[ML101] 시리즈의 첫 번째 주제는 회귀(Regression)입니다. 회귀분석은 너무나도 유명한 통계 기법이죠. 대학에서는 전공을 불문하고 다양한 사례로 언급되기도 하고, 업무에서도 수요나 가격을 예측하고 전망할 때 회귀분석을 접해 보셨을 겁니다.
"회귀분석(回歸分析, regression analysis)이란 관찰된 여러 변수들에 대해 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석 방법"이라고 Wikipedia에 소개가 나옵니다. 독립적인 변수(Independent variable)를 활용해 목푯값인 종속변수(Dependent variable)를 예측하는 모델링 기법이죠. 변수 간의 인과관계(Cause-effect relationship)를 예측하는 데 주로 사용됩니다. 독립변수의 개수, 독립변수와 종속변수 간의 관계 유형에 따라 회귀분석 안에서도 기법이 다른데, 크게 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression)로 나눌 수 있습니다.
- 선형 회귀 : 독립변수와 종속변수 사이의 선형(Linear) 관계를 예측함
- 로지스틱 회귀 : 범주형(Categorical) 종속변수의 확률을 예측함
그럼 지금부터 선형 회귀와 로지스틱 회귀의 특징을 이해하고, Machine Learning에서 회귀분석을 수행함에 있어 이해해야 하는 주요 개념들을 살펴보도록 하겠습니다.
1. 선형 회귀 (Linear Regression)
선형 회귀는 종속 변수와 하나 이상의 독립변수 간의 관계를 선형적(직선)으로 모형화하는 분석 방법입니다. 독립변수가 1개이면 단일 회귀, 여러 개이면 다중 회귀(Multiple Linear Regression)라고 하죠. 방의 개수에 따라 주택 가격이 어떻게 변하는지 예측하거나, 예습 시간에 따른 시험 성적이 어떻게 변할지, 나이, 키, 몸무게, 운동 시간 등으로 체중이 어떻게 변화할지 예측하는 것들에 선형 회귀 분석을 사용할 수 있습니다. 선형 회귀의 기본식은 y=a1x+a0인데, y는 주택 가격, x는 방 개수라고 이해하시면 됩니다. 독립변수가 2개 이상으로 늘어나면 x의 개수도 그만큼 늘어나는 식이 만들어질 테죠. a1은 독립변수의 값에 영향을 미치는 회귀 계수(Regression coefficient)라고 합니다. 주어진 독립변수와 종속변수 데이터에 기반에서 학습을 하고 최적의 회귀 계수를 찾아내는 것이 핵심입니다. Machine Learning 관점에서 독립변수는 Feature에 해당하고, 종속변수는 결정 값에 해당합니다.
아래 그림에서 파란색 점들은 실제 관측값이고, 녹색 선은 회귀모형입니다. 회귀선과 각 관측값의 차이를 잔차(Residual)이라고 하는데, 좋은 회귀 모형은 이 잔차를 최소화하는 모형입니다. 선형 회귀에서는 손실 함수(Loss function)로 잔차의 절댓값을 더하거나(MAE, Mean Absolute Error), 잔차의 제곱을 모두 더하는 방식(RSS, Residual Sum of Square)을 사용합니다. Machine Learning에서는 RSS 방식의 평균 제곱 오차(MSE, Mean Squared Error)를 주로 사용해서 MSE를 최소화시키기 위한 a0, a1을 찾아내는 것을 목표로 합니다. MSE는 예측된 값과 실제 값의 차이를 제곱해서 평균을 낸 수치이며, 아래 식으로 나타낼 수 있습니다.
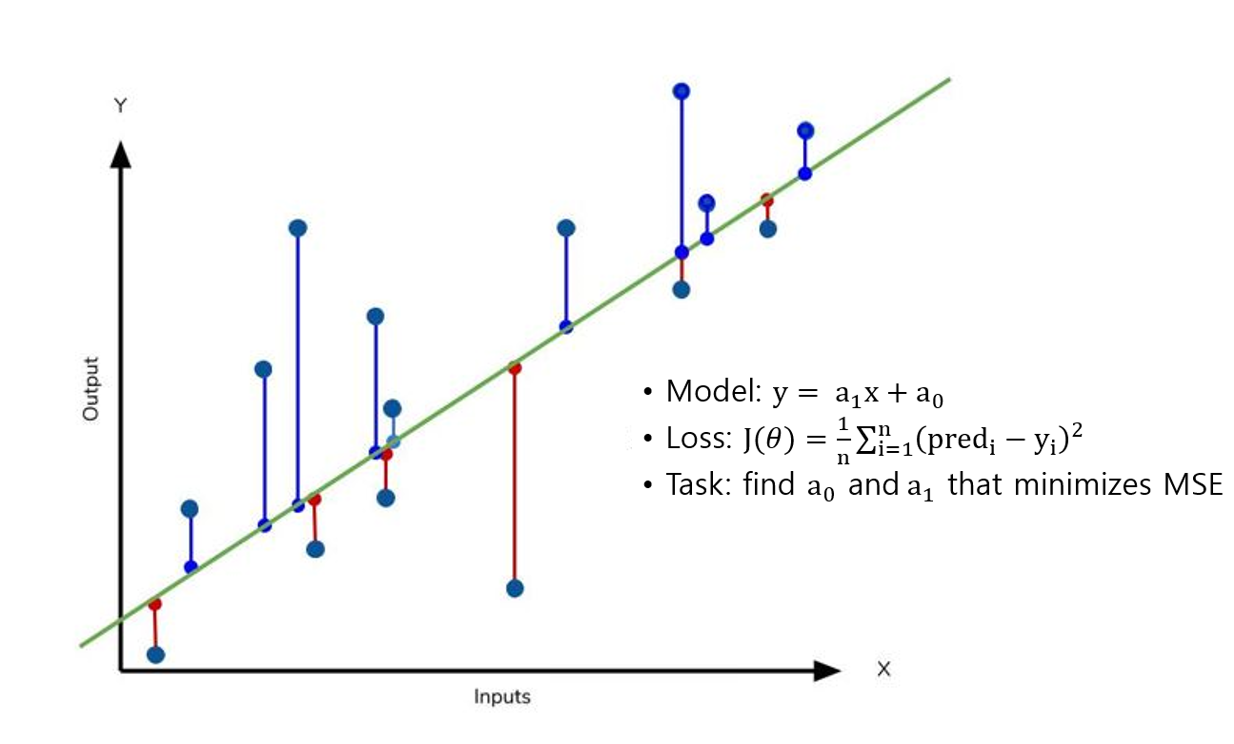
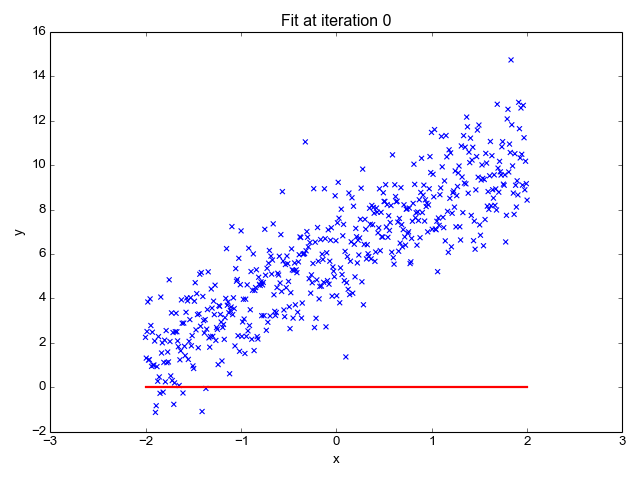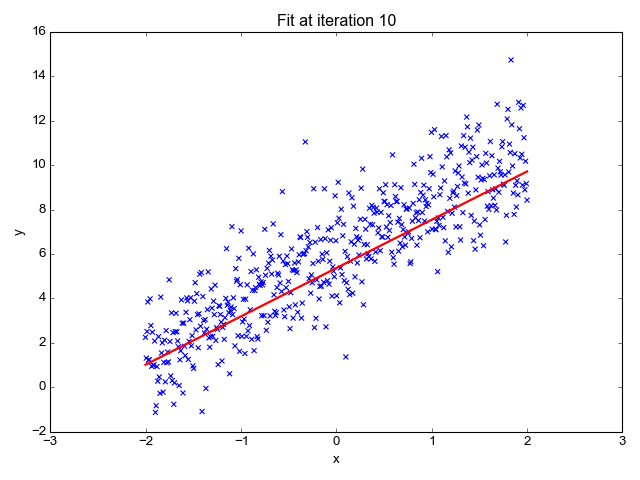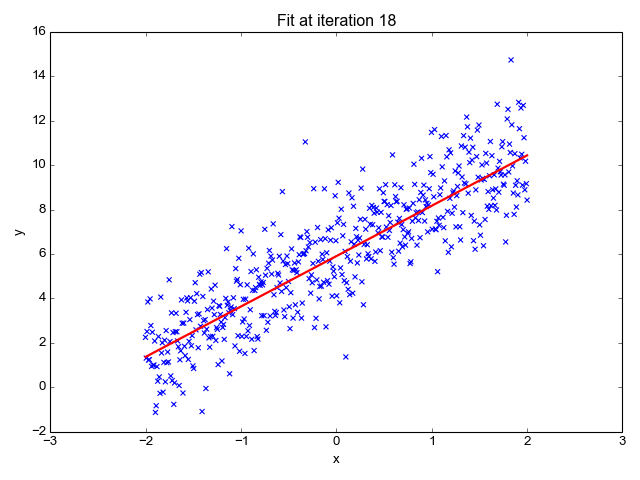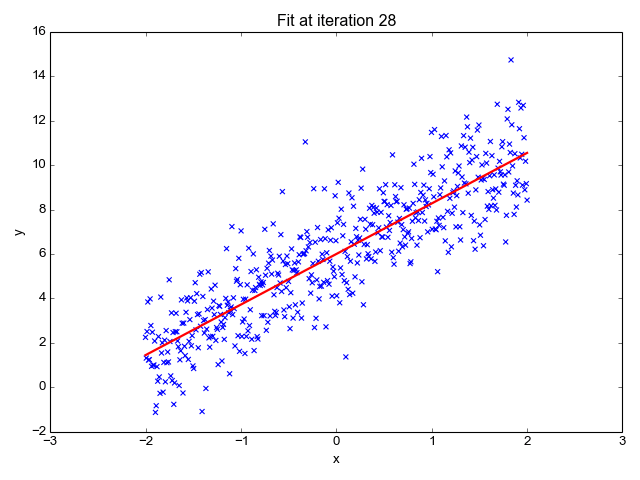
MSE를 최소화하는 a0, a1을 찾기 위해서는 경사 하강법(Gradient descent)을 사용합니다. 경사 하강법은 점진적으로 반복적인 계산을 통해 회귀 계수 파라미터 값(a0, a1)을 업데이트하면서 오류 값(MSE)이 최소가 되는 상황을 구하는 방식으로 손실을 최적화하는 방법입니다. 경사 하강법은 Machine Learning에서 핵심이 되는 개념이기 때문에 별도의 글로 구체적으로 살펴보겠습니다.
2. 로지스틱 회귀 (Logistic Regression)
Machine Learning의 유형을 분류하는 방법은 학자마다 조금씩 차이는 있지만, 일반적으로 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)으로 나눌 수 있습니다. 최근까지의 실제 활용 사례를 보면 지도 학습이 가장 많은 비율을 차지하고 있죠. 지도 학습은 정답이 있는 데이터(Data with labels)로 학습을 하는 방법이며, 회귀와 분류(Classification)가 이에 속합니다.
회귀와 분류의 가장 큰 차이는 예측하고자 하는 값의 유형입니다. 회귀 분석의 예측값은 연속된 숫자인 반면, 분류의 예측값은 범주(Category)입니다. 신장, 나이, 소득 등이 연속형 값이라면, 성별, 거주 국가 등은 범주형 값이라고 할 수 있죠. 지금부터 말씀드릴 로지스틱 회귀는 선형 회귀와 다르게 종속 변수(예측하고자 하는 값)가 범주형 데이터로 이항 분포(Bernoulli Distribution)를 따릅니다. 그렇기 때문에 Machine Learning에서는 로지스틱 회귀를 일종의 분류 모델로 활용하기도 합니다. 여러 독립변수에 의해 종양이 양성 일지 음성 일지, 이메일이 스팸 일지 아닐지 예측하는 형태로 말이죠.
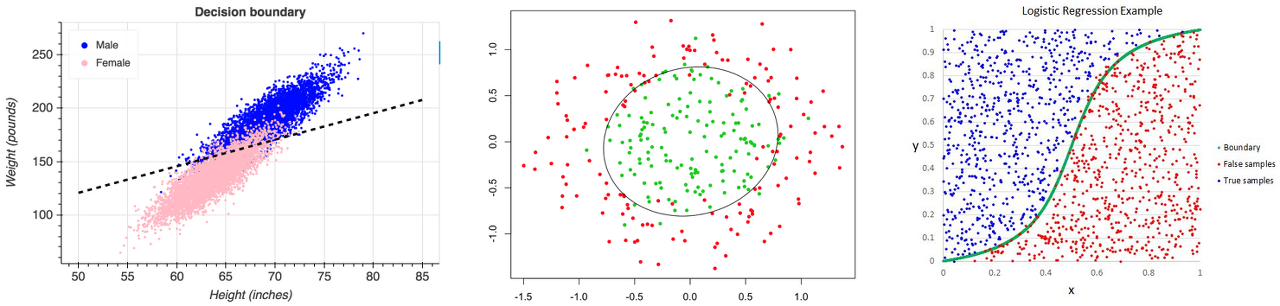
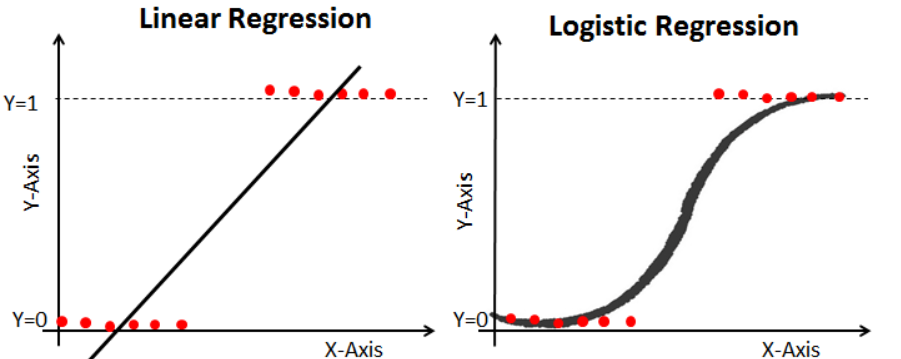
선형 회귀가 하나의 직선 모형을 만들어 값을 예측했다면, 로지스틱 회귀는 값이 나올 확률을 0~1 사이로 반환해서 Binary 값으로 예측합니다. 종양이 양성이라면 1, 음성이라면 0이라고 할 때 예측값인 0과 1은 수치적 의미를 갖지 않습니다. 범주형 데이터는 아래 그림에서처럼 양 극단에 분포하게 되는데 이를 추정하기에는 선형 모델은 적합하지 않죠. 이런 경우 데이터 분포와 비슷한 형태를 띠는, 이산 변수(Discrete variables)를 구별하는 경계가 있는 함수가 필요합니다. 이것이 시그모이드 함수(Sigmoid function)입니다.
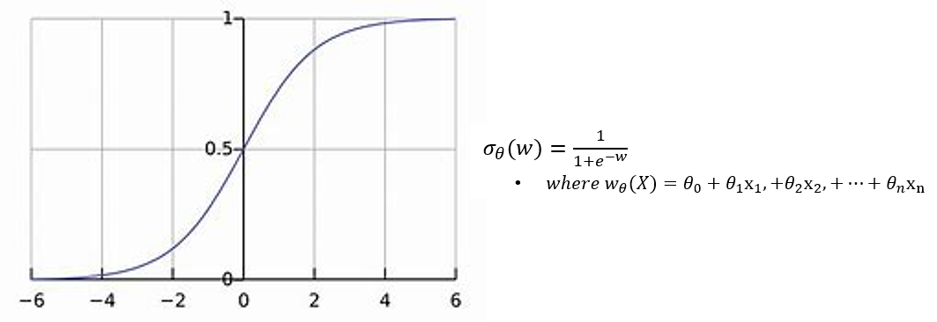
시그모이드 함수는 x 값이 커질수록 1에, 작아질수록 0에 수렴하고, 0일 때는 0.5의 확률을 가지는 함수입니다. 보통 결정 경곗값(Cutoff)으로 0.5로 설정하지만 데이터의 유형에 따라 무엇이든 선택이 가능합니다. 최적화를 위한 손실 함수는 최대 우도 추정(MLE, Maximum Likelihood Estimation)을 사용하는데, 우도(Likelihood)는 매개 변수(Parameters)의 함수로 주어진 데이터를 관측할 확률이며, 최대 우도 추정은 모형의 모수에 대한 값을 결정하는 방법입니다. 매개 변수 값은 모델에서 설명된 프로세스가 실제로 관찰된 데이터를 생성할 가능성을 최대화하도록 만듭니다. 선형 회귀와 마찬가지로 로지스틱 회귀도 임의의 초기값을 설정하고 최대 우도 추정을 점차 최적화해 나가면서 모델 성능을 높입니다.
지금까지 회귀에 대해 알아봤습니다. 다음 글에서는 손실 함수(Loss function)에 대해 구체적으로 알아보겠습니다. 몇 개의 개념을 더 이해하면 회귀에 대한 이해도도 더 높아질 것이라고 생각됩니다.
'AI Study > ML101' 카테고리의 다른 글
| [ML101] #5. Confusion matrix (0) | 2022.04.26 |
|---|---|
| [ML101] #4. Gradient descent (0) | 2022.04.26 |
| [ML101] #3. Loss Function (0) | 2022.04.26 |
| [ML101] #1. Machine Learning? (0) | 2022.04.26 |
| [ML101] #0. Foreword (0) | 2022.04.25 |