[ML101] 시리즈의 두 번째 주제는 손실 함수(Loss Function)입니다. 손실 함수는 다른 명칭으로 비용 함수(Cost Function)이라고 불립니다.
손실 함수는 고등학교 수학 교과과정에 신설되는 '인공지능(AI) 수학' 과목에 포함되는 기계학습(머신러닝) 최적화의 기본 원리이며 기초적인 개념입니다. 이번 시리즈에는 이 "손실 함수"의 개념과 종류에 대해 알아보도록 하겠습니다.
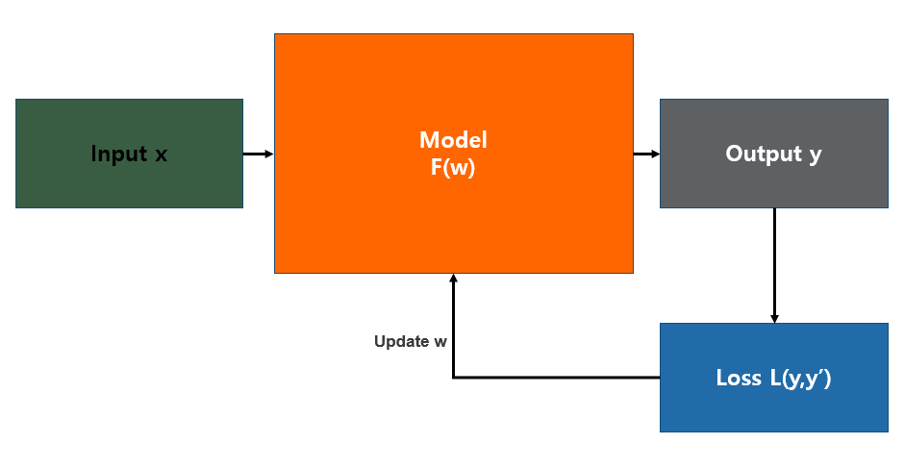
위의 그림은 일반적인 통계학적 모델의 형태로 입력 값(Input x)이 들어오면 모델을 통해 예측 값(Output y)이 산출되는 방식입니다. 그러면 이 예측 값이 실제 값과 얼마나 유사한지 판단하는 기준이 필요한데 그게 바로 손실 함수(Loss function)입니다. 예측 값과 실제 값의 차이를 loss라고 하며, 이 loss를 줄이는 방향으로 학습이 진행됩니다.
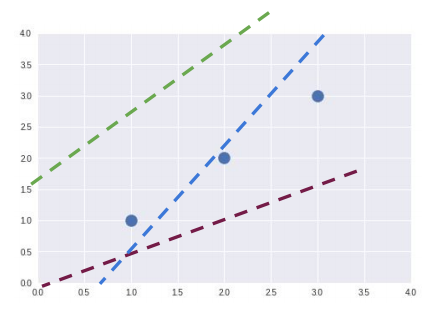
예를 들어, 위의 그림 중 파란색 점이 우리가 가지고 있는 데이터라고 가정해 봅시다. 데이터가 이렇게 분포되어있을 때, 파란색 점 전체를 잘 대변하는 직선은 어떤 모습일까요?
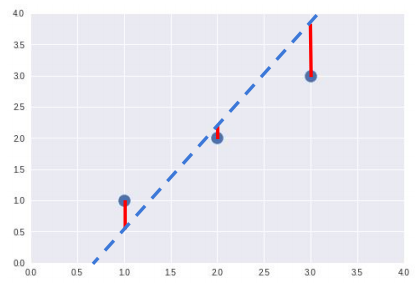
파란색 점 전체를 잘 대변하는 직선의 모습은 위의 그림에서 빨간 선(우리의 가설 직선과 실제 값의 차이)의 총합이 최소화됐을 경우일 겁니다. 손실 함수의 목적은 이 빨간 선들의 총합을 최소화하여 최적의 결괏값을 도출하는 것입니다.
그렇다면 이 손실 함수는 무엇을 의미하는 걸까요?
손실 함수는 데이터를 토대로 산출한 모델의 예측 값과 실제 값과의 차이를 표현하는 지표입니다. 조금 더 쉽게 설명하면, 손실 함수는 모델 성능의 '나쁨'을 나타내는 지표로, “현재의 모델이 데이터를 얼마나 잘 처리하지 못하느냐”를 나타내는 지표라고 할 수 있습니다. “얼마나 나쁘냐”를 어떤 방식으로 표현하느냐에 따라 여러 가지 손실 함수가 존재합니다.
통계학적 모델은 일반적으로 회귀(regression)와 분류(classification) 두 가지 종류로 나눠지는데, 손실 함수도 그에 따라 두 가지 종류로 나눠집니다. 회귀 타입에 쓰이는 대표적 손실 함수는 MAE, MSE, RMSE 가 있으며, 분류에 쓰이는 손실 함수는 Binary cross-entropy, Categorical cross-entropy 등이 있습니다. 다음은 언급된 손실 함수 종류와 각각의 특징에 대해서 설명하도록 하겠습니다.
회귀 타입에 사용되는 손실 함수는 대표적으로 평균 오차 계산법이 있으며, 평균 오차를 계산하는 방식(공식)에 따라 MAE, MSE, RMSE로 구분됩니다.
1. 평균 절대 오차 (Mean Absolute Error, MAE)
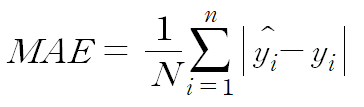
평균 절대 오차는 예측 값과 정답 값의 차이에 절댓값을 취하여, 그 값들을 전부 더하고, 개수로 나누어 평균을 낸 값입니다. 예측 결과와 정답 결과가 떨어진 정도의 절댓값을 평균 낸 것이기에, 전체 데이터의 학습된 정도를 쉽게 파악할 수 있습니다. 하지만, 절댓값을 취하기 때문에 해당 예측이 어떤 식으로 오차가 발생했는지, 음수인지 양수인지 판단할 수 없다는 단점이 있습니다. 또한 아래 그림처럼 최적 값에 가까워지더라도 이동거리가 일정하기 때문에 최적 값에 수렴하기 어렵습니다.
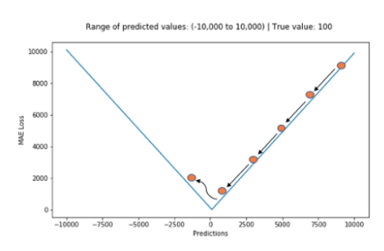
2. 평균 제곱 오차 (Mean Squared Error, MSE)
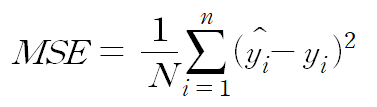
평균 제곱 오차는 가장 많이 쓰이는 손실 함수 중 하나이며, 예측 값과 실제 값 사이의 평균을 제곱하여 평균을 낸 값입니다. 차이가 커질수록 제곱 연산으로 인해 값이 뚜렷해지며 제곱으로 인해 오차가 양수이든 음수이든 누적 값을 증가시킵니다. MSE는 실제 정답에 대한 정답률의 오차뿐만 아니라 다른 오답들에 대한 정답률 오차 또한 포함하여 계산한다는 것이 특징입니다. MSE는 MAE와 달리 최적 값에 가까워질 경우 이동거리가 다르게 변화하기 때문에 최적 값에 수렴하기 용이합니다. MSE의 단점으로는 값을 제곱하기 때문에, "1 미만의 값은 더 작아지고, 그 이상의 값은 더 커진다”, 즉 값의 왜곡이 있을 수 있습니다.
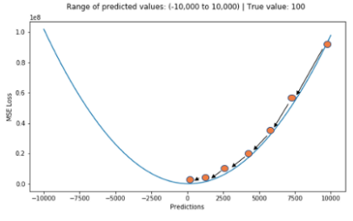
3. 평균 제곱근 오차(Root Mean Square Error, RMSE)
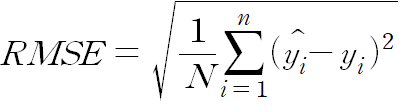
평균 제곱근 오차는 MSE에 루트를 씌운 지표로 장단점은 MSE와 유사한 형태로 이루어집니다. 하지만 제곱된 값에 루트를 씌우기 때문에 값을 제곱해서 생기는 왜곡이 줄어들며, 오차를 보다 직관적으로 보여줍니다. 그 이유는 루트를 씌워주기 때문에 오류 값을 실제 값과 유산한 단위로 변환하여 해석을 할 수 있기 때문입니다.
다음은 분류 타입에 사용되는 손실 함수에 대해서 설명하겠습니다. 분류 타입에 대표적으로 사용되는 손실 함수는 cross-entropy 방식이 있습니다.
그렇다면, 여기서 cross-entropy란 무엇을 의미하는 걸까요?
Cross-entropy는 실제 분포 q에 대하여 알지 못하는 상태에서, 모델링을 통하여 구한 분포인 p를 통하여 q를 예측하는 것입니다. 이때, q와 p가 모두 식에 들어가기 때문에, cross-entropy라는 이름이 생겼습니다.
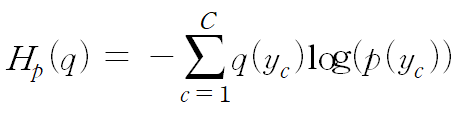
Cross-entropy에서 실제 값과 예측 값이 맞는 경우에는 0으로 수렴하고, 값이 틀릴 경우에는 값이 커지기 때문에, 실제 값과 예측 값의 차이를 줄이기 위한 방식이라고 이해하시면 됩니다. 하지만 이 Cross-entropy는 label의 값이 one-hot encoding일 경우에만 사용 가능합니다.
*One hot encoding: multinomial classification에서 사용하는 인코딩 방법으로 출력 값의 형태가 정답 label은 1이고 나머지 label 값은 모두 0 ex) [1,0,0], [0,1,0], [0,0,1]
그럼 구체적으로 Binary cross-entropy와 Categorical cross-entropy에 대해서 알아보도록 하겠습니다.
1. Binary cross-entropy
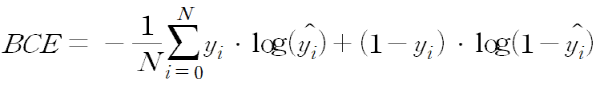
Binary cross-entropy는 이진 분류에 사용되는 방식입니다. 예를 들어, True 또는 False, 양성 또는 음성 등 2개의 class를 분류할 때 사용하는 방식으로 예측값이 0과 1 사이의 확률 값으로 나옵니다. 1에 가까우면 하나의 클래스(True or 양성) 일 확률이 큰 것이고, 0에 가까우면 다른 하나의 클래스(False or 음성) 일 확률이 큰 것입니다.
2. Categorical cross-entropy
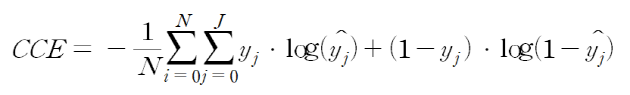
Categorical cross-entropy는 분류해야 할 클래스가 3개 이상인 경우, 즉 멀티클래스 분류에 사용됩니다. 라벨이 [0,0,1,0,0], [1,0,0,0,0], [0,0,0,1,0]과 같이 one-hot 형태로 제공될 때 사용됩니다. 일반적으로 예측 값은 [0.02 0.94 0.02 0.01 0.01]와 같은 식으로 나오기 때문에 여러 class 중 가장 적절한 하나의 class를 분류하는 문제의 손실 함수로 사용되기에 적합합니다.
지금까지 손실 함수의 개념과 종류에 대해 알아봤습니다. 다음 글에서는 경사 하강법(Gradient descent)에 대해 구체적으로 알아보겠습니다.
'AI Study > ML101' 카테고리의 다른 글
| [ML101] #5. Confusion matrix (0) | 2022.04.26 |
|---|---|
| [ML101] #4. Gradient descent (0) | 2022.04.26 |
| r[ML101] #2. Regression (0) | 2022.04.26 |
| [ML101] #1. Machine Learning? (0) | 2022.04.26 |
| [ML101] #0. Foreword (0) | 2022.04.25 |