 가지 주요 라이브러리를 소개하겠습니다.
(1) Dask
Dask는 데이터를 가상 데이터프레임으로 형성하여 연산하는 라이브러리입니다. 데이터를 파티션으로 분할하여 메모리에 순차적으로 로딩하고 내리면서 연산하므로 가용 메모리보다 큰 데이터 처리도 가능합니다. 또한, 병렬 처리를 지원하여 여러 CPU 코어를 사용할 수 있어 처리 속도가 빠르고, 멀티 GPU를 사용하기 유용하며 Pandas와 유사한 문법을 가지고 있다는 것이 장점입니다.
(2) CuDF
CuDF는 RAPIDS에서 개발한 GPU 기반 데이터프레임 라이브러리입니다. CUDA를 기반으로 하며, 이전에는 CPU에서 데이터 전처리를 하고, 처리된 데이터를 GPU로 복사하여 학습을 진행했던 방식과 달리, 전체 프로세스를 GPU 상에서 처리할 수 있게 해주는 라이브러리입니다. Dask와 마찬가지로 CuDF의 역시 Pandas와 거의 동일한 문법을 사용하기 때문에 활용하기 쉬운 편입니다. 다만, CuDF로 멀티 GPU를 활용하기 위해서는 Dask와 함께 활용해야 합니다.
(3) Polars
Polars는 Dask와 마찬가지로 CPU 병렬 처리를 지원하는 라이브러리입니다. Dask는 Pandas 라이브러리를 기반으로 구축되어 있지만, Polars는 Pandas와 독립적인 라이브러리로 병렬화 기능뿐만 아니라 전체 쿼리 계획을 미리 그래프로 그린 뒤, 같은 기능을 하는 쿼리로 최적화하여 처리 속도를 매우 빠르게 만들어주는 장점이 있습니다. 다만, Pandas와 문법이 다소 달라 앞서 소개한 두 라이브러리에 비해 활용이 어렵다는 점이 있습니다.
우리의 솔루션을 소개합니다
Multi-stage Recommender System (Candidates generation + Re-Ranking)
시스템 컨셉
거대 인터넷 플랫폼이 등장함에 따라 수 백만명 이상의 사용자에게 수 천만 개 이상의 아이템 중에서 소비할만한 아이템을 추천하는 것은 상당한 자원을 필요로합니다. 특히, 딥러닝 모델과 같이 많은 연산이 필요한 기술을 사용하여, 각 사용자 별로 수 천만 개의 아이템에 대한 선호도를 계산한다면 응답 시간 지연은 더욱 커지게됩니다. 아마존 연구에 따르면 0.1초의 페이지 로딩 지연이 약 1%의 매출 감소로 이어진다고 할 정도로 추천 속도는 중요한 문제입니다. 이 문제를 해결하기 위해, 유튜브, 넷플릭스, 아마존과 같은 거대 플랫폼에서는 Multi-Stage 추천 시스템[1,2]을 주로 활용하여 추천 성능을 향상시키고 있습니다.
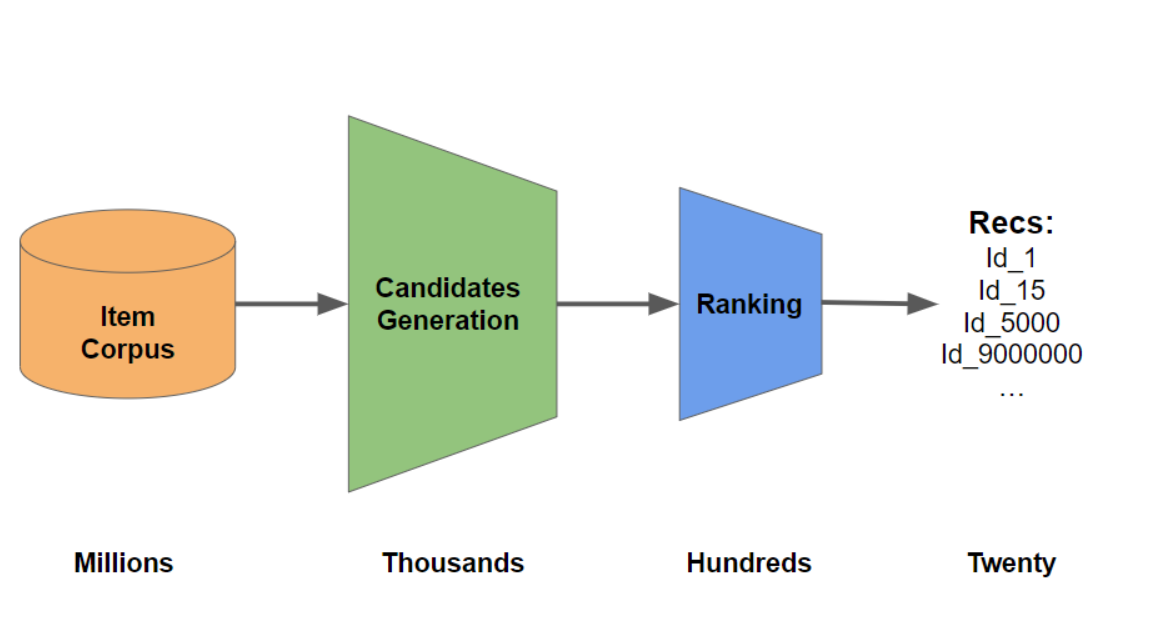
이 시스템을 간략히 소개하자면, 먼저 Candidates Generation 단계에서 Matrix Factorization이나 Two-Tower 모델과 같이 대규모 데이터에 확장 가능한 알고리즘을 활용해 수 백만 개의 아이템 중 1,000개 이하의 아이템을 추출합니다. 그 다음 Re-Ranking 단계에서는 XGBoost나 CatBoost와 같은 부스팅 모델 또는 상대적으로 복잡한 딥러닝 모델 등을 사용하여 후보 아이템의 순위를 재조정합니다.
본 대회에서 이러한 모델을 어떻게 구성하고 학습을 진행했는지 뒤에서 보다 자세하게 소개하겠습니다.
💡 관련 연구
[1] Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations." Proceedings of the 10th ACM conference on recommender systems. 2016
[2] Higley, Karl, et al. "Building and Deploying a Multi-Stage Recommender System with Merlin." Proceedings of the 16th ACM Conference on Recommender Systems. 2022
Stage1 - Candidates Generation
본 대회에서는 후보 생성은 아이템-아이템 연관도 행렬 $M_{AB}$을 구하고, 그 값을 유저가 상호작용한 아이템에 대해 종합하여 유저-아이템 점수로 환산하는 방식이 많이 사용되었습니다. 가장 흔하게 사용된 아이템-아이템 연관도 계산방식은 동시등장 행렬 (covisitation matrix) 기반 방식입니다.
1. 동시등장 행렬로 아이템-아이템 점수 구하기
동시등장행렬 방식은 두 아이템이 같은 세션에 등장 하는 경우를 세는 것입니다. 동시등장행렬은 쉽게 변형할 수 있어 목적에 따라 여러가지 동시등장행렬을 사용 할 수 있습니다. 이번 포스팅에서는 간단하면서도 중요하게 사용된 클릭-장바구니 동시등장행렬을 예시로 들겠습니다.

위 그림은 실제 세션을 나타낸 것으로 각 점은 이벤트이고, 가로 축이 시간입니다. 해당 유저는 0 ~ 6 아이템을 클릭 하였고, 0, 2, 3, 5 아이템을 장바구니에 담았습니다.
5번 아이템을 장바구니에 담은 시점에서 앞뒤로 1분 이내에 상호작용한 아이템은 4, 5, 6번 아이템입니다. 이 때 $M_{4,5}, M_{5,5}, M_{6,5}$ 를 1 증가시킵니다. 0, 2, 3 장바구니 이벤트에서도 마찬가지로 계산합니다. 그럼 위 세션에 대한 $M_{AB}$는 왼쪽의 희소행렬이 됩니다.
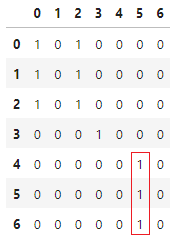 세션 1개에 대한 동시등장행렬 |
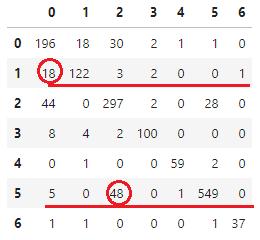 전체 세션에 대한 동시등장행렬 |
모든 세션에 대해 똑같이 계산하여 합하면 오른쪽과 같은 아이템x아이템 크기의 희소 행렬을 얻습니다. 이렇게 1분간격 클릭-장바구니 동시등장행렬을 계산 할 수 있습니다. 본 대회에서 사용한 동시등장 행렬은 실제로1,855,603×1,855,603 크기를 가지지만, 이해를 돕기 위해 1 세션에 나타난 0~6만 표기했습니다.
위 행렬을 통해 1번 아이템을 클릭한 유저는 1, 0번 아이템을 주로 장바구니에 담았고, 5번 아이템을 클릭한 유저는 5, 2번 아이템을 주로 장바구니에 담는 것을 파악할 수 있습니다.
따라서, 새로운 유저가 1, 5번 아이템을 클릭했다면 1, 5는 물론 0, 2번 아이템도 장바구니에 담을 것을 추천 할 수 있습니다.
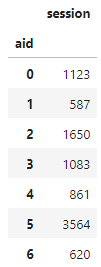 아이템이 등장한 세션 수 |
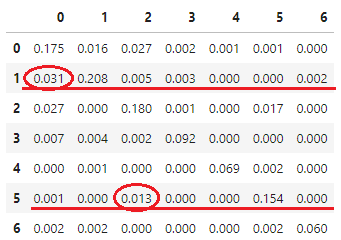 아이템 등장 세션 수로 정규화한 동시등장행렬 |
그러나, 더 정밀한 추천을 위해서는 0번과 2번 중 어떤 아이템을 더 우선적으로 추천해야 할지 고민할 필요가 있습니다. 5 클릭 → 2 장바구니를 지지하는 세션이 48개로, 1클릭 → 0 장바구니를 지지하는 세션 18개 보다 많습니다. 하지만, 5번 아이템을 클릭한 세션이 3,564 개로 더 많아서 클릭에 대한 장바구니 비율을 계산하면 오히려 1 클릭 → 0 장바구니의 비율이 3.1%로 신뢰도가 더 높습니다. 결론적으로, 아이템이 등장한 세션 수로 정규화 한 동시등장 행렬을 사용해 추천한 것의 성능이 좋았습니다.
위 예제에서는 아이템이 세션에 같이 등장 하는 경우를 모두 똑같이 1로 합산했습니다. 이렇게 계산한 값은 연관분석의 지지도, 신뢰도와 개념과 마찬가지로 해석 할 수 있습니다.
하지만 여기서 1만 사용하는 것이 아니라 두 이벤트 사이의 시간 차이, 두 이벤트 사이의 다른 이벤트 수, 이벤트가 전체 기간에서 얼마나 최근인지 등에 따라 차등적으로 가중치를 주면 다양한 종류의 동시 등장행렬을 얻을 수 있습니다.
2. 아이템-아이템 점수를 유저-아이템 점수로 환산하기
앞에서 구한 아이템-아이템 행렬의 값을 세션에 등장한 아이템들에 대해 가중치를 종합하여 계산합니다. 가중치는 동시등장행렬때와 유사하게 최근일수록 높은 값, 세션 끝에 가까울수록 높은 값, 클릭보다 장바구니에 높은 값 등으로 설정하였고, 종합은 최대값, 총합, 로그합 등을 사용할 수 있습니다.
아래는 유저가 5, 1 순서로 클릭한 경우의 예시입니다.
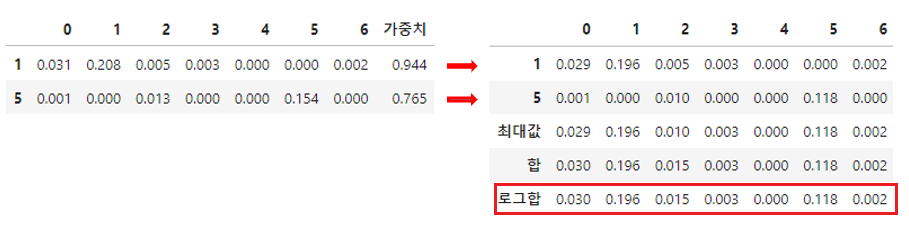
최종적으로 사용한 로그합 방식은 $-\log(1-M_{AB})$ 형태로 로그스케일한 합입니다.
저희는 후보 생성과정에서 동시등장행렬로 얻은 유저-아이템 점수만 활용했지만 이 환산 방식은 다른 아이템-아이템 행렬에도 사용할 수 있습니다.
3. 유저-아이템 점수가 가장 높은 n개 뽑기
이렇게 구한 유저-아이템 점수 중 가장 높은 200개를 후보로 사용했습니다. 동시등장행렬로 구한 유저-아이템 점수는 이후 Re-Ranking단계에서도 Feature로 사용됩니다.
Stage2 - Re-Ranking
이 단계는 선별된 후보 아이템을 선호도 순으로 재정렬 하는 과정이라고 이해할 수 있습니다. 이를 위해 세션과 아이템에 대한 관련된 피처를 Ranker 모델의 입력으로 하여 각 후보 아이템에 대한 선호도를 계산하고 이를 기반으로 재정렬하는 방식으로 추천을 수행합니다.
1. Feature Engineering
Ranker 모델의 학습을 위해서는 일반적인 지도학습 방식의 AI 모델과 마찬가지로 입력 값 x와 정답 값 y가 필요합니다. 아래 그림과 같이 어떤 유저가 Candidates Genertation 단계에서 추려낸 특정 아이템을 장바구니에 넣었다면 y값은 1이 되고 그렇지 않으면 0이 됩니다.

모델의 입력 값으로는 아래와 같은 피처를 사용했습니다.
- Session Features
user_duration : 세션별 진행 시간
user_item_count : 세션별 고유 아이템 개수
user_click_num, user_cart_num, user_order_num : 세션 별 활동 횟수
user_day_last, user_hm_last : 세션 별 마지막 활동 발생 요일 / 시간 (HHMM)
- Item Features
item_cnt : 전체 세션에서 해당 아이템의 등장 횟수
item_day_mode, item_hour_mode: 최빈 요일 / 시간
item_click_ratio_interactions , item_cart_ratio_interactions , item_order_ratio_interactions : 전체 세션에서 해당 아이템의 interaction 중 click / cart / order가 차지하는 비율
- Item-Session Interaction Features
item_click_num, item_cart_num, item_order_num : 테스트 세션에서 해당 아이템의 click / cart / order 횟수
node2vec_cos_sim, word2vec_cos_sim, mf_cos_sim : 각 세션의 마지막 아이템과 해당 아이템의 임베딩 값 간 코사인 유사도
이 외에도 Candidate Generation 과정에서 얻은 score와 rank 등을 추가 피처로 활용하였습니다.
위 피처들은
- 각 세션별로 어떤 특징을 갖고 있는지 (접속 시간, 몇 번 클릭하는 지 등)
- 각 아이템들이 어떤 특징을 갖고 있는지 (주로 어떤 시간에 많이 등장하는지 등)
- 세션의 마지막 아이템과 세션별 후보 아이템들이 얼마나 유사한지
등에 대한 정보이며, 이렇게 뽑은 피처를 기반으로 모델을 학습해 Candidates Generator가 추려낸 아이템을 더 정교하게 재정렬하게 됩니다.
2. Ranker 모델 학습
Ranker 모델에는 아래와 같은 종류가 있으며, 이 중 저희는 XGBRanker을 사용했습니다.
학습 데이터에 존재 하지 않았던 유저에 대해 추천하는 것을 목표로 하기 때문에 학습을 진행 할 때는학습과 검증 데이터에 동일한 세션이 존재하지 않도록 GroupKFold를 사용합니다.
다음은 cart에 대한 Ranker 모델을 학습시키는 과정을 예시로 살펴보도록 하겠습니다.
1) 먼저 타켓과 학습에 사용할 피처를 지정합니다.
TARGET = 'carts'
FEATURES = [col for col in candidates.columns if col not in ['user', 'item', TARGET]]
예측 대상인 carts를 타겟으로 지정하고, 피처로 user, item, carts를 제외한 데이터프레임의 모든 컬럼을 학습에 사용하였습니다. (사용 피처 개수는 총 62개입니다.)
2) 학습에 사용되는 하이퍼파라미터를 세팅합니다.
xgb_parms = {'gpu_id':GPU_ID,
'objective': 'rank:ndcg',
'tree_method':'hist',
'seed': 42,
"colsample_bytree": 0.5495928430151941,
'eta': 0.05,
'max_depth': 18,
'subsample': 0.75,
'min_child_weight': 250,
'gamma': 1,
'lambda': 0.5788787459709578,
'alpha': 0.2844150656399005
}
N_FOLD = 5
seeds = np.random.SeedSequence(42).generate_state(N_FOLD)
각 하이퍼파라미터의 의미는 다음과 같으며 하이퍼파라미터 튜닝 라이브러리인 optuna를 활용해 튜닝했습니다.
- objective: 목적 함수
- rank:pairwise
- rank:ndcg
- rank:map
- tree_method: 사용할 트리 생성 알고리즘 지정
- seed: 시드값 고정
- colsample_bytree: 트리 생성에 필요한 피처의 샘플링에 사용
- eta: 학습률(learning rate)
- max_depth: 트리의 최대 깊이
- min_child_weight: child에서 필요한 관측치들에 대한 가중치
- gamma: leaf 노드의 추가 분할을 결정할 최소 손실 감소 값
- lambda: L2 정규화 적용 값
- alpha: L1 정규화 적용 값
- subsample: 각 트리마다 데이터 샘플링 비율(범위 0~1), 조정을 통해 과적합 방지
3) fold별로 train 데이터셋(train_df)과 valid 데이터셋(valid_df), dmatrix를 생성합니다.
다음으로는 학습용 데이터 프레임을 학습 데이터와 검증용 데이터로 분할하고 XGBoost API에 맞게 데이터 형태를 준비해야 합니다.
첫 번째 단계에서는 sample_train_valid 함수를 사용해 학습용 데이터와 검증용 데이터를 분할하게 됩니다. 이때, 추천한 아이템 중 positive 샘플 대비 negative 샘플이 매우 많기 때문에 negative sampling을 수행하였습니다. 저희의 경우 positive 샘플의 20배에 해당하는 negative 샘플만 사용했습니다.
그 다음, build_dmatrix 함수를 사용해 XGBoost 전용 데이터셋인 dmatrix를 생성합니다. 전체 데이터 집합이 아닌 각 세션 집합에 대한 아이템의 순서를 재정렬하는 것이 학습의 목표이므로 dmatrix의 group 파라미터를 통해 데이터의 그룹 구조를 지정하였습니다.
train_df, valid_df = sample_train_valid(candidates, fold=fold, seed=seeds[fol])
dtrain, dvalid = build_dmatrix(train_df, valid_df)
def sample_train_valid(df, fold=0, neg_per_pos=20, seed=42):
"""
df.fold == fold --> valid
df.fold != fold --> train
train & carts --> pos_train
(train & !carts).sample(neg_per_pos*n_positive) --> neg_train
shuffle(pos_train + neg_train) --> train
"""
ldf = df.lazy()
train_cond = pl.col('fold') != fold
valid_cond = pl.col('fold') == fold
pos_cond = pl.col('carts') == 1
neg_cond = pl.col('carts') != 1
n_positive = ldf.select(train_cond & pos_cond).sum().collect()[0,0]
n_negative = neg_per_pos * n_positive
print(f'train fold{fold} num of negative {n_negative}, positive {n_positive}.')
train_pos_ldf = ldf.filter(train_cond & pos_cond)
train_neg_ldf = ldf.filter(train_cond & neg_cond).select(pl.all().sample(n=n_negative))
train_ldf = pl.concat([train_pos_ldf, train_neg_ldf])
train_ldf = train_ldf.select(pl.all().shuffle(seed)).sort('user')
valid_ldf = ldf.filter(valid_cond).sort('user')
print('split sampling..')
train_df = train_ldf.collect()
valid_df = valid_ldf.collect()
print('sampling done.')
return train_df, valid_df
def build_dmatrix(train_df, valid_df):
X_train = train_df.select(pl.col(FEATURES))
y_train = train_df.select(pl.col(TARGET))
X_valid = valid_df.select(pl.col(FEATURES))
y_valid = valid_df.select(pl.col(TARGET))
train_group = train_df.groupby('user').count().get_column('count').to_numpy()
valid_group = valid_df.groupby('user').count().get_column('count').to_numpy()
dtrain = xgb.DMatrix(
X_train.to_pandas(),
y_train.to_pandas(),
group=train_group,
)
dvalid = xgb.DMatrix(
X_valid.to_pandas(),
y_valid.to_pandas(),
group=valid_group,
)
return dtrain, dvalid
4) XGBoost 학습을 진행합니다.
model = xgb.train(xgb_parms,
dtrain=dtrain,
evals=[(dtrain,'train'),(dvalid,'valid')],
early_stopping_rounds=20,
num_boost_round=10000,
verbose_eval=10)
위에서 설정한 하이퍼파라미터와 dmatrix를 이용하여 모델을 학습시켰습니다. 이 때 속도 개선을 위하여 early_stopping_rounds 파라미터를 지정해주었으며, 20회 이상 valid loss의 개선이 없다면 학습이 중단됩니다. num_boost_round 파라미터는 학습 횟수를 의미하며, evals는 dtrain은 ‘train’으로, dvalid는 ‘valid’로 로깅하도록 지정합니다. 마지막으로, verbose_eval은 몇 번째 반복마다 출력 메세지를 표시할지 결정합니다.
5) Feature Importance
Feature Importance란 피처가 얼마나 많이 노드 분기에 영향을 주었는지를 통해 피처의 중요도를 나타내는 지표라고 볼 수 있으며, XGBoost 에서는 weight, cover, gain의 세 가지 기준으로 판단됩니다.
XGBoost의 경우 plot_importance 함수를 지원하며, weight 방식이 기본으로 지정되어 있습니다. 학습된 모델을 불러와 아래의 코드를 통하여 feature importance 그래프를 그릴 수 있습니다.
import xgboost as xgb
import matplotlib.pyplot as plt
model = xgb.Booster()
model.load_model('XGB_fold4_carts.xgb')
plt.figure(figsize=(12,16))
fig, ax = plt.subplots(figsize = (7, 5))
xgb.plot_importance(model, ax = ax, max_num_features=10)
feature importance 그래프는 아래와 같이 나타납니다. (상위 10개의 피처만 나타냈습니다.)
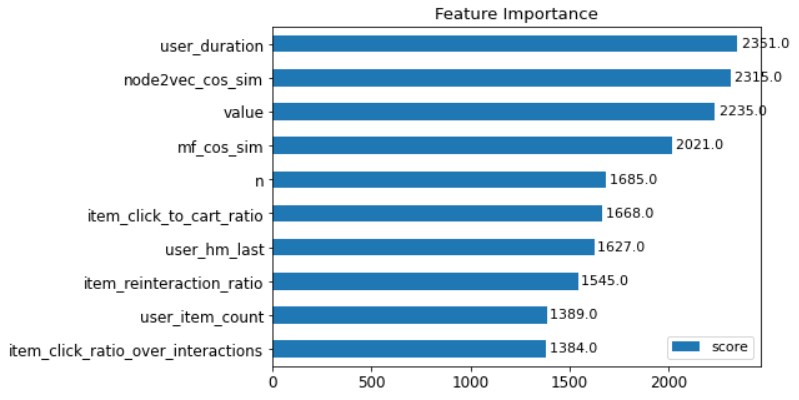
Candidates Generation 단계에서 도출된 value(동시등장핼렬의 값), n(추천 순위)과 같은 피처가 높은 성능을 보였고, user_duration, user_hm_last와 같은 시간과 관련된 피처도 모델 학습 과정에서 중요하게 사용되었다는 것을 알 수 있습니다.
그 외 node2vec_cos_sim, mf_cos_sim 와 같은 임베딩 피처와 세션과 아이템 간의 상호작용을 나타내는 item_reinteraction_ratio, user_item_count 등과 같은 피처가 상위권을 차지하고 있는 것을 볼 수 있습니다.
6) 학습한 모델을 저장하고 예측을 수행합니다.
예측을 수행하기 위해서는 학습용 데이터셋과 마찬가지로 평가용 데이터셋에 대한 Candidates Generation을 진행하고, 앞서 설명한 것과 동일한 피처를 추가해주어야 합니다.
이를 통해 만들어진 데이터프레임을 dmatrix 형태로 바꿔준 뒤에 click, cart, order에 대해 학습된 모델에 넣어주면 최종 예측 결과를 얻을 수 있습니다.
예시 코드는 아래와 같습니다.
N = 5
for fold in tqdm(range(N)):
model = xgb.Booster()
model.load_model(f'XGB_fold{fold}_carts.xgb')
model.set_param({'predictor': 'gpu_predictor'})
for k in range(CHUNKS):
dtest = xgb.DMatrix(data=cudf.from_pandas(candidates.iloc[k*chunk_size:(k+1)*chunk_size][FEATURES]))
preds[k*chunk_size:(k+1)*chunk_size] += model.predict(dtest)
Winning Solutions
캐글에 올라온 상위권 솔루션들의 특징을 정리해보면 아래와 같습니다.
1. Candidate Generation
- 다양한 조건과 가중치를 사용하여 co-visitation matrix를 생성하였습니다.
- Word2vec, Matrix Factorization 등을 통해 TopK의 후보를 생성하여 추가로 사용하였습니다.
2. Feature Engineering
- Candidate Genenration 단계에서 사용한 score, rank 등의 값을 피처로 활용하였습니다.
- 100여개 이상의 피처를 생성하여 학습에 사용하였습니다.
- Embedding 값간의 유사도를 피처로 활용하였으며, 세션의 마지막 아이템과 후보 아이템 간의 유사도 값이 일반적으로 가장 feature importance가 높은 것을 확인할 수 있습니다.
3. Model
- Boosting 계열의 모델(XGBoost, CatBoost, Light GBM)을 활용하여 Ranking을 진행하였습니다.
- 각 모델의 결과에 대해 앙상블 기법을 적용하여 최종 Score를 높였습니다. 이 때 주로 적용한 앙상블 기법은 Voting과 Stacking 입니다.
- Voting : 각 모델의 예측값을 합쳐서 최종 결과값을 도출합니다. 경우에 따라 모든 모델에 포함된 아이템, 혹은 가장 많이 나온 아이템만 선택하는 hard voting 방식으로 진행하기도 하고, 아이템별 score의 평균을 구하여 아이템을 선택하는 soft voting 방식을 사용하기도 합니다.
- Stacking : 개별 모델이 예측한 값을 다시 train 데이터셋으로 활용하여 모델에 재학습 시킵니다. 학습 시 피처로는 이전 예측값에서의 예측 score, rank 등이 사용됩니다. 각 모델에서 나온 결과를 피처로 사용하는 것이 특징입니다.
저희 솔루션과 비교하였을 때 전반적인 모델 구성은 Two-Stage로 동일하나
- co-visitation matrix와 feature를 더 많이 추출하여 사용
- 마지막에 서로 다른 파라미터로 학습 시킨 모델들의 결과를 voting, stacking과 같은 앙상블을 사용하여 최종 결과를 생성
하였다는 점에서 차이가 있었습니다.
대회를 참여해보니, 이번 대회는 모델의 구현만큼 피처 엔지니어링을 비롯한 데이터 처리가 중요했던 대회였다고 생각합니다.
상위권 솔루션과 비교하였을 때 저희는 결과적으로 하나의 방법을 활용하여 후보를 생성하였고, 총 62개의 feature를 사용하였으며 여러 결과값에 대한 앙상블을 시도하지 않았습니다. 실제로 학습 과정에서 feature가 추가될 때마다 스코어가 향상됨을 확인하였고, 대회 기간 내에 앙상블 방법에 대한 논의가 있었으며 또한 메달권 내 리더보드 스코어 차이가 크지 않았기 때문에 시간이 더 있었으면 어땠을까 하는 아쉬움이 남습니다.
그러나 약 한달의 시간 동안 규모가 큰 데이터를 다루는 방법부터 여러 추천 시스템 모델까지 많이 배울 수 있는 기회였습니다.
(+) kaggle Discussion 잘 읽자 → 도움이 되는 팁들이 많음
(+) 안되는 건 빨리 버리자
(+) 팀원끼리 각자 시도한 것에 대한 결과를 잘 공유하자
Summary
- 대규모 데이터를 다루기 위해 아래와 같은 방법을 시도하였습니다.
- CuDF, Polars와 같은 GPU 지원 및 CPU 병렬 연산이 가능한 라이브러리 사용
- 데이터 Chunk로 나눠서 사용
- Two-Stage model을 사용하였습니다.
- co-visitation matrix를 사용하여 candidate 추출
- Feature engineering 진행
- XGBoost 모델을 사용하여 학습
이 글로 OTTO 대회 은메달 수상기를 마칩니다. AI CONNECT와 MNC의 Kaggle 도전기는 앞으로도 쭈욱 이어집니다 🌟
'AI to the Real World > 캐글 탐험대' 카테고리의 다른 글
| 🥈은메달 수상기 (1) OTTO 추천시스템 대회 A to Z (0) | 2023.02.16 |
|---|---|
| [캐글탐험대] Happy Whale 대회 (0) | 2022.05.19 |
| [Kaggle] Doodle Recognition Challenge Insight-1 (0) | 2022.05.19 |
| [캐글탐험대] PetFinder 대회 (2편) (0) | 2022.04.26 |
| [캐글탐험대] PetFinder 대회 (1편) (0) | 2022.04.26 |