"AI 어떤 게 있지?"라고 물었을 때 '알파고'를 떠올린다면 언제 적 알파고냐고 할 만큼 AI는 우리 생활 속에 넓고 깊숙이, 또 빠르게 자리를 잡았습니다.
빅스비에게 음성으로 맞춘 알람에 일어나 카카오 미니가 틀어주는 내 취향의 음악을 들으며 하루를 시작합니다. AI 아나운서가 전해주는 뉴스를 보며 출근하고, 퇴근 후엔 유튜브와 넷플릭스 알고리즘의 무한 굴레에 빠져 영상을 시청하다가 잠에 드는 모습, 새삼스럽지 않을 것입니다.
AI가 익숙해진 것은 일상생활뿐만이 아니라 업무환경에서도 마찬가지입니다. AI를 기반으로 매번 바뀌는 대출 규제의 일부 내용과 담당 부서를 고객에 따라 정확히 안내해주는 행내 검색 기능으로 은행원들의 대출고객 상담 시간이 감소하였으며, 제조업 공장에서는 AI 모델을 통해 최적의 공정조건을 찾아 불량률을 개선합니다.
AI 시장이 점차 성숙됨에 따라 보다 실용적이고 고도화된 AI 솔루션이 출시되고 있으며 전공을 불문하고 AI 기술에 대한 이해도가 요구되고 있습니다. 앞선 글에서 언급했다시피 AI 입문자들의 탄탄한 기초 이론 학습을 돕고자 [ML 101] 시리즈를 연재하고자 하며, 그 첫 시작으로 AI와 Machine Learning의 기본 개념과 기본 알고리즘을 간단히 훑어보도록 하겠습니다.
# AI와 ML의 차이점
인공지능(Artificial Intelligence)과 머신러닝(Machine Learning)이라는 말은 단짝처럼 붙어 다닙니다. 이 두 가지 용어는 어떻게 다를까요? 결론부터 말씀드리자면 인공지능은 가장 넓은 개념이고, 인공지능을 구현하는 방법 중 중요한 방법이 기계학습 또는 머신러닝입니다.
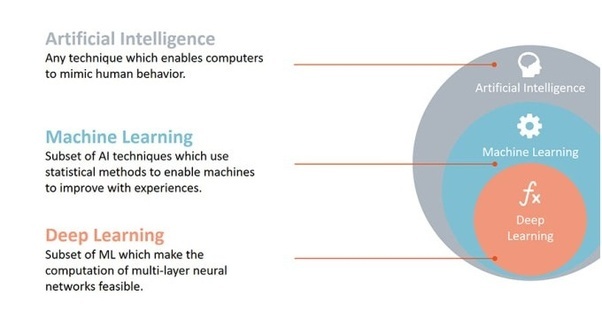
아직 정확히 이해가 안 되신다고요? 인공지능의 개념이 혼란스러운 이유는 아직 인공지능의 정의(definition)가 명확하지 않기 때문입니다. ‘인공지능 - 현대적 접근 (Artificial Intelligence - A Modern Approach)’이라는 책에는 네 가지 관점의 정의가 나옵니다.
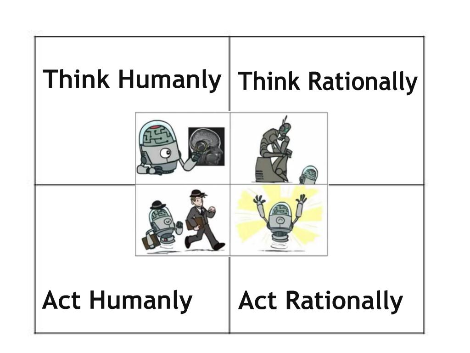
- 인간처럼 생각하는(Thinking Humanly) 시스템
- 인간처럼 행동하는(Acting Humanly) 시스템
- 이성적으로 생각하는(Thinking Rationally) 시스템
- 이성적으로 행동하는(Acting Rationally) 시스템
위처럼 다양한 정의가 존재하나 아직 통용되는 하나의 정의는 없습니다. 인공지능이라는 단어를 이해하기 어려운 이유입니다.
반대로 머신러닝은 직관적으로 받아들여질 수 있습니다. 컴퓨터가 어떤 경험을 통해 성능이 향상되는 것을 학습(Training)한다고 하며 이것을 우리는 머신러닝 혹은 기계학습이라고 표현합니다. 일반적인 프로그램이 데이터(Data)와 규칙(Rules)을 학습하여 답(Answer)을 도출한다면, 머신러닝은 데이터와 답을 학습하여 규칙을 만드는 프로그램이라고 할 수 있습니다.
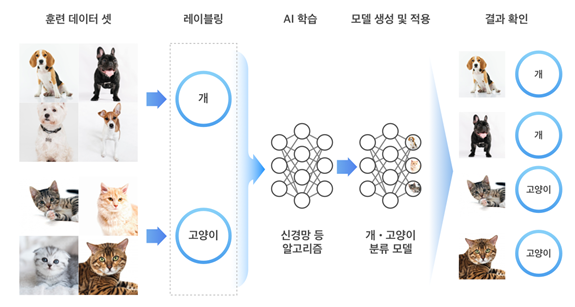
사람은 강아지와 고양이 사진을 보면 쉽게 구분할 수 있습니다. 그러나 컴퓨터는 강아지와 고양이의 차이점을 설명하지 않으면 구분해 낼 수 없습니다.

머신러닝을 활용하여 우리는 강아지와 고양이 사진을 주고 학습을 시켜서 이 둘을 구분해 내는 프로그램을 만들 수 있습니다. 앞으로 이러한 프로그램을 모델(Model)이라고 부르게 됩니다.
# 머신러닝의 유형
본격적으로 머신러닝에 대해서 알아보겠습니다. 머신러닝은 크게 지도 학습, 비지도 학습, 강화 학습 3가지 유형으로 구분할 수 있습니다.
1. 지도 학습(Supervised Learning)
지도 학습은 기존에 이미 분류된 학습용 데이터(Labeled data)가 필요합니다. 알고리즘을 통해 입력 데이터와 정답을 매핑시키는 함수를 찾을 수 있습니다. 이렇게 추론된 함수는 학습 데이터를 기반으로 일반화하여 새로운 결과들을 예측하게 됩니다.
<대표적인 문제>
- 회귀(Regression) : 연속적인 값을 예측하는 문제를 회귀라고 합니다.
- 분류(Classification) : 범주형(Categorical) 데이터를 예측하는 문제를 분류라고 합니다. 레이블이 두 개인 경우를 ‘이진 분류(binary classificaiton)’, 두 개 이상인 경우를 ‘다중 클래스 분류(Multi-class classification)’이라고 합니다.
ML101에서는 지도 학습과 관련하여 4가지(Linear & Logistic Regression, Neural Networks, Support Vector Machine, Recommender System)에 대하여 학습해 보도록 하겠습니다.
2. 비지도 학습(Unsupervised Learning)
비지도 학습은 지도 학습과 달리 미분류된 데이터(Data without labels)를 사용하며, 학습을 통해 데이터의 기저를 이루는 패턴을 발견하도록 합니다.
<대표적인 문제>
- 클러스터링(Clustering) : 특정 기준에 따라 유사한 데이터들을 그룹화합니다. 주로 전체 데이터 세트를 여러 그룹으로 분류하기 위해서 사용합니다.
- 차원 축소(Dimension Reduction) : 변수의 개수를 줄이는 작업으로 차원수를 줄임으로써 잠재된 관계 혹은 의미를 도출해 낼 수 있습니다.
지도 학습과 마찬가지로 Clustering, Dimension Reduction, Anomaly Detection을 통해 ML101에서는 비지도 학습을 자세히 다루도록 하겠습니다.
3. 강화 학습(Reinforcement Learning)
강화 학습은 앞서 소개한 지도 학습 & 비지도 학습과는 조금 다른 접근을 하게 됩니다. 앞의 두 가지 유형은 Data를 고정된 환경에서 학습을 했다면, 강화 학습은 환경(Environment)으로부터 최고의 보상(Reward)을 얻을 수 있는 행동(Action)을 발견하기 위해 다양한 액션을 시도합니다. 학습을 위한 시행착오(Trial and error)와 보상(Reward)은 다른 학습 방법과 구별되는 특징입니다.
ML101에서는 강화 학습과 관련하여 3가지 주제인 Reinforcement Learning, Genetic Algorithm, Bayesian Learning을 통해 이해를 도울 수 있도록 하겠습니다.
머신러닝 유형에서 잠시 언급했던 ML101의 주제들에 대해서 Preview를 통해 간략히 소개하겠습니다.
# Preview 01 - Linear & Logistic Regression
회귀 분석은 기본적인 통계 기법인 만큼 아마 많이 들어보셨을 겁니다.
Linear & Logistic Regression 은 독립 변수(Indepentdent variable)를 통해 종속 변수(Dependent variable)를 예측하는 모델링 기법으로 주로 변수간 인과관계를 예측할 때 많이 사용됩니다. 한 지역의 재산세율, 범죄율, 학생별 교사 비율 등을 통해 해당 지역의 집값을 예측하는 모델이 회귀분석 모델의 예시가 될 수 있겠습니다.
회귀 분석은 크게 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) 두 가지 기법으로 구분을 합니다.
- 선형 회귀: 종속변수와 독립변수들 간의 선형 관계를 예측하는 기법으로 독립변수의 개수에 따라 단일 회귀, 다중 회귀(Multiple Linear Regression)로 나눌 수 있습니다. 방의 개수에 따른 주택 가격을 예측하면 단일 회귀, 방의 개수와 창문의 개수에 따른 주택 가격을 예측하면 다중회귀라고 할 수 있겠죠.
- 로지스틱 회귀: 예측하고자 하는 종속 변수가 특정 범주에 속할 확률(0~1 사이 값)을 예측하는 모델로 종속변수가 이항 분포(Bernoulli Distribution)를 따르는 범주형 데이터라는 점이 선형 회귀와 구분되는 점입니다. 방금 도착한 메일이 스팸메일이냐 아니냐 구분할 때 사용할 수 있는 모델입니다.
회귀 분석 모델은 ML 101 시리즈의 첫 모델로 소개할 예정이니 더 깊은 내용은 다음 글을 확인해 주시기 바랍니다.
# Preview 02 - Clustering
군집화 기법(Clustering)은 비지도 학습(Unsupervised learning)의 대표적인 사례로 언급되었던 것과 같이 각각의 데이터를 그룹화하는 기법이며, 대표적으로 네 가지 기법이 존재합니다.
- K-Means Clustering: 클러스터의 개수를 정하고, 모든 데이터 포인트를 무작위로 클러스터에 지정한 뒤, 각 데이터 포인트가 가장 가까운 중심(centroid, 각 클러스터의 데이터 포인트의 평균으로 계산)에 할당되도록 하는 기법. 작업 속도가 빠르지만 사전에 결정한 클러스터 개수와 무작위로 지정된 클러스터가 최적의 솔루션이라고 항상 장담할 수는 없다는 한계점이 있습니다.
- Mean-Shift Clustering: 데이터 포인트와 Centroid 간의 거리 중심인 K-Means와 달리 데이터 포인트들의 밀도가 높은 곳으로 centroid를 이동하며 군집화 하는 기법입니다. 데이터에 따라 적합한 클러스터 개수를 지정하는 대표적인 비모수 기법으로 비교적 알고리즘 수행 시간이 오래 걸리지만, 미리 군집 개수를 정해야 하는 K-Means 기법의 한계점을 보완한 기법입니다.
- DBSCAN(Density-based Spatial Clustering of Applications with Noise): 밀도기반 클러스터링(DBSCAN)으로 Mean-Shift와 유사하지만 각 데이터 포인터 간 유사도를 구분한다는 점에 있어서 차별점을 갖는 알고리즘입니다.
- EM Clustering using Gaussian Mixture: 평균만 고려하는 K-means와 달리 분산을 활용하여 보다 유연한 형태의 클러스터를 형성할 수 있으나 K-means와 마찬가지로 클러스터 개수를 미리 설정해야 한다는 한계점이 있습니다.
# Preview 03 - Reinforcement Learning
글 도입부에 잠시 언급되었던 알파고의 핵심적인 알고리즘입니다. 에이전트가 현 상태에서 선택 가능한 다양한 행동 중 보상(Reward)을 최대화하는, 최적의 행동 양식을 선택하도록 학습하는 알고리즘입니다. 즉, 지금 어떤 선택을 해야 가장 좋은지를 학습하는 것입니다. 여기서 중요한 핵심 중 하나는 당장의 보상값이 큰 행동이 아니라 전체 보상값의 총합을 최대화하는 행동을 선택하도록 학습되어야 한다는 것입니다. 이를 위해 지연된 보상(Delayed Reward)을 잘 인지할 수 있도록 설계하는 것이 중요합니다.
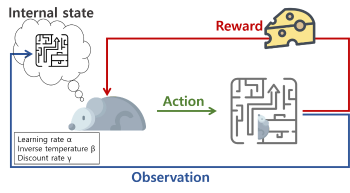
각 상태에서 에이전트가 선택한 행동은 그다음 상태에 영향을 끼치고, 현재까지의 경험 중 현 상태에서 최대의 보상을 얻을 수 있는 행동을 택하는 이용(Exploitation)과 다양한 경험 축적을 위해 새로운 시도를 하는 탐험(Exploration) 간 균형을 잘 맞추는 것 또한 강화 학습의 핵심입니다.
# Preview 04 - Neural Networks
이름에서부터 알 수 있듯이 사람 뇌에 있는 신경세포의 신호전달 과정을 모방하여 구성한 네트워크입니다. 사람의 뇌의 뉴런들이 특정 임계값(Threshold) 이상의 자극을 받으면 결과 신호를 전달하듯 Input data를 받으면 가중치(Weight)에 따라 Output data를 출력한다는 구조입니다.
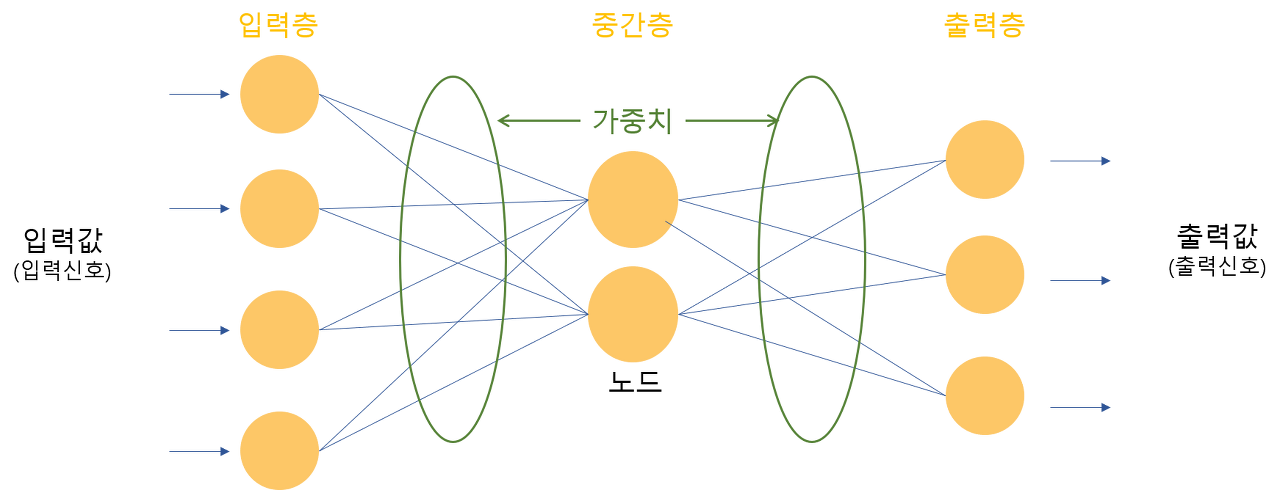
Neural Network는 다양한 응용 알고리즘이 존재하는데 가장 대표적인 것이 순환 신경망(RNN)과 합성곱 신경망(CNN)입니다.
- 순환 신경망(RNN, Recurrent Neural Network): 이전에 입력된 데이터를 순환 연결을 통해 다시 입력되게 함으로써 ANN에 시간을 구현한 모델입니다. 시간 순서가 반영됨에 따라 시계열 데이터 학습이 가능하며 RNN을 응용한 모델 사례로는 구글 번역기와 네이버의 파파고가 있습니다.
- 합성곱 신경망(CNN, Convolutional Neural Network): 필터링 기법을 인공신경망에 적용하여 이미지 분류에 많이 활용되는 알고리즘입니다. 서로 다른 두 사진의 특징을 추출하여 하나의 사진으로 합성하는 구글의 Deep Dream 서비스를 예시로 들 수 있겠습니다.
[ML101- Deep Neural Networks]에서 인공신경망의 기본 구조인 퍼셉트론(Perceptron)부터 응용 알고리즘까지 더 자세히 살펴보도록 하겠습니다.
# Preview 05 - Genetic Algorithm
유전 알고리즘(Genetic Algorithm)은 생물의 진화를 모방하여 최적해를 찾아내는 알고리즘입니다. 사실 알고리즘이라기보다는 최적화 문제를 푸는 방법론에 가깝습니다. A라는 사람이 서울에서 출발해 광주, 대전, 부산, 대구를 한 번 씩 방문하려 할 때, 한 번 간 곳은 가지 않으면서 가장 짧은 거리로 돌아올 수 있는 방법을 구하라는 문제(TSP, Traveling Salesman Problem)를 푸는 수많은 방법 중 가장 적은 비용으로 최적에 가까운 답을 낼 수 있는 방법이라고 할 수 있습니다.
생물의 진화를 모방한다는 유전 알고리즘의 전반적인 Flow는 다음과 같습니다.
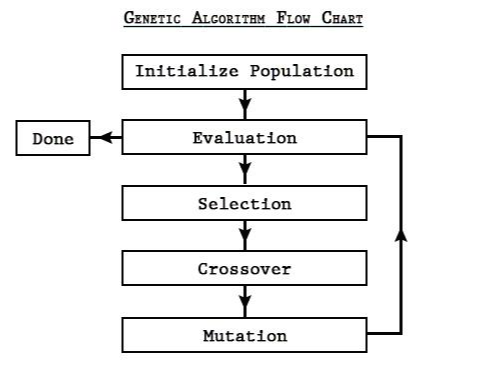
(1) 초기 집합 설정(Initialization) → (2) 적합도 평가(Fitness Assignment) → (3) 부모 선택(Selection) → (4) 교차(Crossover) → (5) 변이(Mutation)
'생존에 적합한 유전자를 지닌 개체만이 살아남아 번식을 하며, 그 자손 세대는 부모세대의 유전자(Crossover)와 돌연변이(Mutation)로 이루어져 번식을 거듭할수록 최적의 유전자만이 남는다'는 적자생존의 법칙이 크게 관통하고 있다고 할 수 있습니다.
각 단계별로 위 법칙을 어떻게 해결해내는지는 [ML 101 - Genetic Algorithm]에서 예시와 함께 풀어내도록 하겠습니다.
# Preview 06 - Bayesian Learning
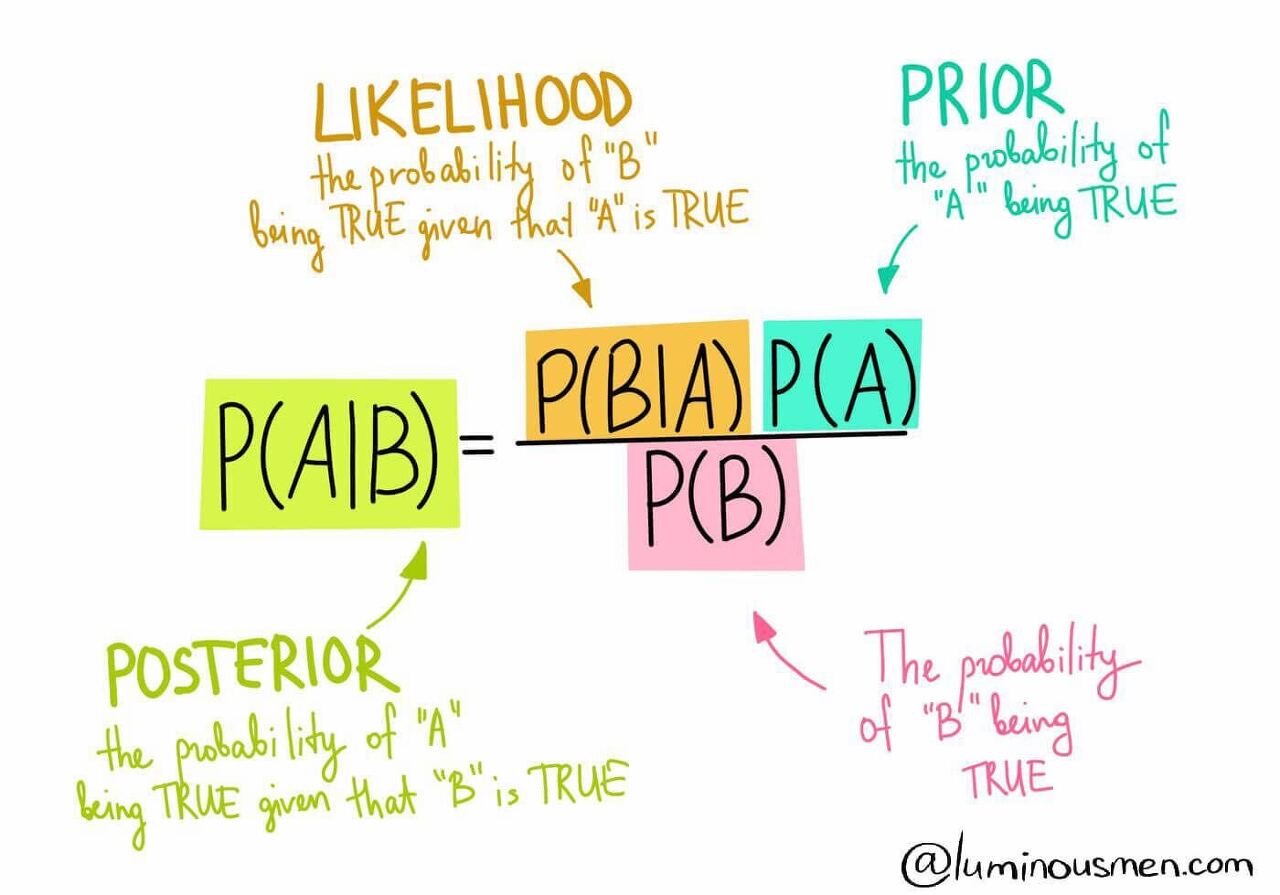
Probabilistic decision making process Bayesian은 기본적으로 확률(Probabilistic)과 관련이 있습니다. Bayesian Learning의 기본이 되는 Bayes Rule에 대해 먼저 살펴보겠습니다.
- Posterior : 정보 혹은 단서가 주어졌을 때, 대상이 클래스에 속할 확률 (최종적으로 구해야 하는 값)
- Likelihood : 각 클래스에서 우리가 활용할 단서가 어떤 형태로 분포되어 있는지 알려주는 정보
- Prior : 사전 정보로 주어지거나, 주어지지 않는다면 선수 지식을 통해 정해줘야 하는 값
Bayesian Learning의 핵심은 데이터와 단서(Evidence)가 많아질수록 지식이 업데이트되고 향상되는 것에 있습니다. 즉, P(model)라는 prior를 알고 있는데 새로운 data가 관측되면 posterior(P(model|data))를 얻고 이를 다음번 학습의 prior로 사용하면서 점진적으로 P(model)의 분포를 찾는 것이 Bayesian Learning의 과정입니다.
이를 사용하는 이유는 정답뿐만 아니라 정답이 어느 값일 확률이 높은지에 대한 분포(Distribution)를 얻을 수 있다는 것입니다. 이에 대한 이점은 결과가 믿을 만 한지, 얼마나 확실한지에 대한 Uncertainty를 알 수 있다는 점입니다. 중요한 개념들이기 때문에 다음에 더 자세하게 다루도록 하겠습니다.
# Preview 07 - Support Vector Machine
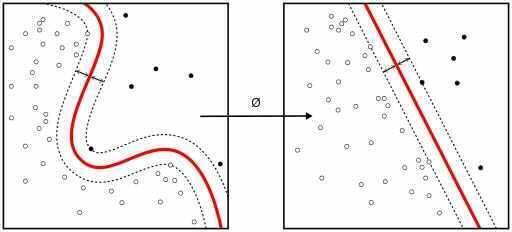
Support Vector Machine(SVM)은 머신러닝 지도 학습의 분류 문제를 해결하기 위한 대표적인 알고리즘입니다. 이름에서 유추할 수 있듯이 서포트 벡터라는 것들이 분류를 도와주게 됩니다. 서포트 벡터는 두꺼운 경계선을 만드는데 도움을 주게 되는데 이를 결정 경계(Decision Boundary)라고 합니다. 이러한 결정 경계는 차원이 높아질수록 선에서 평면, 그리고 고차원에서는 초평면(Hyperplane)이라고 불리게 됩니다.
또한 SVM은 선형으로 결정 경계를 만들 수 없는 경우 커널(Kernel)이라는 트릭을 이용하여 해결할 수 있습니다. 이렇게 다양한 문제에 적용 가능한 SVM은 클래식한 머신러닝 알고리즘이지만, 지금의 딥러닝과 같이 한 시대를 휩쓸었던 정교하고 탄탄한 이론적 배경을 가지고 있는 알고리즘이기 때문에 여전히 매우 다양한 현장에서 활용 가능한 방법론입니다. 뒤에서 이어질 ML101 시리즈를 통해 조금 더 자세히, 하지만 쉽게 이해해 보도록 하겠습니다.
# Preview 08 - Dimensionality Reduction
차원 축소는 이름처럼 목적에 따라 데이터의 양을 줄이는 방법론입니다. 머신러닝에서는 차원의 저주(The Curse of dimensionality)라고 불리는 현상이 있습니다. 데이터 학습을 위해 차원이 증가하게 되면 오히려 성능이 저하되는 현상입니다. 이를 방지하기 위해 차원 축소를 하게 되는데 크게 Feature Selection과 Feature Extraction이라는 두 가지 방법이 있습니다. 여기서 feature란 하나의 차원(dimension)을 의미하며 데이터의 한 열(column)이라고 이해하시면 됩니다.
- Feature Selection :
말 그대로 feature를 선택하여 뽑는 것을 의미합니다. 원래 데이터들로부터 중요한 몇 개의 feature들로 데이터를 다시 구성하는 것입니다. 이를 수행하기 위해서 배경 지식을 사용하거나 선택 알고리즘을 사용해 feature를 골라낼 수 있습니다. - Feature Extraction :
Feature selection과 달리 원본 데이터들의 특징 조합으로 새로운 특징을 만들어 내는 것을 의미합니다. 즉, 압축을 통해 숨겨진 의미들을 발견해 내는 것이 그 목적이라 할 수 있겠습니다.
이렇게 차원을 축소하게 됨으로써 효율적인 학습을 할 수 있게 하고(Complexity 감소), 알고리즘의 안정적인(Robust) 결과를 도출할 수 있으며 모델을 간단하게 만들 수 있습니다.
# Preview 09 - Anomaly Detection
한국어로 이상 감지 또는 이상 징후 감지라고 하는 Anomaly detection은 “이상한 것을 찾는 것”입니다. 그렇다면 이상한 것이란 무엇일까요? 이상한 것이란 오류를 의미한다기보다는 전체 데이터 중 매우 작은 비율을 갖는 “skewed class”를 검출하는 것입니다.
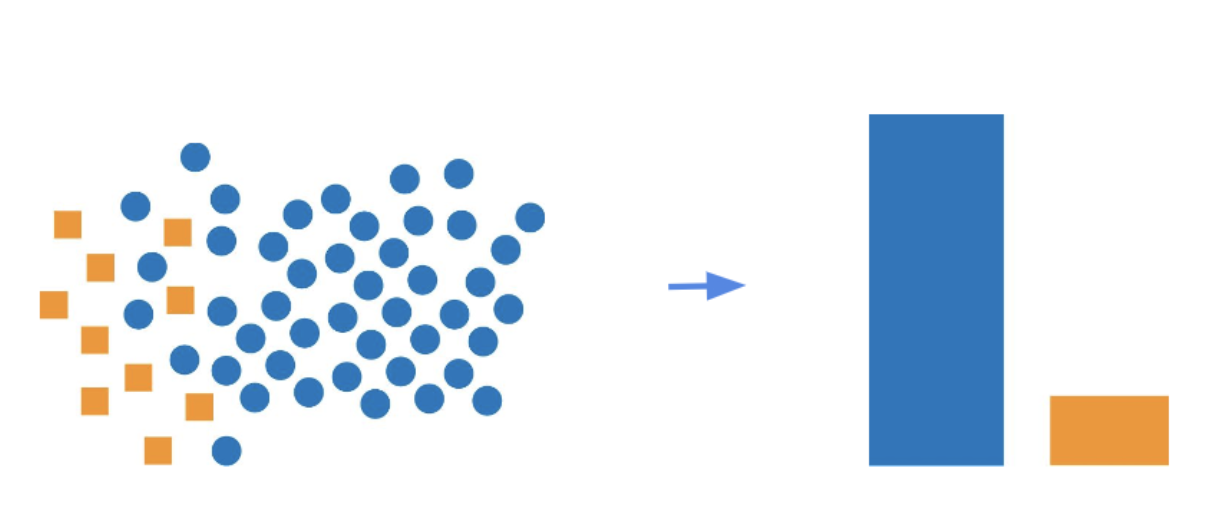
그렇다면 알고리즘은 우리가 입력한 데이터가 anomaly 한 데이터인지 어떻게 판단할까요? 이는 어떤 함수에 우리가 입력한 데이터가 정상적인 데이터일 가능성(Probability)을 계산해 특정 경곗값 보다 작을 때 anomaly로 판단합니다.
이러한 Anomaly Detection은 산업 전반에도 다양하게 활용되고 있습니다. 사이버 보안 영역에서 침입 혹은 악성 코드 탐지, 제조 영역에서 고장 및 결함 등을 예측, 금융 영역에서 불법 행위를 찾아내는 등 다양한 분야에 적용 및 시도되고 있습니다. 자세한 내용은 [ML101 - Anomaly Detection] 부분에서 다루도록 하겠습니다.
# Preview 10 - Recommender Systems
우리는 유튜브, 넷플릭스를 접하면서 추천 서비스를 받아 본 경험이 한 번씩은 있을 것입니다. 추천 시스템은 최근 학계뿐만 아니라 비즈니스 영역에서도 많은 관심을 받고 있습니다. 추천 시스템은 기계가 학습할 수 있는. 즉, 머신러닝의 분야로 보이지 않을 수 있는데, 머신러닝의 관점으로 보자면 일종의 예측 문제라고 볼 수 있습니다. 즉, 입력 데이터와 가장 유사할 것 같은 것을 예측하여 추천해 주고 적절한 피드백을 통해 성능을 개선하는 것입니다.
추천 시스템의 종류는 고전적인 연관성 규칙부터 콘텐츠 기반 필터링, 협업 필터링 등 다양한 알고리즘이 있으며 최근에는 하이브리드 방식과 머신러닝 기반의 추천 시스템 방식을 연구 및 도입하는 경향을 보이고 있습니다. 다양한 방법론들 중 절대적인 방법론은 없으며, 중요한 것은 “우리의 고객이 무엇을 원하는가?”를 이해하고 좋아할 만한 아이템을 가장 잘 추천해 줄 수 있는 방법론을 사용하는 것입니다.

[ML 101] 시리즈의 첫 시작으로 기본 개념과 구조, 알고리즘 유형을 살펴보았습니다. 다음 글부터는 몇 차례에 걸쳐 Regression 모델에 대해 더 깊고, 자세히 알아보도록 하겠습니다.
'AI Study > ML101' 카테고리의 다른 글
| [ML101] #5. Confusion matrix (0) | 2022.04.26 |
|---|---|
| [ML101] #4. Gradient descent (0) | 2022.04.26 |
| [ML101] #3. Loss Function (0) | 2022.04.26 |
| r[ML101] #2. Regression (0) | 2022.04.26 |
| [ML101] #0. Foreword (0) | 2022.04.25 |