Machine Learning, Deep Learning 등 최신 AI 기술을 이해하기 위해서는 기본적인 이론 학습이 필요합니다. [ML101] 시리즈에서는 입문자를 위해 AI와 관련된 주요 이론을 챕터별로 소개합니다. 본 내용은 AI의 거장 Andrew Ng 교수의 강의 syllabus를 참고하여 주요 개념들을 정리한 내용입니다.
세부 이론을 살펴보기에 앞서 Machine Learning 프로젝트를 설계하는 일반적인 방법을 생각해 보겠습니다. 다소 진부한 내용이긴 합니다만 프로젝트를 실행할 때 결과 도출까지의 전체 과정을 머릿속으로 그려보고 시작하는 것은 효율과 성과를 높이는 중요한 방법이라고 생각됩니다. 자, 그럼 Machine Learning 프로젝트는 어디서부터 어떻게 시작해야 할까요?
1. 문제를 정의한다.
주어진 문제가 무엇이며, 어떻게, 왜 해야 하는지 고민을 시작합니다. 문제를 정의하는 방식은 개인마다 다르겠지만 Machine Learning 프로젝트에서는 TPE를 활용하는 것을 추천드립니다.
- Task T: 바둑 두기, 손글씨 이해하기, 자율주행 자동차 작동하기 등
- Performance measure P: 바둑 승률, 손글씨 분류 정확도, 자율주행 자동차의 평균 이동 거리 등
- Training experience E: 자신과의 연습 게임, 분류가 되어있는 손글씨 데이터셋 학습, 이미지와 핸들 조향 순서 기록 학습 등
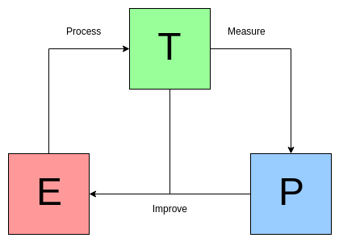
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.” - Tom M. Mitchell
문제를 정의했다면, 풀어야 하는 문제와 유사한 사례를 찾아봅니다. 구글에서 관련된 용어를 검색해보고 대표 용어를 확인합니다. 다시 구글에서 대표 용어로 사례를 찾아보면 분명 전 세계의 많은 Data scientist들이 비슷한 문제에 접근한 사례를 공유하고 있을 겁니다. 유사한 사례도 찾았다면 간략하게라도 직접 문제를 풀어봅니다. Prototyping을 하거나, 몇 개의 수식을 활용하여 손으로 직접 풀어봐도 좋습니다.
2. 데이터를 준비한다.
문제를 해결하기 위해서는 데이터가 필요하겠죠? 이미 주어진 데이터가 있을 수도 있고 다른 곳에서 데이터를 확보해야 할 수도 있습니다. 데이터를 구하는 것은 무척 어려운 일입니다. 문제를 해결하는데 도움이 될 만한 데이터를 상상하고 최대한 확보해야 합니다. 데이터를 구하면 전체 데이터 중 어떤 데이터를 사용할지 정의하고, 전처리(Pre-processing)를 해야 합니다. 다른 종의 데이터들과 복합적으로 사용하거나 모델에 적용하기 위해 알맞은 형태로 데이터를 변형시키는 일들도 필요하죠. 아래는 데이터를 준비하는 데 필요한 몇 가지 방법들입니다.
- Data selection: 보유하고 있는 데이터, 보유할 수 있는 데이터, 보유할 수 없는 데이터를 구분하고, 그 안에서 적절한 가정하에 사용 가능한 모든 데이터를 선택합니다.
- Data pre-processing: 데이터 구조를 표준화하거나 정제합니다. Formatting(예. 주소 데이터를 고도와 위도 데이터로 변경), Cleaning(예. 민감 정보의 익명화, 누락된 데이터 제거), Sampling(예. 빠른 prototyping을 위해 대표 데이터 추출) 등이 있습니다.
- Data transformation: 데이터의 형태를 변경합니다. Decomposition(예. 더 관련성 높은 하위 특징으로 데이터 구성), Scaling(예. 0~1 사이로 정규화), Aggregation(예. 개인 고객의 일별 로그인 횟수 집계) 등이 있습니다.
- 위 방법들을 수행하고 Training, Test, Validation set으로 데이터를 나눕니다.
3. 성과를 측정할 도구를 선택한다.
1번에서 정의한 문제 유형(분류, 예측 등)에 따라 성과를 측정하는 도구는 달라집니다. 문제 유형이 같더라도 Machine Learning 프로젝트에는 다양한 성과 측정 지표들이 존재합니다. 이런 성과 측정 도구를 비용 함수(Cost function) 또는 손실 함수(Loss function)이라고 합니다.
이 함수는 모델의 예측 품질을 정량화해줍니다. 모델의 예측이 얼마나 정확한지, 잘 나왔는지 체계적인 근거를 제공해 주는 것이죠. 대표적인 비용 함수로는 MAE, MSE, RMSE, cosine distance, cross-entropy, KL divergence 등이 있습니다. 이 지표들에 대해서는 다음 기회에 구체적으로 살펴보는 시간을 갖겠습니다.
성과를 측정할 비용 함수를 선택하면, 우리의 목표는 비용 함수를 작게 만드는 것입니다. 학습 데이터에 맞게 점진적으로 모델을 최적화하여 비용 함수의 값을 줄이기 위해 계속해서 반복 작업을 수행합니다. 일반적으로 경사 하강법(Gradient descent)을 이용해 비용 함숫값을 최적화하며, 이 과정에서 Learning rate의 적합한 조정이 필수적입니다. 이 개념도 중요한 부분이니 다음에 더 자세하게 글을 쓰겠습니다.

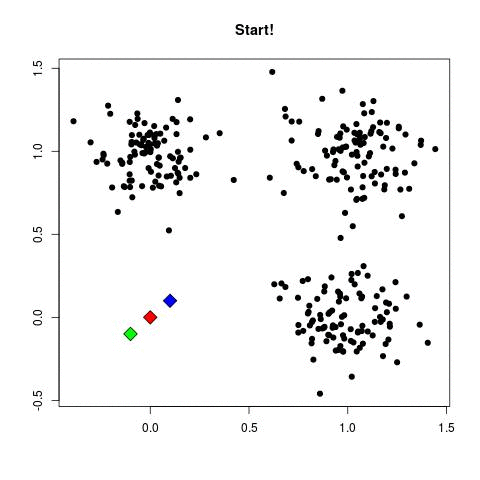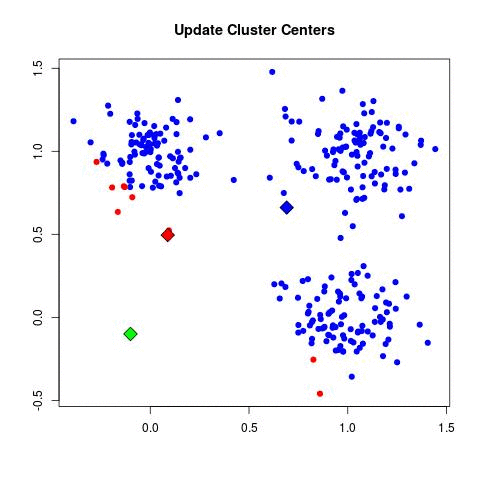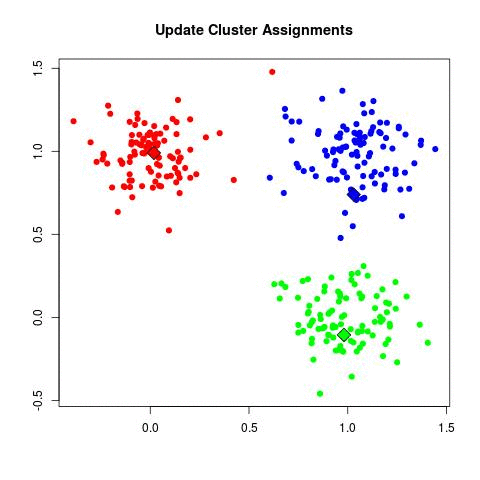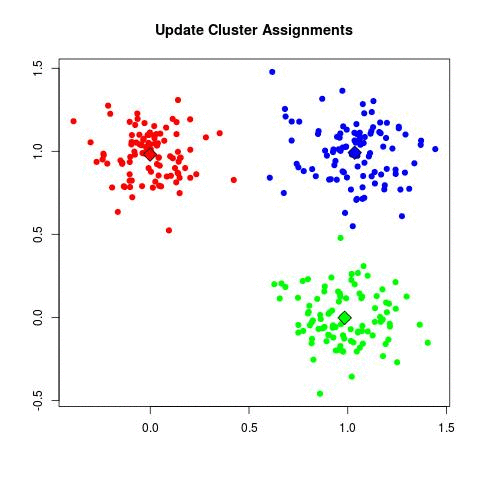
4. 결과를 개선한다.
비용 함수를 최적화하는 것만큼이나 결과를 개선할 수 있는 방법은 다양합니다. 알고리즘을 튜닝, 알고리즘 조합, 모델에 사용한 Feature를 다른 형태로 가공하는 방법들이 있죠. 다음은 모델 성능을 높이기 위한 대표적인 방법들입니다.
- Algorithm tuning: 체계적(Systematic), 또는 자동적으로(Automatic) parameter를 수정합니다.
- Ensembles: 다수의 알고리즘을 조합하여 사용합니다. Bagging, Boosting, Blending 기법이 있습니다.
- Bagging: 학습 데이터의 서로 다른 하위 집합으로 학습함
- Boosting: 동일한 학습 데이터를 다른 알고리즘으로 학습함
- Blending: 모델을 다른 모델의 입력값으로 쌓아서 학습함 - Feature engineering: 모델에 사용한 Feature에 변화를 주는 것으로, 실수(real number)를 구간 값(bin count)이나 word to vector 등으로 바꿔 학습하는 것입니다.
5. 결과를 공유한다.
결과가 나오면 공유하는 시간을 가집니다. 수행한 Machine Learning 프로젝의 동기와 간결하게 문제에 대해 설명합니다. 해결 방법에 대한 설명과 프로젝트를 진행하면서 새롭게 발견한 점, 모델이 작동하지 않거나 해결할 수 없었던 부분에 대한 한계점도 꼭 남겨놔야 합니다.
여러 해결 방안 중에 최종적으로 선택한 모델의 이유와 접근 방법도 정리해 놓으면 다른 프로젝트를 수행할 때 중요한 자산으로 활용할 수 있습니다. 수행했던 모든 과정을 정리하고 다른 사람에게 공유함으로써 다음 프로젝트는 더 발전될 수 있을 것입니다. Machine Learning은 공유 속에서 더 큰 강점을 발휘할 수 있습니다.
지금까지 Machine Learning 프로젝트의 대략적인 과정을 살펴봤습니다. 첫 글이다 보니 중요한 개념들을 간단하게 짚고 넘어가는 부분들이 많았네요. 다음 글에서부터는 세부 이론, 개념들에 대해 구체적으로 이해하는 시간을 갖도록 하겠습니다.
'AI Study > ML101' 카테고리의 다른 글
| [ML101] #5. Confusion matrix (0) | 2022.04.26 |
|---|---|
| [ML101] #4. Gradient descent (0) | 2022.04.26 |
| [ML101] #3. Loss Function (0) | 2022.04.26 |
| r[ML101] #2. Regression (0) | 2022.04.26 |
| [ML101] #1. Machine Learning? (0) | 2022.04.26 |